At the end of the winter of this year, the competition was held IEEE's Signal Processing Society - Camera Model Identification. I participated in this team competition as a mentor. About the alternative method of team building, the decision and the second stage under the cut.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
Formulation of the problemFrom the photo you need to determine the device for which this photo was taken. Dataset consisted of pictures of ten classes: two iPhones, seven android smartphones and one camera. The training sample consisted of 275 full-size images of each class. In the test sample, only the central crocs 512x512 were presented. And to 50 percent of them, one of three augmentations was applied: jpg compression, resize with cubic interpolation or gamma correction. It was possible to use external data.
 Essence (tm)
Essence (tm)If you try to explain the problem in simple language, the idea is presented in the picture below. As a rule, modern neural networks teach to distinguish objects in a photo. those. you need to learn how to distinguish cats from dogs, pornography from swimsuits or tanks from the roads. At the same time, it should always be indifferent how and on which device a snapshot of a cat and a tank is taken.

In the same competition, everything was quite the opposite. Regardless of what is shown in the photo, you need to determine the type of device. That is, to use such things as matrix noises, image processing artifacts, optical defects, etc. This was the key challenge - to develop an algorithm for catching low-level features of images.
Team interaction featuresThe overwhelming majority of the kaggle teams are formed as follows: participants with a close leaderboard leader will team up, and each will saw their version of the solution from beginning to end. I wrote a
post about a typical example of such a speech. However, this time we went a different way, namely: we divided the parts of the decision according to people. In addition, according to the rules of the competition, the top 3 student teams received a ticket to Canada for the second stage. Therefore, when the backbone was assembled, we completed the team in order to comply with the rules.
DecisionTo show a good result on this task, it was necessary to put together the following puzzle by priorities:
- Find and download external data. In this competition it was allowed to use an unlimited number of external data. And it quickly became clear that the large external dataset was dragging.
- Filter external data. People sometimes upload processed images, which kills all the features of the device.
- Use a reliable local validation scheme. Since even one model gave out accuracy in the region of 0.98+, and there were only 2k shots in the test, the choice of the model checkpoint was a separate task
- Train the model. The forum posted a very powerful baseline. However, without a pinch of magic, he allowed to get only silver.
Data collectionThis part was handled by
Arthur Fattakhov . For this task, external data was quite easy to get; these are just pictures from certain phone models. Arthur wrote a python script that uses a library for conveniently parsing html pages called
BeautifulSoup . But, for example, on a flickr album page, blocks of photos are dynamically loaded, and to get around this, you had to use
selenium , which emulated the browser action. A total of 500+ GB of photos were downloaded from yandex.fotki, flickr, wiki commons.
Data filteringThis was my only contribution to the solution in the form of code. I just looked at how the raw photos look and made a bunch of rules: 1) the size typical for a particular model 2) jpg quality is above the threshold 3) the availability of the necessary meta-tags of the models 4) the correct software that was processed.
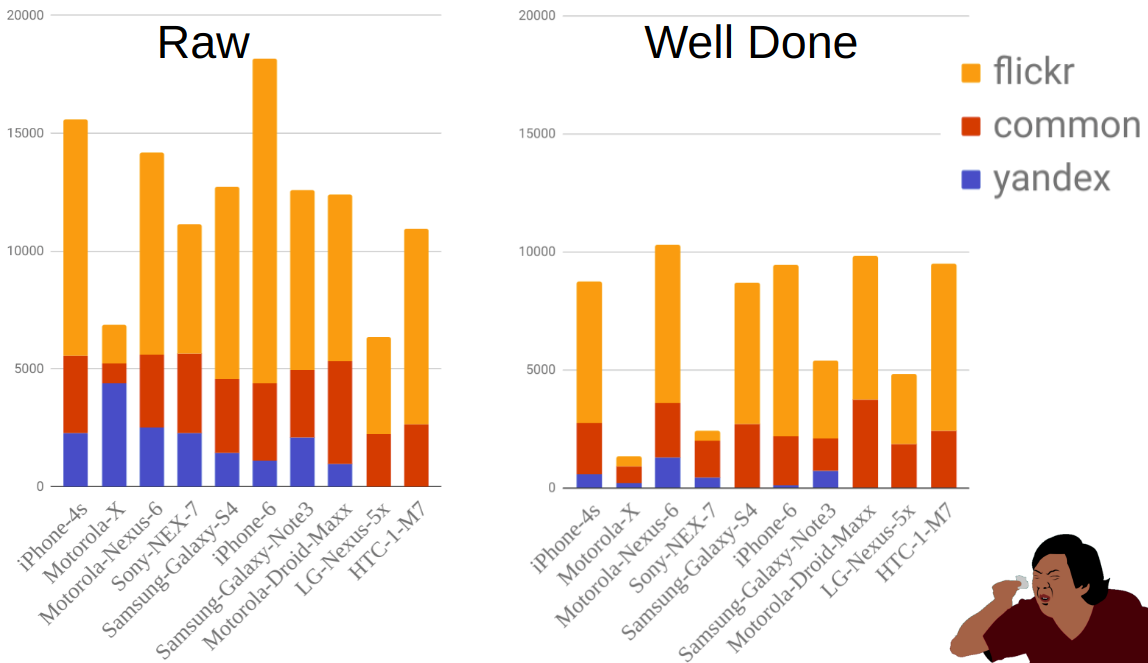
The figure shows the distribution of photos by sources and mobile phones before and after filtering. As you can see, for example, Moto-X is much smaller than other phones. At the same time, there were quite a lot of them before filtering, but most of them were eliminated due to the fact that there are many variants of this phone and the owners did not always correctly indicate the model.
ValidationIlya Kibardin was involved in the implementation of the training and validation part. Validation on a piece of kaggle-train did not work at all - the grid knocked out almost 1.0 accuracy, and on the leaderboard it was about 0.96.
Therefore, under the validation were taken pictures of
Gleb Posobin , which he took from all sites with reviews of phones. It had a mistake: instead of an iPhone 6, there was an iPhone 6+. We replaced it with a real iPhone 6 and dropped 10% of the pictures from the train Kagla to balance the classes.
When learning the metric was considered as follows:
- We consider cross entropy and akurasi on the center of validation.
- We consider cross entropy and akurasi on (manipulation + center of croons) for each of these 8 manipulations. Averaging them over eight manipulations with arithmetic mean.
- We add up the scores from item 1 and item 2 with weights 0.7 and 0.3.
The best checkpoints were selected according to the weighted cross entropy obtained in step 3.
Training modelsSomewhere in the middle of the competition,
Andres Torrubia laid out the entire
code of his decision . He was so good in terms of the accuracy of the final models that a bunch of teams flew up the leaderboard with him. However, he wrote on keras, and the level of the code wanted the best.
The situation changed a second time when
Ivan Romanov laid out the
pytorch version of this code. It was faster and moreover it easily paralleled several video cards. The code level, however, was still not very good, but it is not so important.
Sadness lies in the fact that these guys finished at 30th and 45th place, respectively, but in our hearts they were forever in the top.
Ilya in our team took the code of Misha and made the following changes.
Preprocessing:- From the original picture is a random cropping 960x960.
- With a probability of 0.5, one random manipulation is applied. (Depending on whether it was applied, is_manip = 1 or 0 is set)
- A random crop 480x480 is made
- There were two training options: either a random rotation of 90 degrees to a specific direction is done (imitation of horizontal / vertical shooting for a mobile), or a random transformation of the D4 group.
 Training
TrainingThe training was done by the finetune of the network entirely, without freezing the convolutional layers of the classifier (we had a lot of data + intuitively, weights that extract high-level objects in the form of cats / dogs can also be subtracted, because we need low-level features).
 Sheduling:
Sheduling:Adam with lr = 1e-4. When the validation loss ceases to improve in the course of 2-3 epochs, decrease lr twice. So until convergence. Replace Adam with SGD and teach three cycles with cyclic lr from 1e-3 to 1e-6.
Final ensemble:I asked Ilya to implement his approach from the previous competition. For the ensemble we trained 9 models, each chose the best 3 checkpoints, each predicted TTA, and in the final all predictions were averaged by the geometric average.
 Epilogue of the first stage
Epilogue of the first stageAs a result, we took 2nd place on the leaderboard and 1st place among student teams. This means that we got to the 2nd stage of this competition as part of the
2018 IEEE International Conference on Acoustics, Speech and Signal Processing in Canada. Of noteworthy, the team that took the 3rd place was also a formal student one. If you count quickly, it turned out that we went around it to one correctly predicted picture.
Final IEEE Signal Processing Cup 2018After all the confirmations came to us, I, Valery and Andrey decided not to go to Canada for the second stage. Ilya and Arthur F. decided to go, they began to arrange everything and they were not given a visa. To avoid an international scandal over the oppression of the strongest Scientists from Russia, the orgs were allowed to participate remotely.
The timeline was:
03/30 - gave out the data of the train
04.09 - issued the test data
12.04 - we were allowed to participate remotely
04/13 - we started to watch something there with data
16.04 - the final
Features of the second stageAt the second stage there was no leaderboard: it was necessary to send only one submit at the very end. That is, even the format of the predictions can not be verified. Also, no camera models were known. And this means two files at once: it will not work to use external data and local validation can be very unrepresentative.
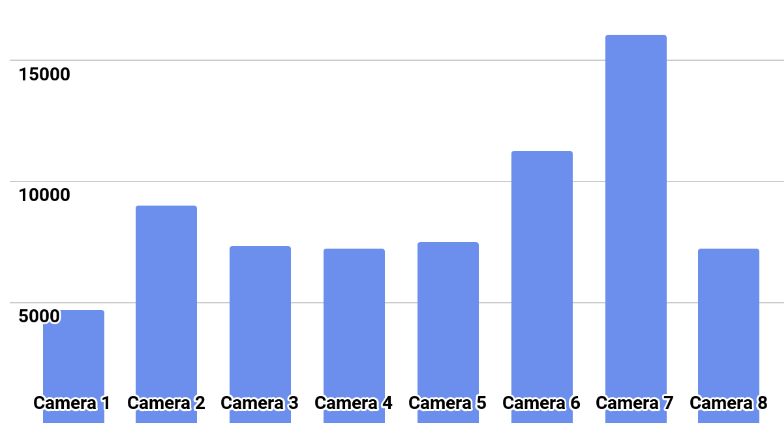
The distribution of classes is shown in the picture.
DecisionWe tried to teach the model with the plan from the first stage with the weights of the best models. All models were vigorously trained to 0.97+ accuracy on their folds, but on the test they gave the intersection of predictions in the region of 0.87.
What I interpreted as a hard overfit. Therefore, proposed a new plan:
- We take our best models of the first stage as a feature extractors.
- From the extracted features, we take PCA so that everything can be learned overnight.
- We train LightGBM.

The logic is as follows. Neural networks are already trained to extract low-level features of the sensor, optics, demokey algorithm, and at the same time do not cling to the context. In addition, features extracted before the final classifier (essentially log. Regression) are the result of a highly non-linear transformation. Therefore, it would be possible to simply teach something simple that is not prone to retraining, such as log.regression. However, since the new data may differ greatly from the data of the first stage, it is still better to train something non-linear, for example, gradient boost on decisive trees. I used this approach in several competitions where I posted the code.
Since there was one submit, I have no reliable way to test my approach. However, DenseNet performed best as a feature extractor. Resnext and SE-Resnext networks showed lower performance on local validation. Therefore, the final decision looked like this.
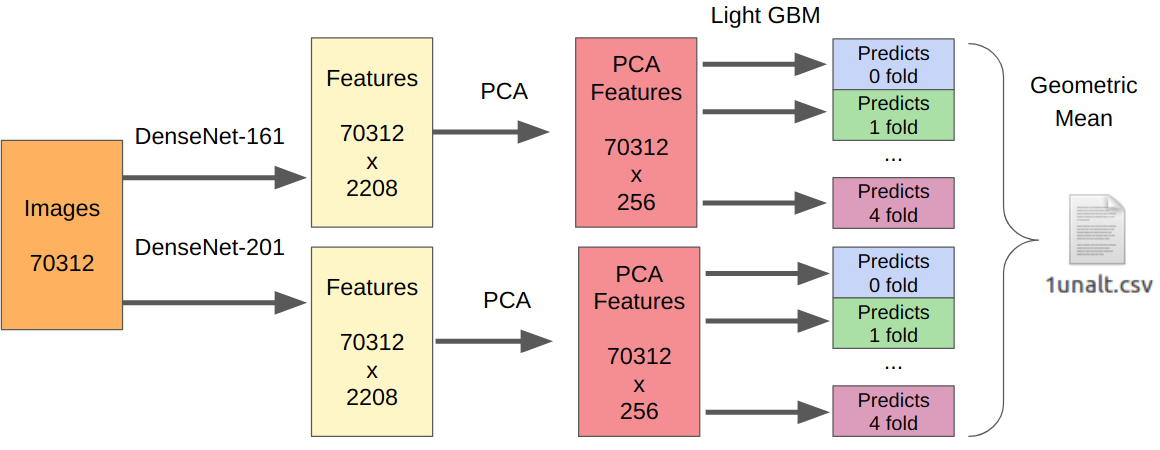
For the part with manipulations, the number of all training samples must be multiplied by 7, since I extracted features from each manipulation separately.
AfterwordAs a result, at the final stage, we took second place, but there are many reservations. To begin with, the place was awarded not by the accuracy of the algorithm, but by the estimated presentation of the jury. The team, which was awarded the first place, did not just prezu, but also a live demo with the work of its algorithm. Well, we still do not know the final speed of each team, and the orgies do not reveal them in correspondence even after direct questions.
From funny things: at the first stage, all the teams of our community indicated in the name of the team [ods.ai] and quite powerfully occupied the leaderboard. After that, such Kaggle legends like
inversion and
Giba decided to join us to see what we are doing here.

I really enjoyed participating as a mentor. Based on the experience of participating in previous competitions, I managed to give a number of valuable tips for improving baseline, as well as building local validation. In the future, this format is more than the place to be: Kaggle Master / Grandmaster as a solution architect + 2-3 Kaggle Expert for writing code and testing hypotheses. In my opinion, this is a pure win-win, since experienced participants are already too lazy to write code and, perhaps, there is not so much time, and beginners get a better result, do not make trivial errors due to inexperience and gain experience even faster.
→
Code of our solution→
Record performances with ML workout