There are more than 630 million sites on the modern Internet, but only 6% of them contain Russian-language content. The language barrier is the main problem of the dissemination of knowledge between network users, and we believe that it needs to be solved not only by teaching foreign languages, but also using automatic machine translation in the browser.
Today we will tell Habr's readers about two important technological changes in the translator Yandex. Browser. First, the translation of the selected words and phrases now uses a hybrid model, and we recall how this approach differs from the use of neural networks only. Secondly, the neural networks of the translator now take into account the structure of web pages, the features of which we also tell under the cut.
Hybrid Word and Phrase Translator
The first machine translation systems were based on
dictionaries and rules (in fact, hand-written regulars), which determined the quality of translation. Over the years, professional linguists have worked to derive more and more detailed manual rules. This work was so laborious that serious attention was paid only to the most popular pairs of languages, but even within the framework of these machines the machines coped poorly. Living language is a very complex system, which poorly obeys the rules. It is even more difficult to describe the rules for the correspondence of two languages.
The only way for a machine to constantly adapt to changing conditions is to study independently on a large number of parallel texts (identical in meaning, but written in different languages). This is a statistical approach to machine translation. The computer compares parallel texts and independently reveals patterns.
The
statistical translator has both advantages and disadvantages. On the one hand, he remembers rare and complex words and phrases well. If they are met in parallel texts, the translator will remember them and will continue to translate correctly. On the other hand, the result of the translation is similar to the assembled puzzle: the overall picture seems to be understandable, but if you look closely, you can see that it is composed of individual pieces. The reason is that the translator represents individual words as identifiers that do not reflect the relationship between them. This does not correspond to how people perceive language, when words are defined by how they are used, how they relate to other words and how they differ from them.
Neural networks help solve this problem. The word word representation (word embedding) used in neural machine translation, as a rule, associates a word with a length of several hundred numbers to each word. Vectors, in contrast to simple identifiers from a statistical approach, are formed when learning a neural network and take into account the relationship between words. For example, the model can recognize that, since “tea” and “coffee” often appear in similar contexts, both of these words should be possible in the context of the new word “spill”, which, say, in the training data only one of them occurred.
However, the process of learning vector representations is clearly more statistically demanding than rote memorization of examples. In addition, it is not clear what to do with those rare input words that were not often encountered so that the network could build an acceptable vector representation for them. In this situation, it is logical to combine both methods.
Since last year, Yandex.Translate has been using a
hybrid model . When the Translator receives the text from the user, he gives it for translation to both systems - the neural network and the statistical translator. Then the algorithm based on the
CatBoost training method estimates which translation is better. When grading, dozens of factors are taken into account - from the length of the sentence (short phrases translates the statistical model better) to the syntax. The translation recognized as the best is shown to the user.
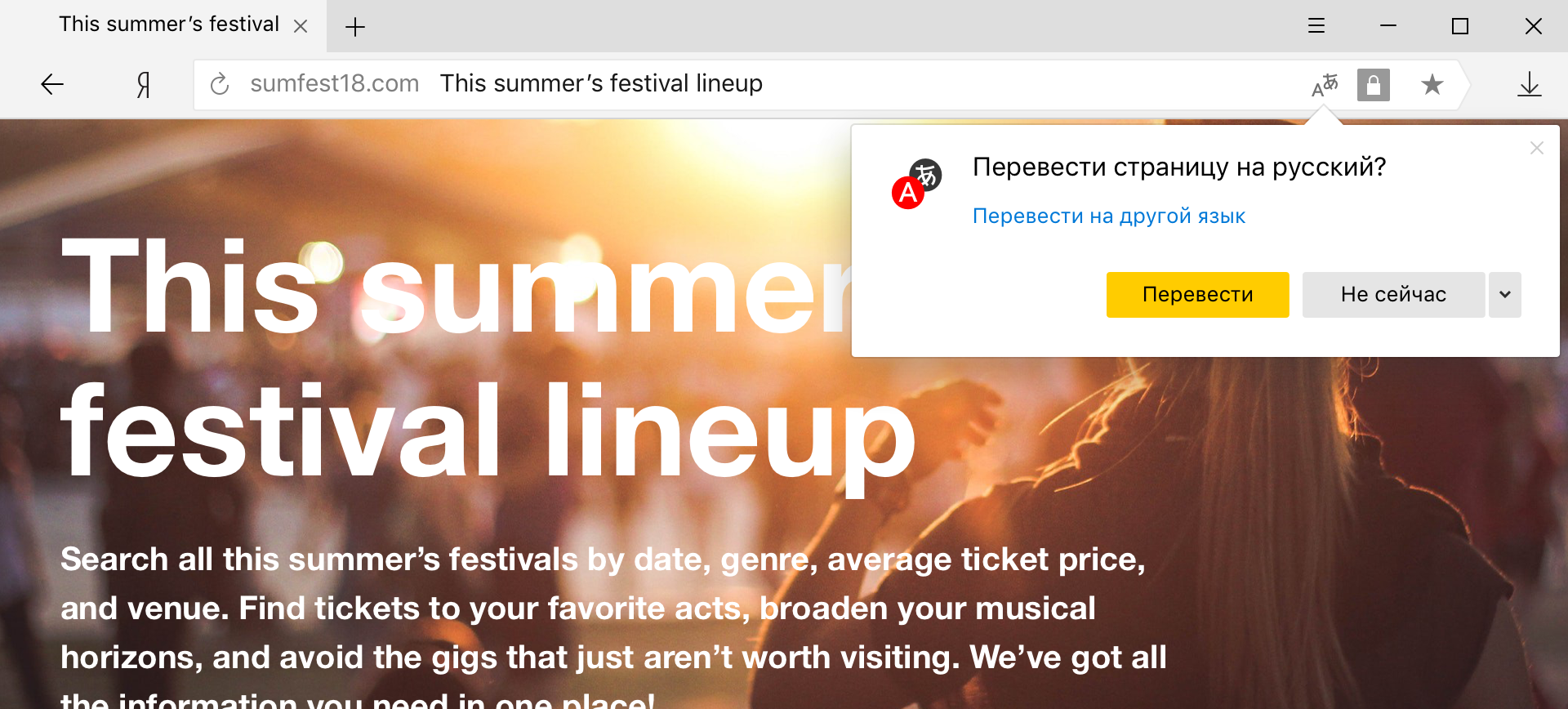
It is the hybrid model that is now used in Yandex Browser, when the user selects specific words and phrases on the page for translation.
This mode is especially convenient for those who generally speak a foreign language and would like to translate only unknown words. But if, for example, instead of the usual English you meet Chinese, here it will be difficult to do without a page-based translator. It would seem that the only difference is in the volume of the translated text, but not everything is so simple.
Neural Network Translator Web Pages
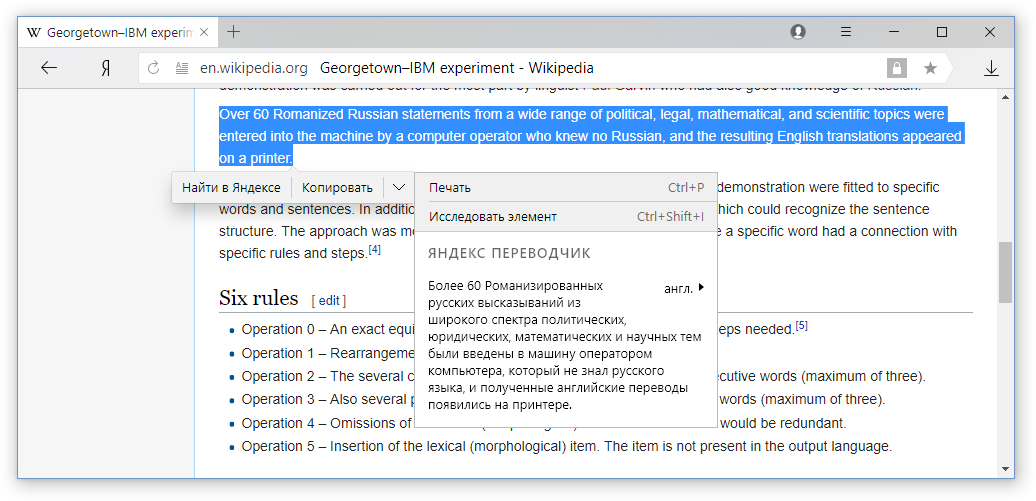
Since the time of the
Georgetown experiment and to this day, all machine translation systems have been trained to translate each sentence of the source text separately. While the web page is not just a set of sentences, but a structured text with fundamentally different elements. Consider the basic elements of most pages.
Headline Usually bright and large text, which we see immediately upon entering the page. The heading often contains the essence of the news, so it is important to translate it correctly. But this is difficult to do, because the text in the title is small and you can make a mistake without understanding the context. In the case of English, it is still more difficult, because English headings often contain phrases with unconventional grammar, infinitives, or even miss verbs. For example,
Game of Thrones prequel announced .
Navigation Words and phrases that help us navigate the site. For example,
Home ,
Back and
My account are hardly worth translating as “Home”, “Back” and “My Account” if they are located in the menu of the site, and not in the text of the publication.
The main text . Everything is easier with him, he is not much different from ordinary texts and sentences that we can find in books. But even here it is important to ensure the consistency of translations, that is, to ensure that within the same web page the same terms and concepts are translated in the same way.
For high-quality translation of web pages, it is not enough to use a neural network or hybrid model - you must also take into account the structure of the pages. And for this we needed to deal with a lot of technological difficulties.
Classification of text segments . To do this, we again use CatBoost and factors based both on the text itself and on the HTML markup of the documents (tag, text size, number of links per text unit, ...). The factors are quite heterogeneous, so CatBoost (based on gradient boosting) shows the best results (classification accuracy is above 95%). But segment classification alone is not enough.
The bias in the data . Traditionally, Yandex.Translate algorithms are trained on texts from the Internet. It would seem that this is an ideal solution for training a web page translator (in other words, the network learns from texts of the same nature as from the texts on which we are going to use it). But as soon as we learned to separate the different segments from each other, we found an interesting feature. On average, content on sites takes up about 85% of the entire text, while headings and navigation account for only 7.5% each. Recall also that the headings themselves and the elements of navigation in style and grammar are noticeably different from the rest of the text. These two factors collectively lead to the problem of skewed data. It is more profitable for the neural network to simply ignore the features of these very poorly represented segments in the training sample. The network is trained to translate well only the main text, which affects the quality of translation of headings and navigation. In order to level this unpleasant effect, we did two things: we attributed one of three types of segments (content, heading, or navigation) to each pair of parallel sentences and artificially raised the concentration of the last two in the training building to 33% due to the fact that began to more often show learning examples of the neural network.
Multi-task learning . Since we are now able to divide texts on web pages into three classes of segments, it may seem like a natural idea to train three separate models, each of which will cope with the translation of its type of text - headings, navigation, or content. It really works well, but the scheme works even better when we train one neural network to translate all types of texts at once. The key to understanding lies in the idea of
mutli-task learning (MTL): if there is an internal connection between several tasks of machine learning, a model that learns to solve these problems at the same time can learn how to solve each of the tasks better than a specialized profile model!
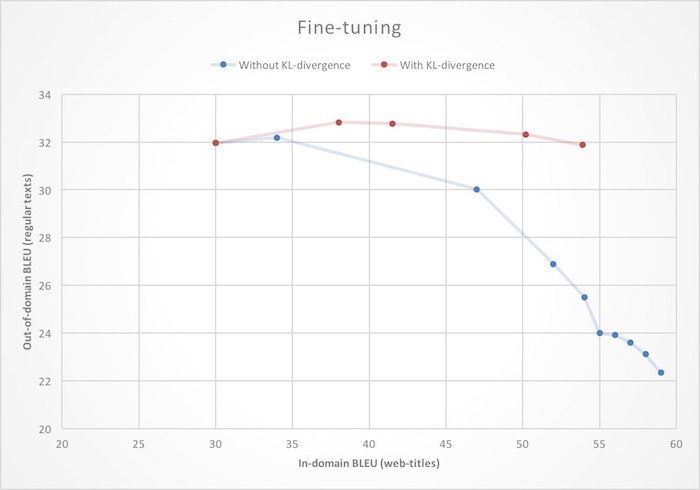
Fine-tuning . We already had a very good machine translation, so it would be unwise to train a new translator for Yandex. Browser from scratch. It is more logical to take the basic system to translate ordinary texts and to train it to work with web pages. In the context of neural networks, this is often called the term fine-tuning. But if you approach this task head-on, i.e. just initialize the neural network weights with the values from the finished model and start learning on new data, then you can face the domain shift effect: as you learn, the translation quality of the web pages (in-domain) will increase, but the translation quality is normal (out-of-domain ) texts will fall. To get rid of this unpleasant feature, during the additional training, we impose an additional restriction on the neural network, prohibiting it from changing weight too much compared to the initial state.
Mathematically, this is expressed by adding a term to the loss function (loss function), which
is the Kullback-Leibler distance (KL-divergence) between the probability distributions of the next word generated by the source and the additional networks. As you can see in the illustration, this leads to the fact that the increase in the quality of translation of web pages no longer leads to degradation of the translation of plain text.
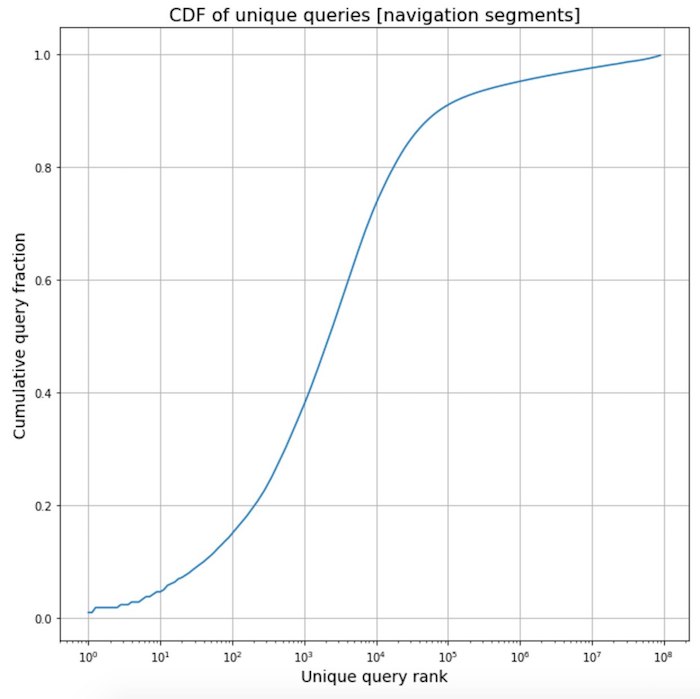
 Polishing frequency phrases from navigation
Polishing frequency phrases from navigation . In the process of working on a new translator, we collected statistics on the texts of various segments of web pages and saw something interesting. Texts that relate to navigation elements are fairly standardized, so they often represent the same template phrases. This is such a powerful effect that more than half of all navigation phrases on the Internet fall on only 2,000 of the most frequent of them.
Of course, we took advantage of this and gave a few thousand of the most frequent phrases and their translation for verification to our translators in order to be absolutely sure of their quality.
External alignments. Another important requirement for the web page translator in the Browser was that it should not distort the markup. When HTML tags are placed outside sentences or at their boundaries, no problems arise. But if inside a sentence there are, for example,
two underlined words , then in the translation we want to see “two
underlined words”. Those. As a result of the transfer, two conditions must be met:
- The underlined fragment in translation must correspond to the underlined fragment in the source text.
- The consistency of the translation at the borders of the underlined fragment should not be violated.
In order to ensure this behavior, we first translate the text as usual, and then with the help of statistical models of
word -by-
word alignment we determine the correspondence between the fragments of the original and translated texts. This helps to understand exactly what needs to be underlined (in italics, formatted as a hyperlink, ...).
Intersection observer . The powerful neural network translation models that we have trained require significantly more computing resources on our servers (both CPU and GPU) than statistical models of previous generations. At the same time, users do not always finish reading the pages to the end, so sending the entire text of web pages to the cloud looks redundant. To save server resources and user traffic, we taught Translator to use the
Intersection Observer API to send only the text displayed on the screen for translation. Due to this, we managed to reduce the consumption of traffic for the transfer by more than 3 times.
A few words about the results of the introduction of a neural network translator, taking into account the structure of web pages in Yandex Browser. To assess the quality of translations, we use the BLEU * metric, which compares translations made by a machine and a professional translator, and assesses the quality of machine translation on a scale from 0 to 100%. The closer the machine translation to the human, the higher the percentage. Usually, users notice a change in quality as the BLEU metrics grow by at least 3%. New translator Yandex. Browser showed an increase of almost 18%.

Machine translation is one of the most difficult, hot and researched tasks in the field of artificial intelligence technologies. This is due both to its purely mathematical appeal and its relevance in the modern world, where every second an incredible amount of content in various languages is created on the Internet. Machine translation, which until recently had caused mostly laughter (recall the
mouse drovers ), nowadays helps users overcome language barriers.
It’s still far from perfect quality, so we’ll continue to move on to the leading edge of technology in this direction, so that Yandex.Browser users can go beyond, for example, the runet and find useful content for themselves anywhere on the Internet.