Hello! Recently, I came across a rather interesting description of the Pusher Channels architecture and decided to translate it for you. In my opinion, the author has described the approaches to the construction of a high-load and scalable architecture in a very accessible way. Most likely, the article will be useful for beginners, as well as specialists from related fields.
In the office of the company Pusher we have a small counter with an ever-increasing figure. It shows the number of messages delivered during the lifetime of the Pusher Channels. On Friday at 22:20 UTC, the number increased by one rank and reached 10.000.000.000.000. There are 13 zeros in it - 10 trillion.
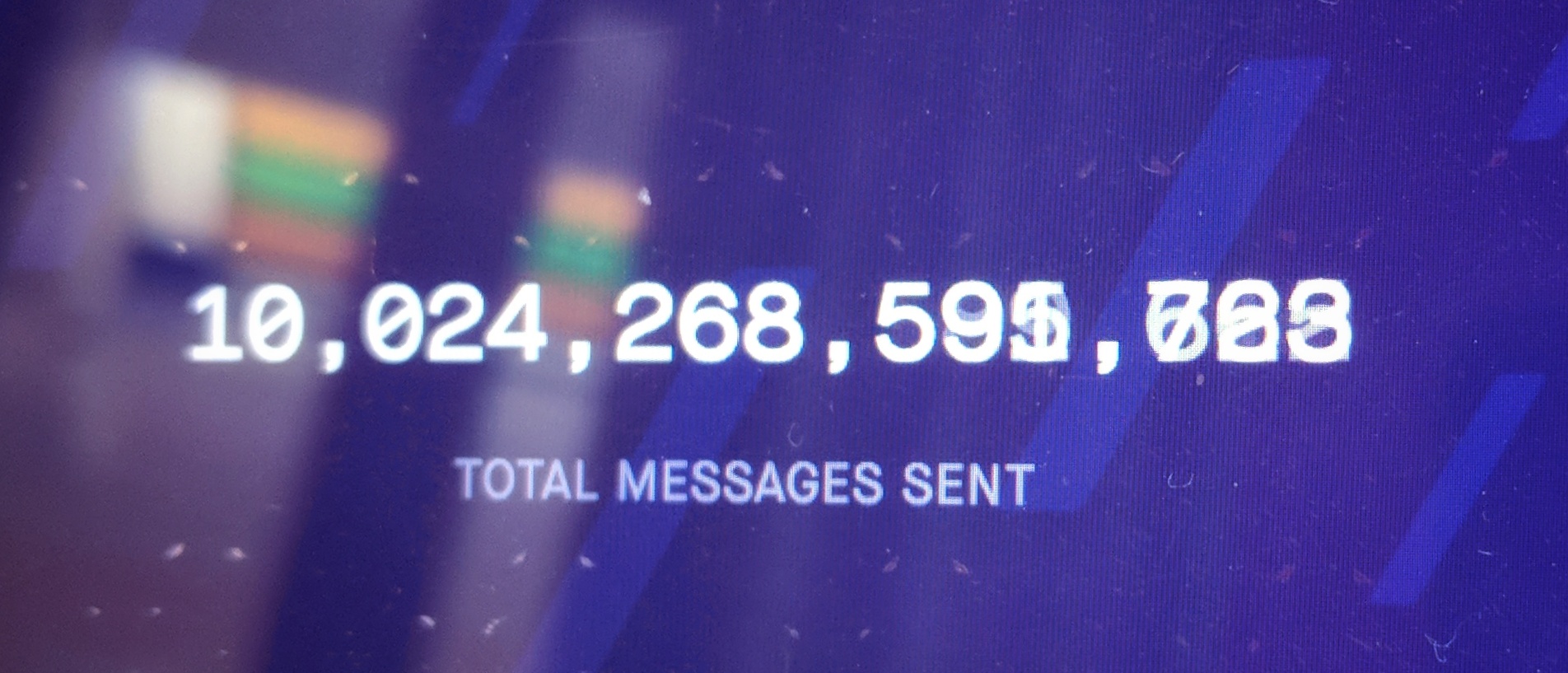
You might think that the total message count is a useless hackneyed metric. But this number is a key indicator of the success of Pusher Channels, our product for real-time communication. First, this counter reflects the trust placed in us by users. Secondly, it measures the scalability of our system. In order for the number to increase, we at Pusher must ensure that users trust the sending of messages to our service, and we must be sure that our system is able to process these messages. But what should we deliver 10 trillion messages? Let's get a look.
In a second, about 200.000 messages are sent via the Pusher Channels, and at the peak moments there are millions. For example, when the New York Times used the service to keep its readers abreast of the US presidential election.
Let's first look at the Pusher Channels as a big black box through which all these messages pass:

Pusher Channels is a system of type publish — subscribe. Clients subscribe to channels (for example, “btc-usd” or “private-user-jim”), and other clients send messages to them. If a million people are subscribed to the channel “btc-usd” and someone sends there the actual cost of bitcoin, then the Pusher Channels will need to deliver a million messages. We do this in a few milliseconds.
One server cannot deliver such a number of message messages in such a short time. Therefore, we use three time-tested methods: fan-out, sharding, and load balancing. Let's see what's in the black box.

Millions of subscribers are distributed to approximately 170 powerful edge servers, each of which holds approximately 20,000 connections. Each such server remembers the list of channels that are interesting to its customers, and subscribes to them in the central Redis-service . Even if on the edge server 2000 clients are interested in “btc-usd”, they need to subscribe to it only once. Thus, when a new message arrives on the channel, Redis sends 170 messages to edge servers, which already send 20,000 messages to their subscribers. This approach is called fan-out.
But only fan-out is not enough for us, because there is still one central Redis component through which everyone who sends messages passes. This centralization limits the number of messages sent per second. To get around this limitation, the central Redis service consists of many Redis shards. Each channel, in turn, is attached to the Redis Shard by hashing its name. When a client wants to send a message, he goes to the rest service. The latter hashes the name of the channel and, based on the result, determines the necessary Redis-shard to which the message should be sent. This approach is called sharding.
It sounds as if we are simply shifting centralization from the Redis service to the rest service. But this is not so, since the rest-service itself consists of about 90 servers that perform the same work: they accept requests for publication, calculate Redis-shards and send messages to them. When a publisher wants to send a message, he goes to one of the many rest servers. This approach is called load balancing.
Together, fan-out, sharding, and load balancing make it possible for the system to lack one central component. This property is key to achieving horizontal scalability, which allows sending millions of messages per second.
We looked at the central components of the Pusher Channels service, but there are other parts, such as metrics (as we get this number at 10 trillion), webhooks (as we inform clients about interesting events), authorization (restriction of access to channels), data on active users, rate limiting (as we are convinced that our customers use exactly as many resources as they paid for and that they do not interfere with other customers). All this additional functionality should be implemented without sacrificing bandwidth, message delivery time and availability of our service as a whole.