
The term "templates" in the context of C ++ are usually understood as quite specific language constructs. There are simple templates that simplify working with the same type of code - these are templates of classes and functions. If a template has one of the parameters in itself is a template, then it can already be said to be second order templates and they are generated by other templates depending on their parameters. But what if their capabilities are not enough and it is easier to generate the source text immediately? Lots of source code?
Python lovers and HTML layouts are familiar with the tool (engine, library) for working with textual templates called
Jinja2 . At the entrance, this slider receives a template file in which text can be mixed with control structures, the output is pure text, in which all control structures are replaced with text in accordance with the parameters specified from the outside (or from the inside). Roughly speaking, this is something like ASP pages (or C ++ - preprocessor), only the markup language is different.
Until now, the implementation of this engine was only for Python. Now it is also for C ++. About how and why it happened, and will be discussed in the article.
Why did I even take it
Indeed, why? After all, there is Python, for it is an excellent implementation, a bunch of features, an integral specification for the language. Take it and use it! Do not like Python - you can take
Jinja2CppLight or
inja , partial Jinja2 ports in C ++. In the end, you can take C ++ - port {{
Mustache }}. The devil, as usual, in the details. Here, for example, I needed the functionality of filters from Jinja2 and the possibilities of the extends construction, which allows you to create extensible templates (and also include macros and include, but this later). And none of the mentioned implementations support this. Could I do without all this? Good question too. Judge for yourself. I have a
project whose goal is to create a C ++ - to-C ++ auto generator of boilerplate code. This generator generates, for example, a manually written header file with structures or enums and, based on it, generates serialization / deserialization functions or, say, converting enum elements into strings (and vice versa). More details about this utility can be heard in my reports
here (eng) or
here (rus).
So, a typical problem solved in the process of working on the utility is to create header files, each of which has a header (with ifdefs and include), a body with the main contents and a basement. And the main content is generated declarations pushed by namespaces. Executed in C ++, the code for creating such a header file looks like this (and this is not all):
A lot of C ++ codevoid Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } }
From here .
Moreover, this code varies little from file to file. Of course, you can use clang-format for formatting. But this does not negate the rest of the manual work on generating the source text.
And then at one point, I realized that life itself should be simplified. I did not consider the option of screwing a full-fledged scripting language due to the difficulty of supporting the final result. But to find a suitable template engine - and why not? It is useful to search, found, then found the specification for Jinja2 and realized that this is exactly what I need. For according to this spec, the templates for generating headers would look like this:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}
From here .

There was only one problem: none of the engines I found supported the whole set of features I needed. Well, of course, everyone had a standard
fatal flaw . I thought a little and decided that the world would not get much worse from just one implementation of the template engine. Moreover, according to estimates, the basic functionality was not very difficult to implement. After all, now in C ++ there are regexps!
And so the
Jinja2Cpp project
appeared . I almost guessed about the complexity of implementing the basic (very basic) functionality. In general, I missed exactly the Pi coefficient in the square: it took me less than three months to write everything I needed. But when everything was finished, finished and inserted into the “Auto Programmer” - I realized that I tried not in vain. In fact, the code generation utility received a powerful scripting language combined with templates, which opened up completely new opportunities for development.
NB: I had a thought to screw Python (or Lua). But none of the existing full-fledged script engines does not solve “out of the box” questions on generating text from templates. That is, the Python would still have to screw the same Jinja2, and for Lua to look for something different. Why did I need this extra link?
Parser implementation
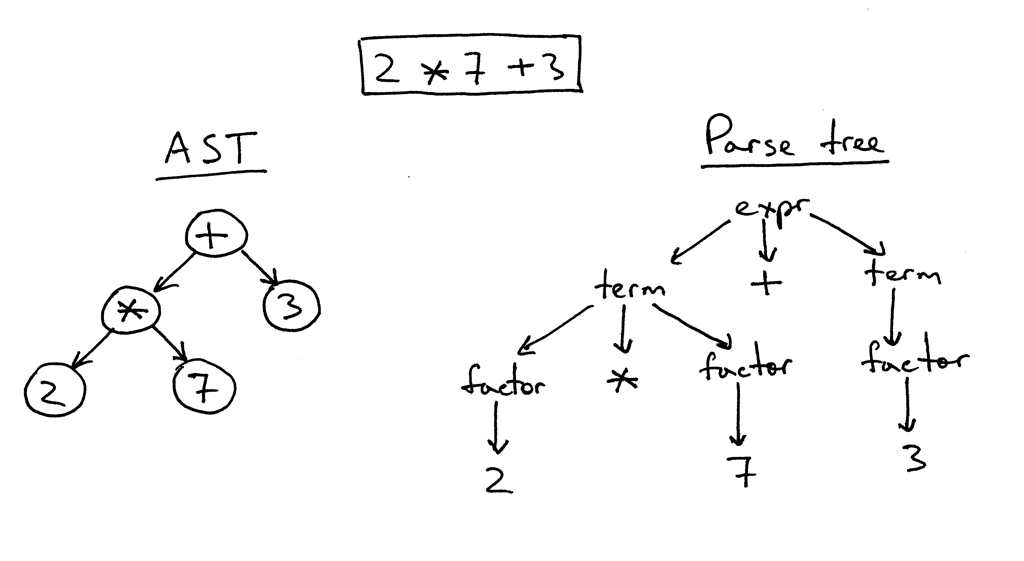
The idea of the structure of Jinja2 templates is quite simple. If there is something in the text that is enclosed in a pair of "{{" / "}}" - then this "something" is an expression that must be calculated, transformed into a textual representation and inserted into the final result. Inside the pair "{%" / "%}" are operators of the type for, if, set, etc. But in "{#" / "#}" there are comments. Having studied the implementation of Jinja2CppLight, I decided that trying to manually find all these control structures in the template text is not a good idea. So I armed myself with a rather simple regexp: (((\ {\ {) | (\} \}) | (\ {%) | (% \}) | (\ {#) | (# \}) | (\ n)), with which he beat the text on the desired fragments. And called it the rough phase of parsing. At the initial stage of the work, the idea showed its effectiveness (yes, in fact, it still shows), but, in an amicable way, in the future it will need to be refactored, since now there are some minor restrictions on the template text: screening pairs "{{" and "}}" in the text is processed too "in the forehead."
In the second phase, only what was inside the brackets is parsed in detail. And here it was necessary to tinker. That inja, that in Jinja2CppLight, the expression parser is pretty simple. In the first case - on the same regexp'ah, in the second - handwritten, but supporting only very simple constructions. About the support of filters, testers, complex arithmetic or indexing there is not even talk. Namely, these features of Jinja2 were what I wanted most of all. Therefore, I had no choice but to attack a full-fledged LL (1) -parser (sometimes context-sensitive) that implements the necessary grammar. About ten to fifteen years ago, I would probably take a Bison or ANTLR for this and implement the parser with their help. About seven years ago I would try Boost.Spirit. Now, I just implemented the necessary parser that works by the method of recursive descent, without causing unnecessary dependencies and a significant increase in compile time, as it would have happened if using external utilities or Boost.Spirit. At the output of the parser, I get an AST (for expressions or for operators), which is stored as a template, ready for later rendering.
Example of expression parsing logic ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
From here .
Fragment of classes of AST-expression tree class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
From here .
An example of classes of AST-tree operators struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; };
From here .
AST nodes are bound only to the template text and are converted to totals at the time of rendering, taking into account the current rendering context and its parameters. This made it possible to make thread-safe templates. But more about this in the part concerning the actual rendering.
As the primary tokenizer, I chose the
lexertk library. It has the license and header-only I need. It was necessary, however, to cut off all the bells and whistles by calculating the balance of brackets and so on, and leave only the tokenizer itself, which (after a small file straightening) learned to work not only with char, but also with wchar_t-characters. From above, this tokenizer was wrapped by another class that performs three main functions: a) abstracts the parser code from the type of characters being worked with, b) recognizes keywords specific to Jinja2 and c) provides a convenient interface for working with the stream of tokens:
Lexscanner class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };
From here .
Thus, despite the fact that the engine can work with both char and wchar_t templates, the main parsing code does not depend on the character type. But more about this - in the section on adventure with the type of characters.
Separately, had to tinker with the control structures. In Jinja2, many of them are steam rooms. For example, for / endfor, if / endif, block / endblock, etc. Each element of the pair goes in its “brackets”, and there can be a lot of elements between the elements: just text, and other control blocks. Therefore, the template parsing algorithm had to be done on the basis of the stack, to the current top element of which all newly found constructions and instructions, as well as simple text fragments between them, “cling”. By the same stack, the absence of imbalance of the if-for-endif-endfor type is checked. As a result of all this, the code is not as compact as, say, Jinja2CppLight (or inja), where the entire implementation is in the same source code (or header). But the parsing logic and, in fact, the grammar in the code are more clearly visible, which simplifies its support and expansion. At least that's what I wanted. Minimizing the number of dependencies or the amount of code still does not work, so you need to make it more understandable.
The
next part will discuss the process of rendering templates, but for now - links:
Jinja2 Specification:
http://jinja.pocoo.org/docs/2.10/templates/Jinja2Cpp implementation:
https://github.com/flexferrum/Jinja2CppJinja2CppLight implementation:
https://github.com/hughperkins/Jinja2CppLightImplementation of inja:
https://github.com/pantor/injaA utility for generating code based on Jinja2 templates:
https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor