Big business and a bloody enterprise have long found a replacement for adults on the tasks of DWH and analysts. DWH is moving massively towards DataLake and Hadoop. It seems that even small companies no longer have much reason to launch analytics on a serious basis. With the increase in the number of cores available even to small businesses, trying to license a full-fledged edition of an adult subd type like Oracle makes little sense. Although the Standard Edition of Oracle is licensed per socket, the most important functionality has been cut out. First, there is no partitioning in the standard edition.
, there is only a partitioning view - Postgres-style partitioning of tables, which can help out only in some situations. Secondly, there is no full-fledged standby, parallel operations are cut out. The RAC cluster is limited to four sockets. As a result, with modern data growth, you very quickly begin to rest on the limitations of the Standard edition, and the price of licensing the Enterprise edition makes this exercise meaningless. In Oracle, you need to license not only the combat server, but also the standby server, while the Enterprise edition is licensed per core. Cluster, partitioning and DataGuard / Standby options require separate licensing and also for cores. As a result, even the entry level server with 16 cores and its stanby are already under EE licenses being pulled by the management of even a bloody enterprise by many hundreds of thousands of dollars and fainting.
We have to look for an alternative in the Hadoup. I tried to compare some requests for a data mart built on parquet files in the server, against the Oracle standard on 8 xeon cores, 196 gigabytes, some enterprise storage with HDD and SSD cache, which is still being shared with several systems. The first query covers 4 tables, in the Oracle they occupied 62, 12, 6.5 and 3.5 GB. In a label that is larger than about 880 million lines. In Oracle, the query plan was:
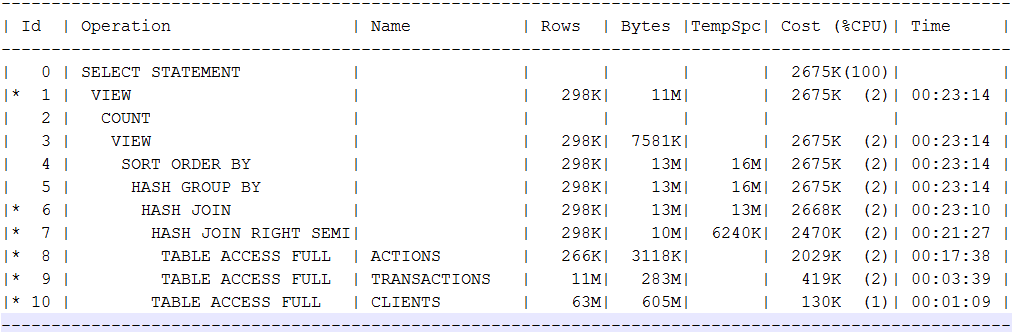
In terms of this, I specifically wanted to see the fulskans and hashjoins typical of my analytical queries. In reality, the request for the standard edition of Oracle takes about 7 minutes. Spark 2.3 launched through spark2-submit to 14 executors with 4 cores / 16 GB frames gives the answer to almost the same request from 10k HDD within a minute. Cloudera Impala pushing with yarn and spark on the same cluster (impalad on 8 nodes, resources comparable to 14 executers with 4 cores) consistently gives a response in 11-12 seconds. At the same time, the Impala is constantly parallel to the load, which should flush the cached data.
Games with block size, moving to Oracle EE edition with its parallelism and adult partitioning would surely reduce the execution time several times, but I slightly doubt that the time would be comparable even with what I received in Spark. On the other hand, only 3-4 nodes of practically free Cloudera Hadoop essentially allow you to get in the usual SQL, the speed for which you would have incomparably large money.
Oraklu should seriously think about licensing policy, if already big fans, like me, do not find any sense in paying for the Enterprise edition.