Hello! In this article I will talk about the Bayes classifier, as one of the options for filtering spam emails. Let's go through the theory, then we fix it with practice, well, and at the end I will provide my sketch of the code in my adored R. language. I will try to present as easy as possible expressions and formulations. Let's get started!

Without formulas anywhere, well, a brief theory
Bayesian classifier belongs to the category of machine learning. The essence is this: the system, which is faced with the task of determining whether the next letter is spam, is pre-trained by some number of letters exactly known where "spam" and where "not spam". It has already become clear that this is training with a teacher, where we act as a teacher. The Bayesian classifier presents a document (in our case, a letter) in the form of a set of words that are supposedly independent of each other (this is the naivety from here).
It is necessary to calculate the grade for each class (spam / not spam) and choose the one that turned out to be the maximum. To do this, use the following formula:
- occurrence of the word
in class document
(with smoothing) *
- the number of words included in the document class
M - the number of words from the training set
- the number of occurrences of the word
in class document
- parameter for smoothing
When the amount of text is very large, you have to work with very small numbers. In order to avoid this, you can convert the formula by the logarithm property **:
Substitute and get:
* During the calculation, you may encounter a word that was not at the stage of learning the system. This can lead to the fact that the assessment will be equal to zero and the document can not be attributed to any of the categories (spam / not spam). No matter how you want, you will not teach your system all the possible words. To do this, you need to apply anti-aliasing, or rather, to make small corrections in all the probabilities of words entering the document. The parameter 0 <α≤1 is selected (if α = 1, then this is Laplace smoothing)
** Logarithm is a monotonically increasing function. As can be seen from the first formula - we are looking for a maximum. The logarithm of the function will reach a maximum at the same point (on the x-axis) as the function itself. This simplifies the calculation, since only the numerical value changes.
From theory to practice
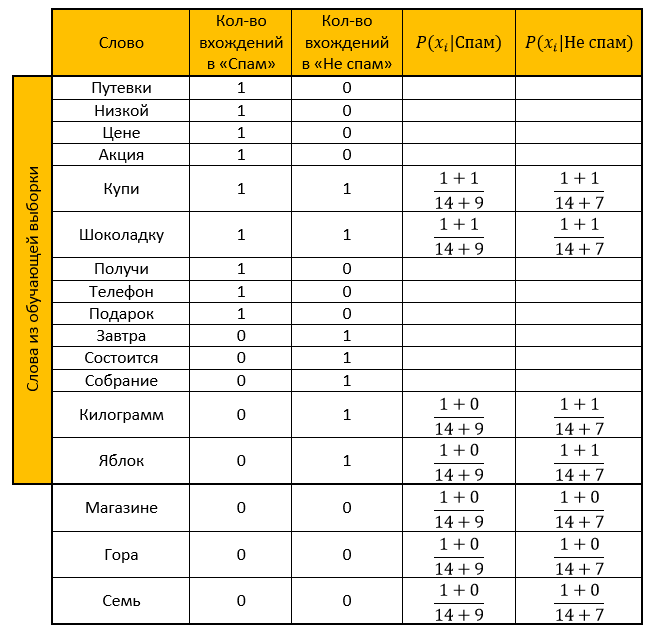
Let our system learn from the following letters, which are known in advance where “spam” and where “not spam” (training set):
Spam:- “Vouchers at a low price”
- "Stock! Buy a chocolate bar and get a phone as a gift »
Do not spam:- "Tomorrow will be a meeting"
- "Buy a kilo of apples and a chocolate bar"
Task: determine which category the following letter belongs to:
- “There is a mountain of apples in the store. Buy seven kilograms and chocolate "
Decision:We make the table. We remove all the "stop words", we calculate the probabilities, the parameter for smoothing is taken as one.
Score for the category "Spam":
Rating for the category "Not spam":
Answer: “Not Spam” rating is more than “Spam” rating. So the verification letter is not spam!
The same is calculated using the function transformed by the logarithm property:
Score for the category "Spam":
Rating for the category "Not spam":
Answer: similar to the previous answer. Verification letter - not spam!
Implementation in the R programming language
I commented on almost every action of my own, for I know how sometimes I don’t want to understand someone else’s code, so I hope reading mine will not cause you any difficulty. (oh, how I hope)
And here, in fact, the code itselflibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
Thank you very much for taking the time to read my article. I hope you have learned something new for yourself, or just shed light on the moments that are incomprehensible to you. Good luck!
Sources:- Very good article on the naive Beyes classifier
- Drew knowledge from the Wiki: here , here , and here
- Lectures on Data Mining I. Chubukova