Note trans. : this small (but capacious!) article written by Michael Hausenblas from the OpenShift team at Red Hat was so “liking" for us that almost immediately after its discovery it was added to our internal knowledge base on Kubernetes. And since the information presented in it will obviously be useful for the wider Russian-speaking IT community, we are pleased to post its translation.
As you might have guessed, the title of this publication is a reference to the Pixar animated film of 1998, “A Bug's Life”
(in the Russian box office it was called “The Adventures of Flick” or “The Life of an Insect” - approx. Transl. ) , And indeed: between an ant— Kubernetes has a lot of similarities in working and living. We take a close look at the full life cycle of the hearth from a practical point of view - in particular, the ways in which you can influence the behavior during startup and shutdown, as well as the right approaches to checking the status of the application.
Regardless of whether you created it yourself or, better, through a controller like
Deployment ,
DaemonSet or
StatefulSet , it can be in one of the following phases:
- Pending : The API Server created the resource and pledged it in etcd, but it was not yet scheduled for it, and its container images were not obtained from the registry;
- Running : it was assigned to the node and all the containers were created by kubelet ;
- Succeeded (successfully completed): the operation of all the pod containers is successfully completed and they will not be restarted;
- Failed (completed with an error): all pod containers have stopped functioning and at least one of the containers has failed;
- Unknown : The API Server was unable to poll the status of the hearth, usually due to an error in the interaction with the kubelet .
When performing
kubectl get pod , note that the
STATUS column can show other (except these five) messages — for example,
Init:0/1 or
CrashLoopBackOff . This happens for the reason that the phase is only part of the general state of the hearth. A good way to find out exactly what happened is to run
kubectl describe pod/$PODNAME and look at the
Events: entry below. It displays a list of relevant actions: that the image of the container was received, it was planned under, the container is in the “problematic”
(unhealthy) state.
Now let's take a look at a specific example of the life cycle of the hearth from beginning to end, shown in the following diagram:
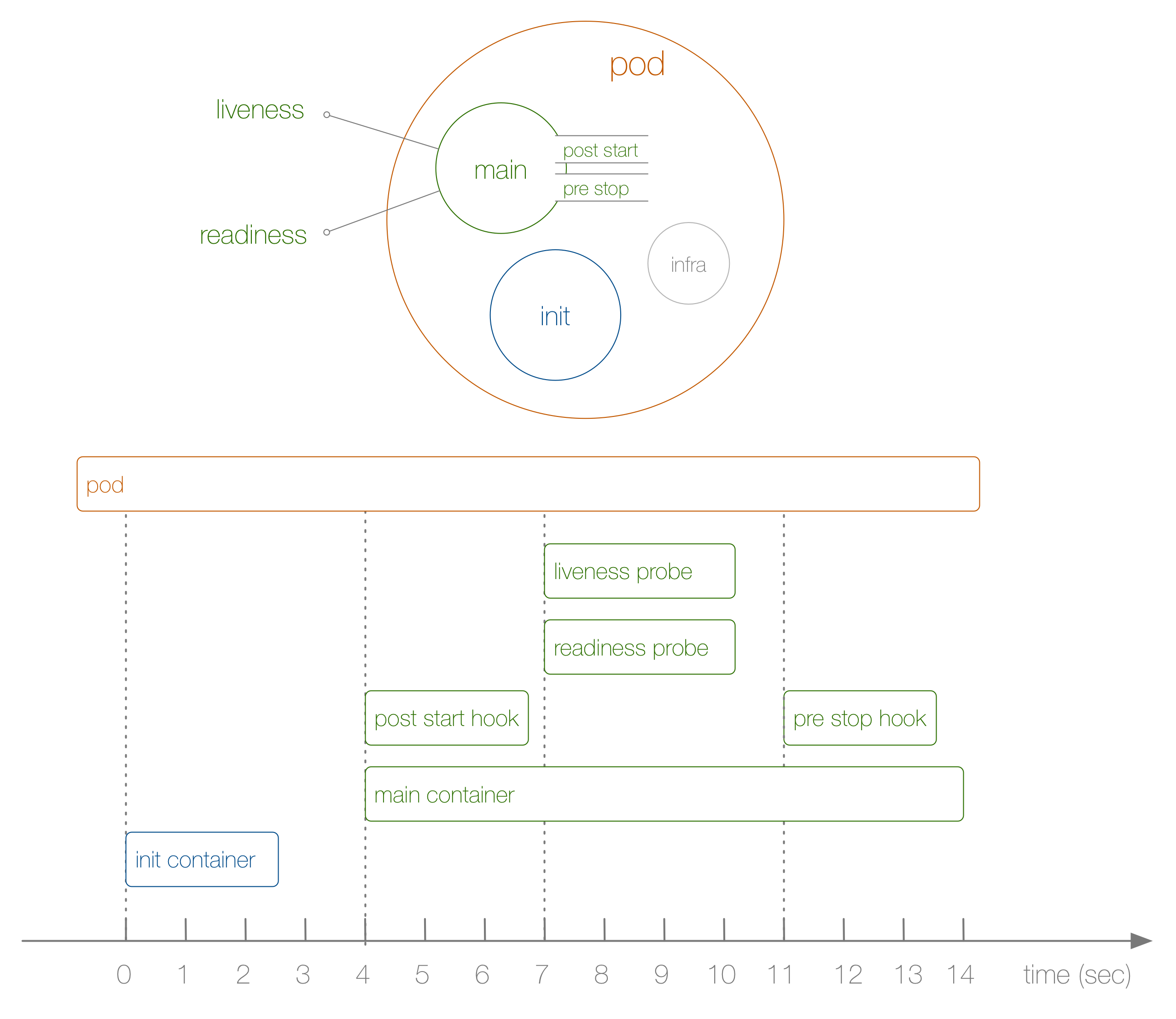
What happened here? The steps are as follows:
- This is not shown in the diagram, but at the very beginning a special infra-container is launched and sets up the namespaces to which the other containers join.
- The first user-defined container that starts is the init-container ; It can be used for initialization tasks.
- Then the main container and the post-start hook are started simultaneously; in our case it happens after 4 seconds. Hooks are defined for each container.
- Then, at the 7th second, liveness and readiness tests come into play, again for each container.
- On the 11th second, when it is killed, the pre-stop hook is triggered and the main container is killed after a non-coercive (grace) period. Please note that in reality the process of completing the work of the hearth is somewhat more complicated.
How did I come to the above sequence and its timing? To do this, use the following
Deployment , created specifically to track the order of events (in itself it is not very useful):
kind: Deployment apiVersion: apps/v1beta1 metadata: name: loap spec: replicas: 1 template: metadata: labels: app: loap spec: initContainers: - name: init image: busybox command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing'] volumeMounts: - mountPath: /loap name: timing containers: - name: main image: busybox command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing; sleep 10; echo $(date +%s): END >> /loap/timing;'] volumeMounts: - mountPath: /loap name: timing livenessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing'] readinessProbe: exec: command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing'] lifecycle: postStart: exec: command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing'] preStop: exec: command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing'] volumes: - name: timing hostPath: path: /tmp/loap
Note that for the forced shutdown of the hearth at the moment when the main container was working, I executed the following command:
$ kubectl scale deployment loap --replicas=0
We looked at a specific sequence of events in action and are now ready to move on - to practices in the field of life cycle management. They are:
- Use init-containers to prepare the hearth for normal operation. For example, to get external data, create tables in a database, or wait for the availability of a service on which it depends. If necessary, you can create multiple init-containers, and all of them must complete successfully before normal containers are started.
- Always add
livenessProbe and readinessProbe . The first is used by the kubelet to determine whether and when to restart the container, and deployment to decide whether the rolling update was successful. The second is used by the service ’s decision to direct traffic to under. If these samples are not defined, the kubelet for both assumes that they have been successfully completed. This leads to two consequences: a) the restart policy cannot be applied, b) the containers in the pod instantly receive traffic from the service in front of them, even if they are still busy with the launch process. - Use hooks to properly initialize the container and completely destroy it. For example, this is useful in the case of the functioning of an application, the source code of which you do not have access to or cannot modify it, but which requires some initialization or preparation for shutdown - for example, clearing connections to the database. Note that when using service , the API Server, endpoint controller and kube-proxy may take some time to complete (for example, deleting the corresponding entries from iptables). Thus, completing its work under may affect requests to the application. Often, a simple hook with the sleep call is enough to solve this problem.
- For debugging needs and for understanding in general, why it stopped working, an application can write to
/dev/termination-log , and you can view messages using kubectl describe pod … These defaults are changed through terminationMessagePath and / or using the terminationMessagePolicy in the hearth specification - see API reference for details.
This publication does not
cover initializers (some details about them can be found at the end of this material - approx. Transl. ) . This is a completely new concept introduced in Kubernetes 1.7. Initializers work inside the control plane (API Server) instead of being in the context of a
kubelet , and can be used to “enrich” the pods, for example, with sidecar containers or enforcing security policies. In addition,
PodPresets , which can later be replaced by a more flexible initializer concept, have not been considered.
PS from translator
Read also in our blog: