Most recently, we were looking for a data scientist in the team (and found - hello,
nik_son and Arseny!). While communicating with the candidates, we realized that many people want to change their place of work, because they are doing something “on the table”.
For example, they take up the complex forecasting that the boss suggested, but the project stops - because the company does not understand what to include in production, how to make a profit, how to “recapture” the resources spent on the new model.

HeadHunter does not have large computing power, like Yandex or Google. We understand how difficult it is to roll in the production of complex ML. Therefore, many companies stop on the fact that they roll into the simplest linear models.
In the process of the next ML implementation in the recommender system and in the search for vacancies, we encountered a certain amount of classic “rakes”. Pay attention to them, if you are going to implement ML in your home: perhaps this list will help you not to go around them
and find your own personal rake .
Rake number 1: data scientist - freelance artist
In every company that starts to implement machine learning, including neural networks in its work, there is a gap between what the data scientist wants to do and what benefits in production. This is also because a business cannot always explain what good is and how it can help.
We struggle with this in the following way: we discuss all the emerging ideas, but we implement only what the company benefits - now or in the future. Do not do research in a vacuum.
After each implementation or experiment, we consider the quality, resource and economic effects and update our plans.
Rake number 2: update libraries
This problem occurs in many. A lot of new and convenient libraries appear, which a couple of years ago nobody heard about, or there were none at all. I want to use the latest libraries, because they are more convenient.
But there are several obstacles:
1. If, for example, the 14th Ubuntu is used in the prod, then most likely there are no new libraries in it. The solution is to transfer the service to docker and install Python libraries using pip (instead of deb packages).
2. If a code-dependent format (such as pickle, for example) is used to store data, this “freezes” the libraries used. That is, when a machine learning model is obtained using the scikit-learn library of version 15 and saved in the pickle format, then the fifteenth version of the scikit-learn library will be needed to correctly restore the model. You cannot upgrade to the latest version, and this is a much more insidious trap than that described in paragraph 1.
There are two ways out of it:
- use the storage format of the models, independent of the code;
- always be able to re-train any model. Then, when updating the library, you will need to train all the models and save them with the new version of the library.
We chose the second path.
Rake number 3: work with old models
Doing something new in an old, studied model is less useful than doing something simple in a new one. Often, in the end, it turns out that there are more benefits from introducing simpler, but fresh models, and less effort. About this it is important to remember and always consider the number of common efforts in the search for patterns.
Rake number 4: only local experiments
Many data science experts love experimenting locally on their machine learning servers. Only here the products do not have such flexibility: as a result, there are a lot of reasons why these experiments cannot be dragged into production.
It is important to set up communication between the DS-specialist and the sales engineers for a general understanding of how this or that model will work in production, whether there are the power and physical ability to roll out necessary for it. In addition, the more complex the models and factors, the more difficult it is to make them reliable and to be able to train them again at any time. Unlike Kaggle competitions, in production it is often better to donate ten thousandths on local metrics and even some online KPIs, but to introduce a much simpler version of models, stable in results and easy on computational resources.
Not sharing these rakes helps us sharing code (developers and data scientists know how the code written by other developers works), reuse of signs and meta signs in various models both in the learning process and when working in prod (the developed we have framework), unit- and auto-tests, which we drive very often, integrating code with retesting. We put the final models in the git repositories and use them in production too.
Rake number 5: test only prod
Each of our developers and data scientists has their own test bench, sometimes not one. It deployed the main components of production HH. It is expensive, but the quality and speed of development pays for it. This is necessary, but not enough. We are loading not only models that are already in production, but also those that will be there soon. This helps in time to understand that models that work fine on local machines, test benches or in production are 5% of users, and when turned on, they are 100% too heavy.
We use several stages of testing. Very quickly (this is the key moment) we check the code - when adding or changing components in the repository, the code is assembled, the unit- and auto-tests are started for the corresponding components, if necessary, we re-test them also manually - and, if something is wrong, give the answer "You have broken, decide."
Rake number 6: long calculations and loss of focus
If it is required, for example, a week to train some model, it is easy to lose concentration on the task due to switching to another project. We try not to give developers and data scientists more than two tasks in one hand. And no more than one urgent, so that you can switch to it as soon as calculations or A / B experiments are completed for it. This rule is necessary in order not to lose focus and out of fears that some of these tasks are at risk of being lost, and the other part is rolling out much later than necessary.
We stepped on a rake, but did not surrender
Recently, we completed an experiment on the introduction of neural networks in the recommendation system. It began with the fact that in two days the internal hackathon wrote a resume forecasting model based on resumes, which greatly facilitated the search for suitable vacancies.
But later we learned that in order to roll it out into production, you need to update just about everything - for example, transfer the dual-use system, which counts the signs and teaches the model, to docker, and also update the machine learning libraries.
How it was
We used the DSSM model with a single-layer neural network. In the original Microsoft article, a neural network of three layers was used, but we did not observe quality improvements with an increase in the number of layers, so we settled on one layer.

In short:
- The request text and the title of the vacancy are converted into two vectors of symbolic trigrams. We use 20,000 symbolic trigrams.
- The trigram vector is fed to the input of a single-layer neural network. The input of the neural network layer is 20 000 numbers, the output is 64. In fact, the neural network is a matrix of size 20 000 x 64, by which the input trigram vector of dimension 1 x 20 000 is multiplied. A constant vector of dimension 1 x 64 is added to the result of multiplication. the output of such a neural network corresponds to the request (or the title of the vacancy).
- Calculates the scalar product of the dssm-vector of the request and the dssm-vector of the vacancy header. The function is applied to the sigmoid. The final result is the dssm meta-attribute.
When we tried to include this model for the first time, the local metrics became better, but when we tried to roll it into the A / B test, we saw that there was no improvement.
After that, we tried to increase the second layer of neurons to 256 - rolled out by 5% of users: it turned out that the recommender system and the search became better, but when the model was turned on 100%, it suddenly turned out that it was too heavy.
They analyzed why the model is so heavy, removed stemming, experimented with this neural network again. And only after that, having gone all the way anew, they found out that the model provides benefits: the number of responses in the recommender system increased by 700 per day, and in the search, after all recalculations, by 4200.
The introduction of such a not very complex neural network allows our customers to hire an additional dozens of employees through hh.ru every day, and during the implementation we won a significant part of the big problems. Therefore, we plan to develop further neural networks. The plans are to try general stemming, additional lemmatization, process full texts of vacancies and summaries, make experiments with topology (hidden layers and, possibly, RNN / LSTM).
The most important thing we did with this model:
- Do not throw the experiment in the middle.
- We counted the increase in response rates and found out that the work on this model is worth it. It is very important to understand how much benefit each such introduction brings.
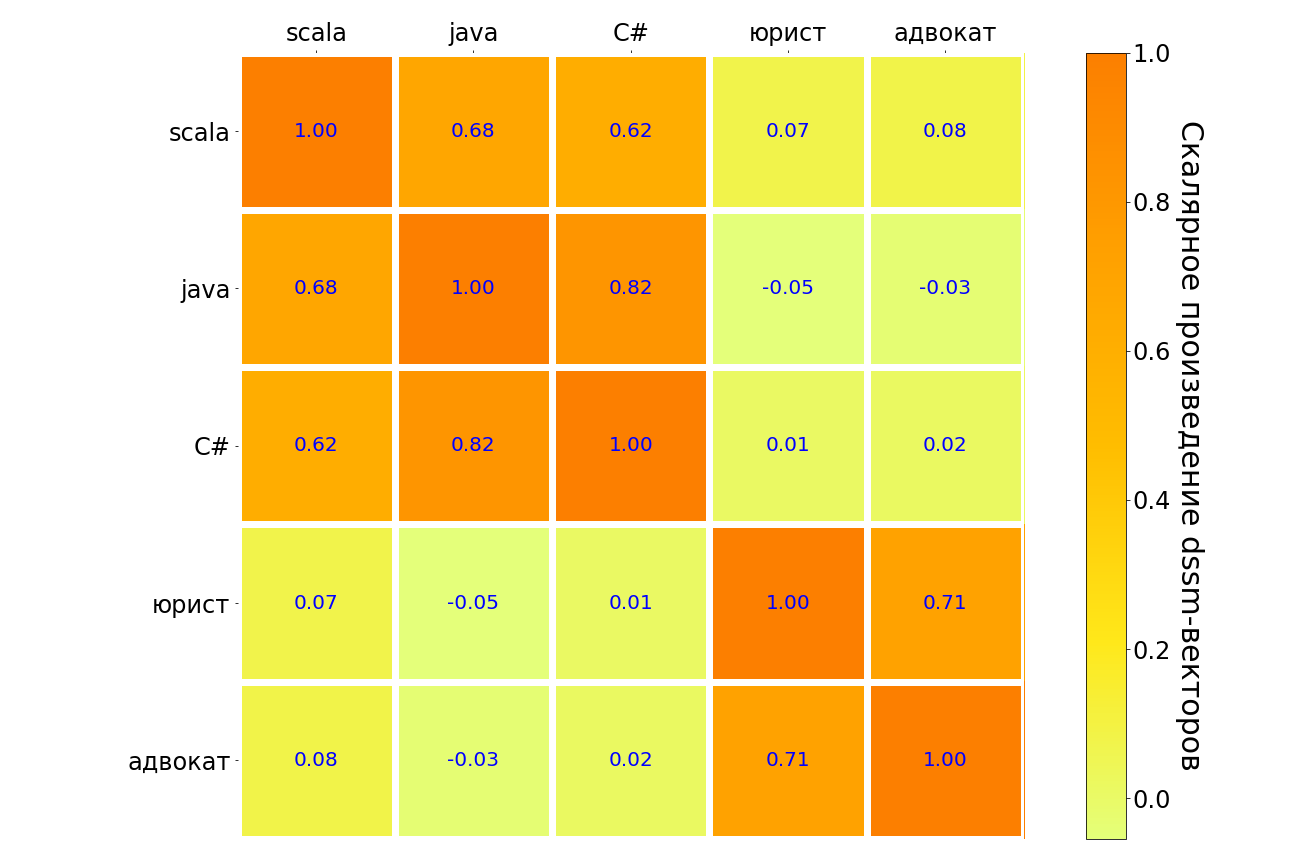
Interestingly, the model that we did and eventually added to the prod is very similar to the principal component method (PCA) applied to the matrix [query text, document title, was it a click]. That is, to the matrix, in which the row corresponds to the unique query, the column to the unique title of the vacancy; the value in the cell is 1 if, after this request, the user clicked on the vacancy with this header, and 0 if there was no click.
The results of applying such a model to scala, java, C #, “lawyer”, “attorney” requests are in the table below. Similar in meaning pairs of requests are highlighted in dark, unlike - in light. It can be seen that the model understands the connection between different programming languages, there is a strong connection between the query “lawyer” and “lawyer”. But between the "lawyer" and any programming language communication is very weak.
At some point, I really want to give up - the experiments are going on, but they are not “lit.” In this place, the data scientist can be useful support for the team and another calculation of benefits brought: perhaps it is really worth "bury the stewardess" and not try to "ride a dead horse", this is not a failure, but an experiment successfully conducted with a negative result. Or, after weighing all the pros and cons, you will conduct another experiment that "shoot." So it happened to us.