Machine vision is a very hot topic these days. To solve the problem of recognizing store price tags using neural networks, we chose the TensorFlow framework.
The article will talk about how to localize and identify several objects on one store price tag, as well as recognize its contents.
A similar problem of recognizing IKEA price tags has already been solved on Habré using classic image processing tools available in the OpenCV library.
Separately, I would like to note that the solution can work both on the SAP HANA platform in conjunction with Tensorflow Serving, and on the SAP Cloud Platform.
The task of recognizing the price of goods is also relevant for buyers who want to “fumble” prices with each other and choose a store for purchases, and for retailers - they want to learn about the prices of competitors in real time.
Enough lyrics - go to the technique!
ToolsFor image detection and classification, we used convolutional neural networks implemented in the TensorFlow library and accessible for management through the Object Detection API.
TensorFlow Object Detection API is an open source TensorFlow based metaframe that simplifies the creation, training and deployment of models for object detection.
After detecting the desired object, text recognition on it was performed using Tesseract, a library for character recognition. Since 2006, Tesseract is considered one of the most accurate OCR libraries available in open source.
It is possible that you ask the question - why not all the processing is done on TF? The answer is very simple - it would take much more time to implement, and it was not so much. It was easier to sacrifice processing speed and assemble a ready-made prototype than to bother with homemade OCR.
Creation and preparation datasetFor a start it was necessary to collect materials for work. We visited 3 stores and took about 400 photos of various price tags on a mobile phone camera in automatic mode.
Sample photos: Fig. 1. An example of the image of the price tag
Fig. 1. An example of the image of the price tag Fig. 2. An example of the image of the price tag
Fig. 2. An example of the image of the price tagAfter you need all the photos of the price tags to process and mark. In the process of collecting images, we tried to collect high-quality images (without artifacts): price tags of approximately the same format, without blurring, significant turns, etc. This was done to facilitate further comparison of the content on the real price tag and its digital image. However, if the neural network is trained only on the available high-quality images, it will quite naturally lead to the fact that the model's confidence in identifying distorted examples will drop significantly. To train the neural network to be resistant to such situations, we used the well-known procedure for expanding the training set with distorted image variants (augmentation). To supplement the training sample, we applied the algorithms from the Imgaug library: shifts, small turns, Gaussian blur, noise. Distorted images were added to the sample, which increased it about 5 times (from 300 to 1500 images).
The program LabelImg, which is freely available, was used to mark up the image and select the objects. It allows you to select the necessary objects in the image by a rectangle and assign a necessary class to each bounding box. All coordinates and labels of the created frames for each photo are saved in a separate XML file.
The following objects were distinguished in each photograph: product price tag, product price, product name, and product barcode on the price tag. In some examples of images where this was logically justified, areas were marked with overlapping.
 Fig. 3. An example of a photograph of a pair of price tags, marked in LabelImg. Areas with product description, price and barcode are highlighted.
Fig. 3. An example of a photograph of a pair of price tags, marked in LabelImg. Areas with product description, price and barcode are highlighted. Fig. 4. An example of a photo of the price tag, marked in LabelImg. Areas with product description, price and barcode are highlighted.
Fig. 4. An example of a photo of the price tag, marked in LabelImg. Areas with product description, price and barcode are highlighted.After all the photos are processed and laid out, we prepare the datasets with the separation of all the photos and tag files into a training and test sample. Usually take 80% of the training sample to 20% of the test sample and mix randomly.
Next, on the machine where the model will be trained, it is necessary to install all the necessary libraries. First of all, install the TensorFlow machine learning library. Depending on the type of your system and you need to install an additional library for computing on the GPU. Next, install the Tensorflow Object Detection API library and additional libraries for working with images and graphs. Below is a list of libraries that we used in our work:
TensorFlow-GPU v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Pillow 1.0, lxml, tf Slim, Jupyter notebook, Matplotlib
Tensorflow, Cython, Cocoapi; Opencv-python; PandasWhen all the installation steps have been completed, you can proceed to data preparation and customization of training parameters.
Model trainingTo solve our problem, we used two variants of the pre-trained neural network MobileNet V2 and Faster-RCNN V2 on coco dataset as extractors of image properties. The models were extended to 4 new classes: price tag, product description, price, barcode. We chose MobileNet V2 as the main one, which is a relatively simple model that allows us to provide acceptable quality at a pleasant speed. MobileNet V2 allows image recognition even on a mobile device.
First you need to specify the Tensorflow Object Detection API library the number of tags, as well as the names of these tags.
The last thing to do before learning is to create a shortcut map and edit the configuration file. The label map reports models and associates class names with class identifier numbers for each object.

Finally, you need to configure training sources for Object Detection to determine which model and which parameters will be used for training. This is the last step before starting the training.

The learning procedure is started with the command:
python train.py
If everything is configured correctly, TensorFlow initializes the additional training of the neural network. Initialization can take up to 30 seconds before the start of the actual training. As the neural network is further trained, the value of the error function of the algorithm (loss) will be displayed at each step. For MobileNet V2, the initial value of the loss function is about 20. The model should be trained until the loss function decreases to about 2. To visualize the learning process of the neural network, you can use the convenient TensorBoard utility.
: tensorboard
The command initializes the web interface on the local machine, which will be available at localhost: 6006. After stopping, the learning procedure can be resumed later, using checkpoints, which are saved every 5 minutes.
Recognition of price tags and its elementsWhen training is complete, the final step is to create a neural network graph. This is done by the console command, where under the asterisks you need to specify the highest cpkt-file number that exists in the training directory.
python export_inference_graph.py
After this procedure, the object detection classifier is ready for operation. To check the image recognition, it is enough to run a script that comes with the Tensorflow Object Detection library with an indication of the model that was previously trained, and photos for recognition. A standard Python script example is provided
by reference .
In our example, it takes about 1.5 seconds to recognize one photo by the ssd mobilenet model on a simple laptop.
 Fig. 5. The result of image recognition with price tags in the test sample
Fig. 5. The result of image recognition with price tags in the test sample Fig. 6. The result of image recognition with price tags in the test sample
Fig. 6. The result of image recognition with price tags in the test sampleWhen we are convinced that the price tags are normally detected, it is necessary to teach the model to read information from individual elements: the price of the goods, the name of the goods, the bar code. To do this, there are libraries available in Python for recognizing symbols and barcodes in photos - Pyzbar and Tesseract.
Before you begin to recognize the symbols and barcodes in the photo, you need to cut this photo into the elements we need - in order to increase speed and not recognize extra information that is not included in the price tag. It is also necessary to “pull out” the coordinates of the objects that the model recognized along with their classes.

Then we use these coordinates to cut our photo into pieces to recognize only the required area.


 Fig. 7. Example of selected parts of the price tag
Fig. 7. Example of selected parts of the price tagNext, all the cut areas are transferred to the libraries: the name of the product and the price of the product are transferred to tesseract, and the barcode is sent to pyzbar, and we get the result of recognition.

 Fig. 8. Example of recognized content price tag area.
Fig. 8. Example of recognized content price tag area.At this stage, problems with text and barcode recognition may arise if the original image was low resolution or blurred. If the price can be recognized normally due to large numbers on the price tag, then the product name and barcode will be determined poorly or not determined at all. To do this, it is recommended not to use small photos for recognition, as well as to upload images without noise and strong distortion - for example, without the lack of proper focus.
An example of bad image recognition:



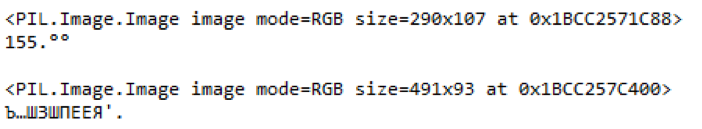 Fig. 9. An example of selected portions of a blurred price tag and recognized content.
Fig. 9. An example of selected portions of a blurred price tag and recognized content.In this example, you can see that if the price of the product was recognized more or less correctly on the image of poor quality, the library could not cope with the name of the product. A barcode is not recognizable at all.
The same text in good quality.

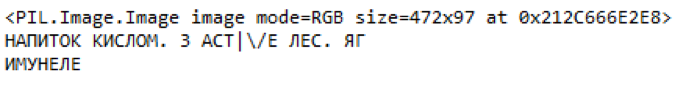 Fig. 10. An example of selected parts of the price tag and recognized content.findings
Fig. 10. An example of selected parts of the price tag and recognized content.findingsIn the end, we managed to get a model of acceptable quality with a low percentage of errors and a high percentage of detection of relevant objects. Faster-RCNN Inception V2 has a better recognition quality than the MobileNet SSD V2, but about an order of magnitude inferior in speed, which is a significant limitation.
The obtained recognition accuracy of the price tag on a deferred sample of 50 images is 100%, that is, all price tags have been successfully identified in all photos. Accuracy of recognition of areas with a bar code and price was 90%. The accuracy of the recognition of the text area - 85%. The accuracy of reading the price was about 95%, and the text - 80-85%. Additionally, as an experiment, we give the result of recognition of the price tag, which is completely different from the price tags in the training set.
 Fig. 11. An example of recognition of atypical price tags that are missing in the training set.
Fig. 11. An example of recognition of atypical price tags that are missing in the training set.As you can see, even with price tags that are significantly different from price tags in training, the model is not without errors, but it is possible to recognize significant objects on the price tag.
What else could be done?1) A cool article about automatic augmentation has recently been published, the approach of which can be used.
2) Finished trained model can and should be significantly reduced
3) Examples of publishing ready-made services in SCP and TFS
In preparing the prototype and this article, the following materials were used:1.
Bringing Machine Learning (TensorFlow) for SAP HANA2.
SAP Leonardo ML Foundation - Bring Your Own Model (BYOM)3.
GitHub-repository TensorFlow Object Detection4.
Article on the recognition of IKEA checks5.
Article on the advantages of MobileNet6.
Article about TensorFlow Object DetectionThe article was prepared by:
Sergey Abdurakipov, Dmitry Buslov, Alexey Khristenko