All modern moderation systems use either
crowdsourcing or machine learning that has already become a classic. At the next ML training session in Yandex, Konstantin Kotik, Igor Galitsky and Alexey Noskov told about their participation in the contest for the mass identification of offensive comments. The competition was held on the Kaggle platform.
- Hello! My name is Konstantin Kotik, I am a data scientist at the Button of Life company, a student of physics and the Graduate School of Business at Moscow State University.
Today, my colleagues and I, Igor Galitsky and Alexey Noskov, will tell you about the Toxic Comment Classification Challenge competition, in which our DecisionGuys team took 10th place among 4551 teams.
Online discussion of topics that are important to us may be difficult. Insults, aggression, harassment, which occur online, often force many people to abandon the search for various adequate opinions on issues of interest to them, to refuse to express themselves.
Many platforms struggle for effective online communication, but this often leads to the fact that many communities simply close down user comments.
One research team from Google and some other company are working on tools that help improve online discussion.
One of the focuses on which they focus is the study of negative online behaviors, such as toxic comments. These are comments that can be offensive, disrespectful, and can simply force the user to leave the discussion.

To date, this group has developed a public API that can determine the toxicity of a comment, but their current models still make mistakes. And in this competition, we, the Kegglers, were challenged to build a model that is able to identify comments containing threats, hatred, insults, and the like. And ideally, it was required that this model be better than the current model for their API.
We have the task of processing the text: to identify, and then classify the comments. As a training and test samples were provided comments from the pages of discussion of Wikipedia articles. In the train there were about 160 thousand comments, in the test 154 thousand.

The training set was labeled as follows. Each comment corresponds to six tags. Tags take the value 1, if the commentary has this type of toxicity, 0 - otherwise. And it may be that all labels are zero, a case of adequate comment. And it may be that one comment contains several types of toxicity, immediately a threat and obscenity.
Due to the fact that we are on the air, I can not demonstrate specific examples of these classes. Regarding the test sample, for each comment it was necessary to predict the likelihood of each type of toxicity.
The quality metric is the average for the types of toxicity of the ROC AUC, that is, the arithmetic average of the ROC AUC for each class separately.
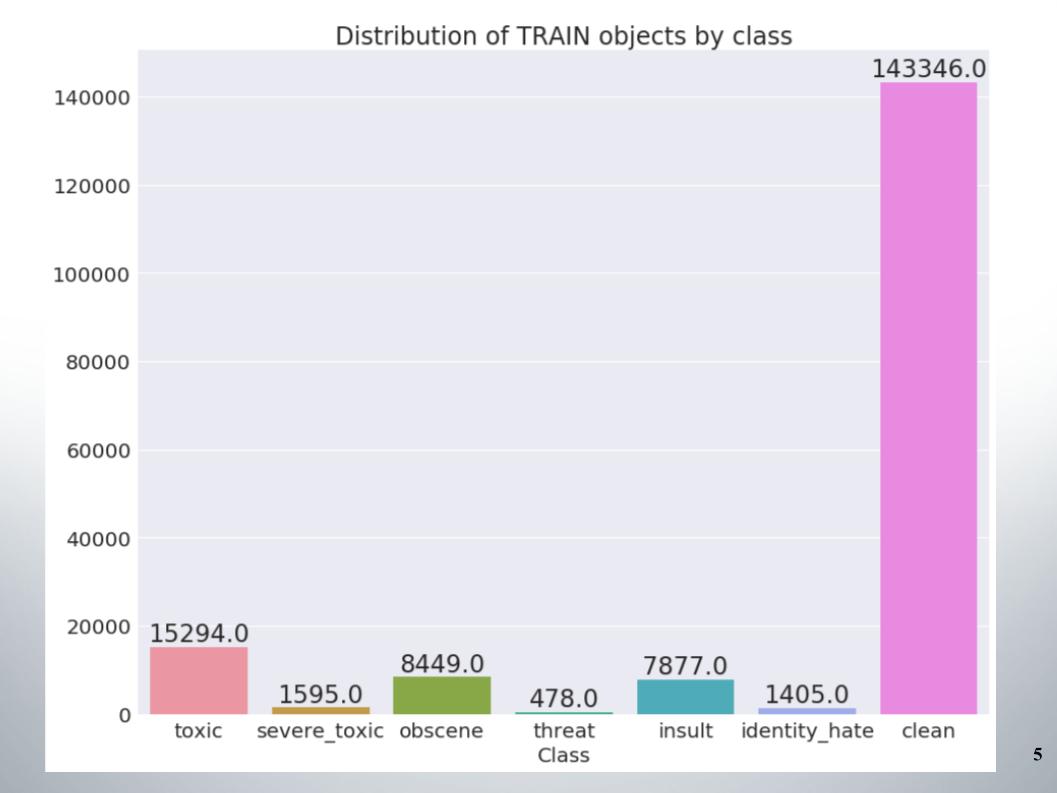
Here is the distribution of objects by class in the training set. It can be seen that the data are not very balanced. At once I will say that our team scored on a trial of methods for working with unbalanced data, for example, oversampling or undersampling.

When building a model, I used two-stage data preprocessing. The first stage is basic data preprocessing, these are view transformations on a slide, this is text reduction to lower case, deletion of links, IP addresses, numbers and punctuation.

For all models, this basic data preprocessing was used. At the second stage, partial preprocessing of data was carried out - replacing emoticons with the appropriate words, decoding abbreviations, correcting typos in the profanity, bringing different types of mat to the same type, and also deleting images. In some comments links to images were indicated, we just removed them.
For each of the models, partial pre-processing of data was used, its different elements. All this was done to ensure that the basic models, in order to reduce the mutual correlation between the basic models when building a further composition.
We turn to the most interesting - the construction of the model.
I immediately abandoned the classic word bag approach. Due to the fact that in this approach each word is a separate sign. This approach does not take into account the general word order, it is assumed that the words are independent. In this approach, the generation of text occurs so that there is some distribution in words, a word is randomly selected from this distribution and inserted into the text.
Of course, there are more complex generating processes, but the essence does not change - this approach does not take into account the general word order. You can go to engrams, but there will only be windowed word order, not general. Therefore, I also understood my teammates to use something smarter.
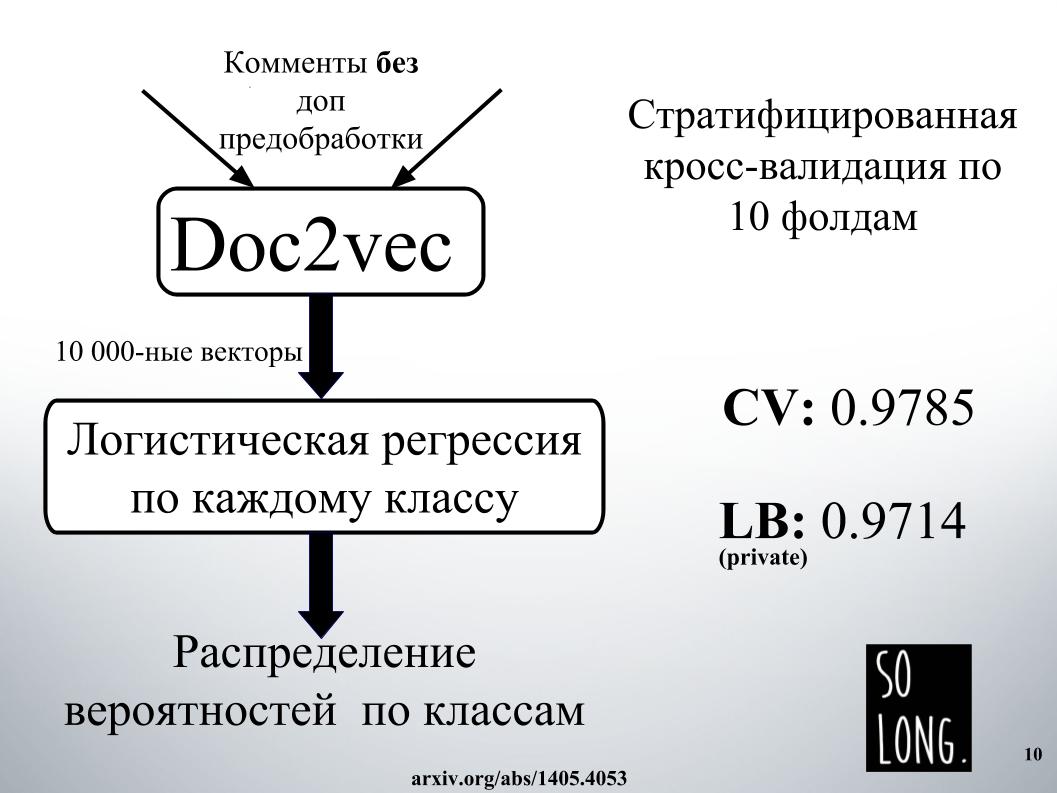
The first smart thing that came to my mind was to use the vector representation using Doc2vec. This Word2vec plus vector, taking into account the uniqueness of a particular document. In the original article, this vector is referred to as a paragraph id.
Further, a logistic regression was studied on this vector representation, where each document was represented by a 10,000-dimensional vector. The quality assessment was carried out on cross-validation of ten folds, it was stratified, and what is important to note, logistic regression was studied for each class, six classification tasks were solved separately. And at the end, the result was a probability distribution by classes.
Logistic regression has been learning for a long time. I did not fit into the RAM at all. At Igor's powers, in order to get the result, as on the slide, we spent about a day somewhere. For this reason, we immediately abandoned the use of Doc2vec due to high expectations, although it could be improved by 1000 if a comment with additional data preprocessing was made.

The smarter thing that we and other competitors have used is recurrent neural networks. They consistently receive words at the entrance, updating their hidden state after each word. Igor and I used the GRU recurrent network for word embedding fastText, which is special in that it solves many independent binary classification problems. Whether or not the context word is predicted.
We also performed a quality assessment on cross-validation of ten folds, it was not stratified here, and here the distribution of probabilities was immediately obtained by classes. We did not separately solve each problem of the binary classification, but immediately generated a six-dimensional vector. It was our one of the best single models.
You ask, what was the secret of success?
He was in a blending, he had a lot of money, with a stacking, and a networking approach. The networking approach needs to be depicted as a directed graph.
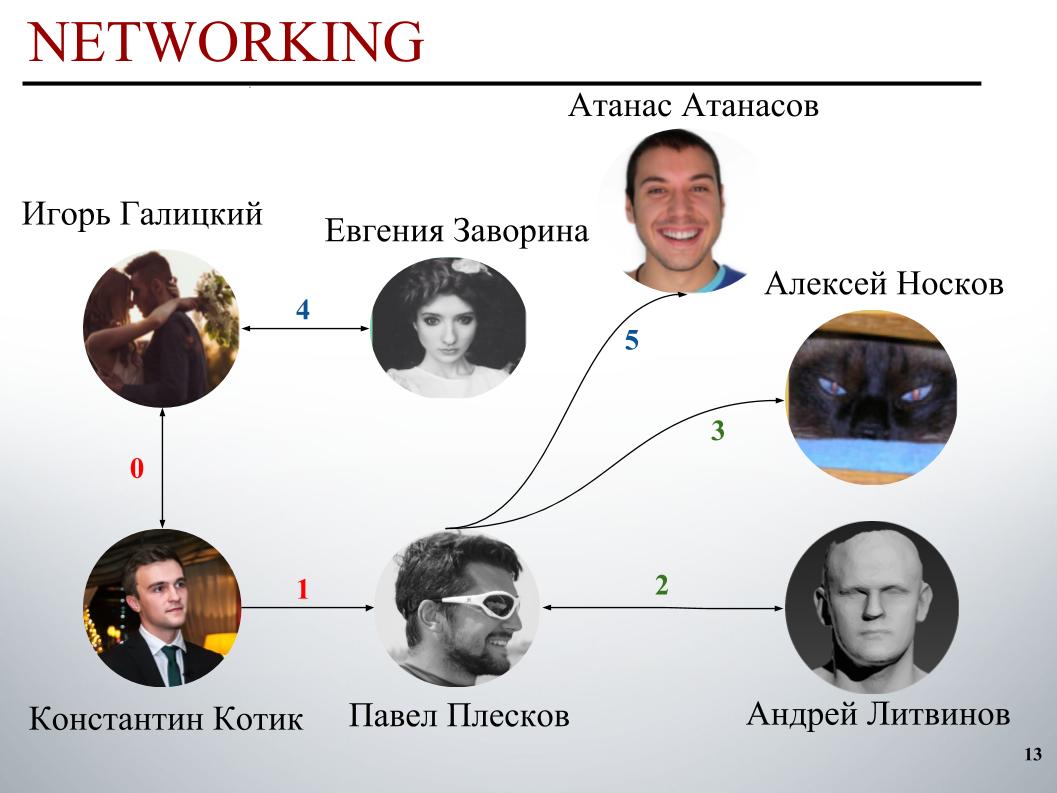
At the start of the competition, the DecisionGuys team consisted of two people. Then Pavel Pleskov in the Slack channel ODS expressed a desire that he wants to team up with someone from the top 200. We then were just somewhere in the 157th place, and Pavel Pleskov at 154, somewhere in the neighborhood. Igor noticed his desire to join, and I invited him to the team. Then Andrey Litvinov joined us, then Pavel invited grandmaster Alexei Noskov to our team. Igor - Eugene. And the last partner of our team was the Bulgarian Atanas Atanasov, and that’s how the human international ensemble turned out.
Now Igor Galitsky will tell you how he taught gru, will tell you in more detail about the ideas and approaches of Pavel Pleskov, Andrey Litvinov and Atanas Atanasov.
Igor Galitsky:
“I’m a data scientist at Epoch8, and I’ll tell you about most of the architectures we used.”
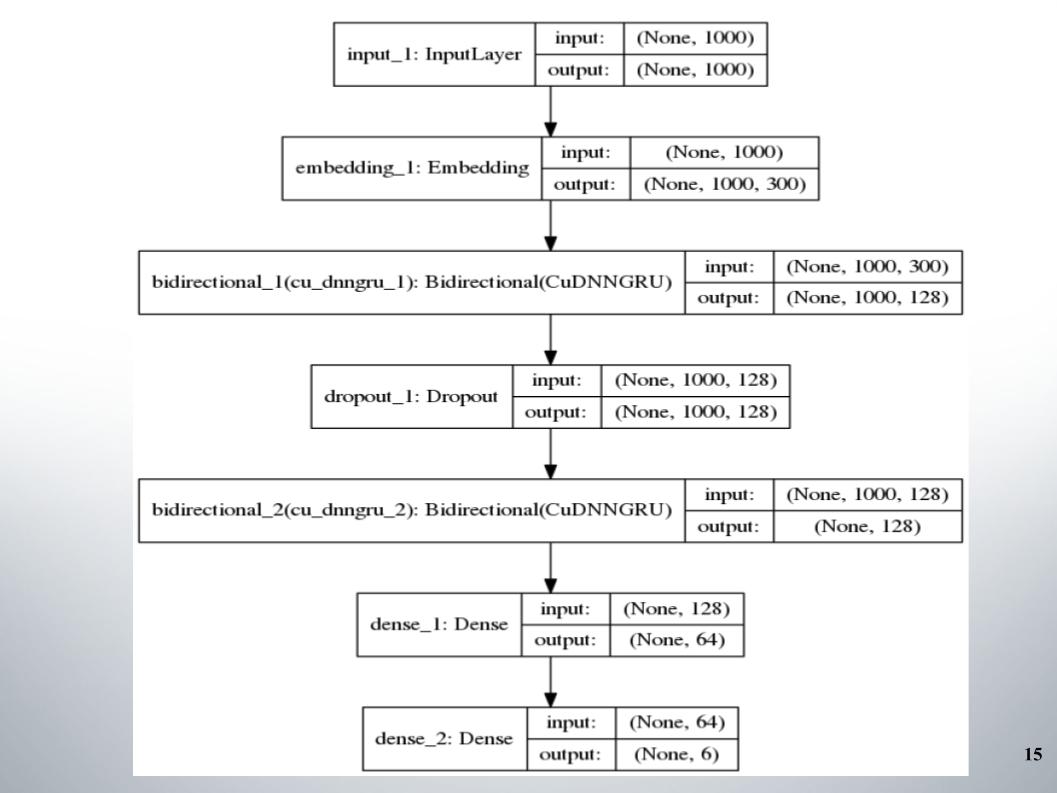
It all started with the standard didirectional gru with two layers, almost all of the teams used it, and the embedding was fastText, the EL activation function.
There is nothing special to say, simple architecture, no frills. Why did she give us such good results with which we stayed in the top 150 for quite a long time? We had a good text preprocessing. It was necessary to move on.
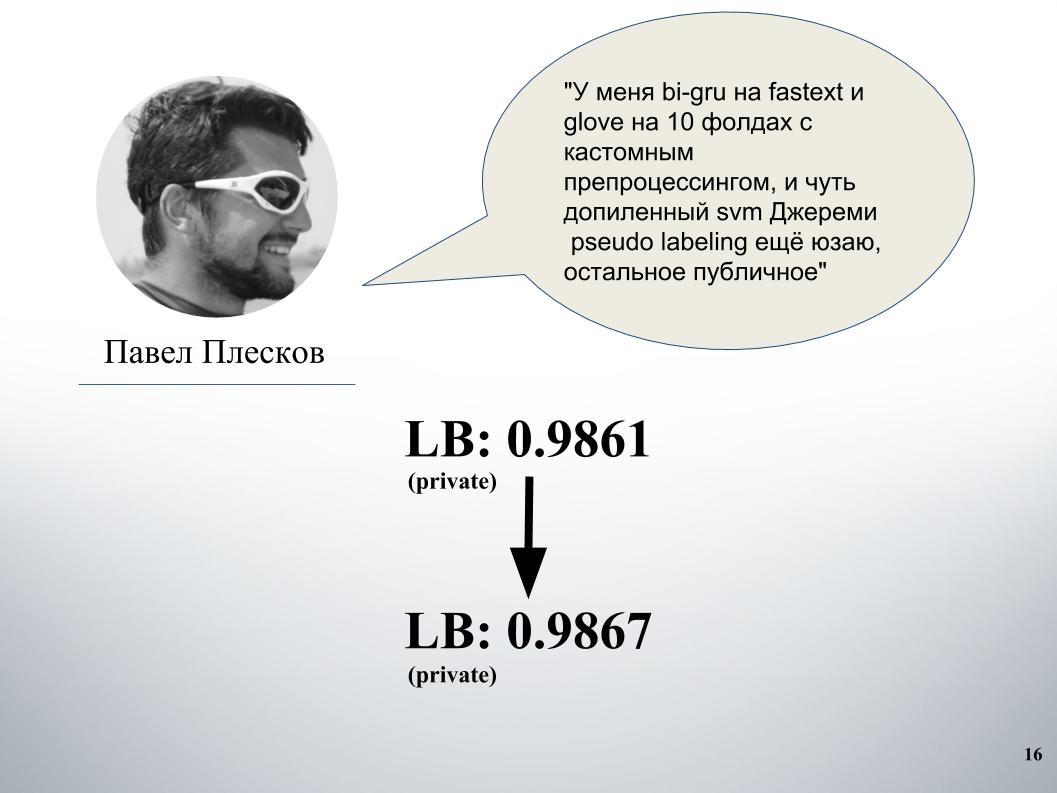
Pavel had his own approach. After blending with ours, this gave a significant increase. Before that we had a blending of gru and models on Doc2vec, she gave 61 LB.
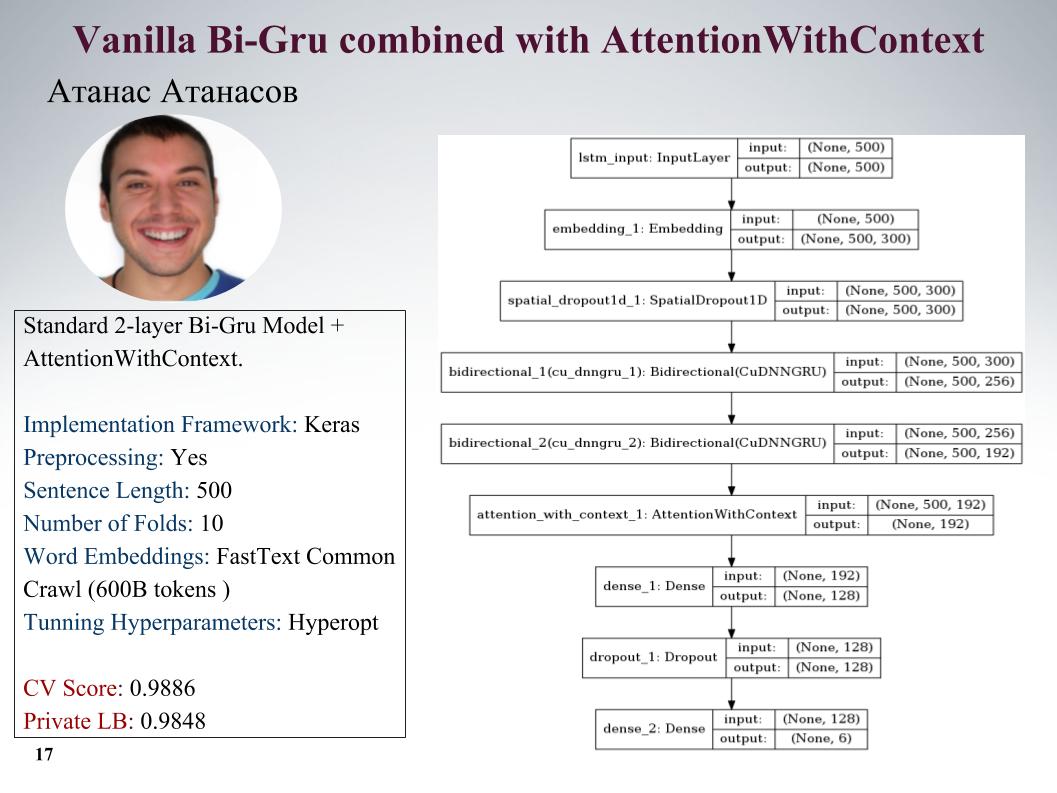
I'll tell you about Atanas Atanasov's approaches, he is directly enthusiastic about any new articles. Here is gru with attention, all the parameters on the slide. He had a lot of really cool approaches, but until the last moment he used his preprocessing, and the whole profit leveled. Soon on the slide.
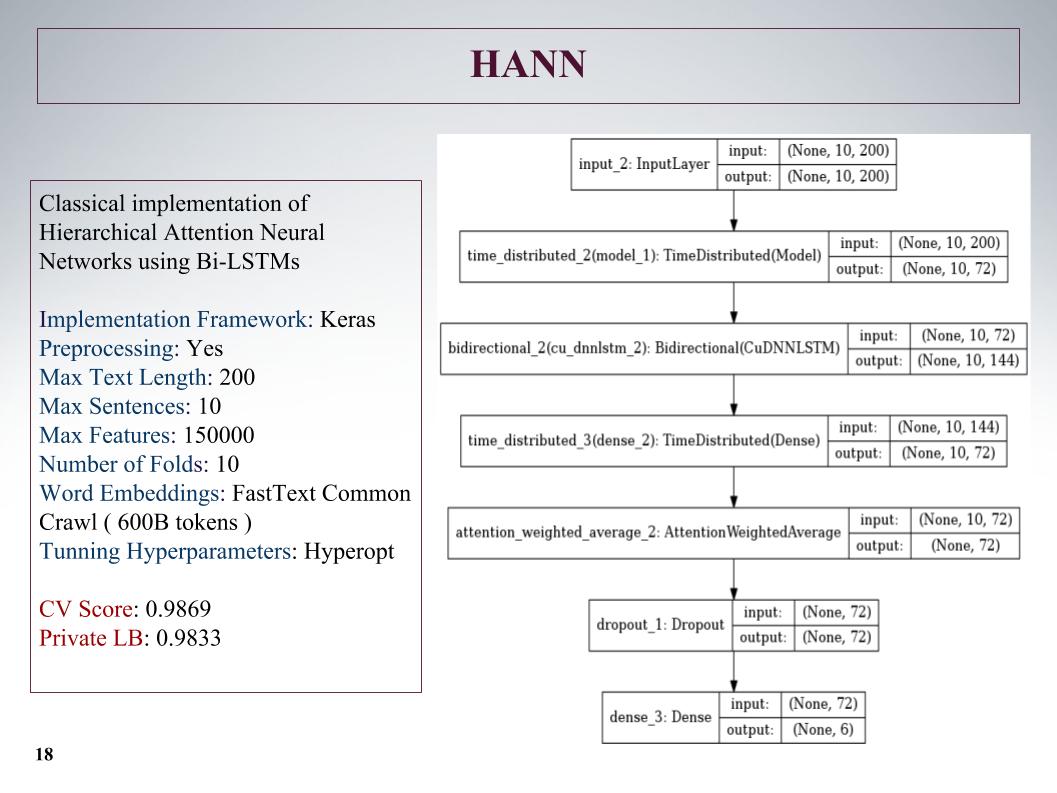
Next was hierarchical attention, he showed even worse results, because initially it was a network for the classification of documents consisting of sentences. He screwed it, but the approach is not very.
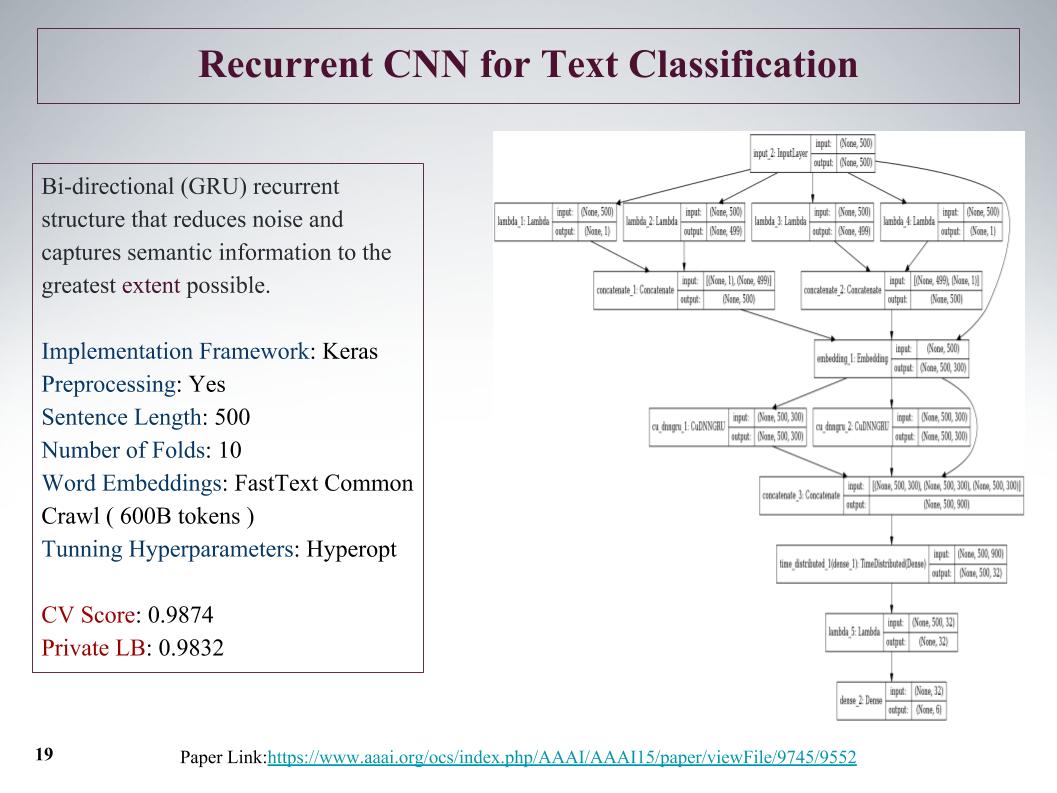
There was an interesting approach, we can initially get features from the beginning and from the end. With the help of convolution, convolutional layers, we separately get the features on the left and right of the tree. This is from the beginning and end of the sentence, then they flicker and again start up through gru.

Also Bi-GRU with attention block. This is one of the best on private was, quite a deep network, showed good results.

The next approach is how to highlight features even more? After the layer of the recurrent network, we make three more parallel layers of convolution. And here we took not such a great length of sentences, cut off by 250, but at the expense of three convolutions, this gave a good result.

It was the deepest network. As Atanas said, he just wanted to teach something big and interesting. Regular convolutional mesh, which studied on text features, the results are nothing special.

This is a rather interesting new approach, in 2017 there was an article on this topic, it was used for ImageNet, and there it was possible to improve the previous result by 25%. Its main feature is that a small layer is launched parallel to the convolutional block, which teaches weights for each convolution in this block. She gave a very cool approach, despite the circumcision of proposals.
The problem is that the maximum length of sentences in these problems reached 1500 words, there were very large comments. Other teams also had thoughts on how to catch in this big sentence, how to find them, because they don’t put everything in very much. And many said that at the end of the sentence there was a very important info. Unfortunately, this was not taken into account in all these approaches, because the beginning was taken. Perhaps this would give further gains.

Here is the AC-BLSTM architecture. The bottom line is that if the bottom division into two parts, in addition to attention, is a clever pulling, and in parallel there is still the usual one, and this is all concrete. Also good results.

And Atanas all his model zoo, then it was a cool mix. In addition to the models themselves, I added some text features, usually the length, the number of capital letters, the number of bad words, the number of characters, all this added. Cross-validation of five folds, and excellent results were obtained, on private LB 0.9867.
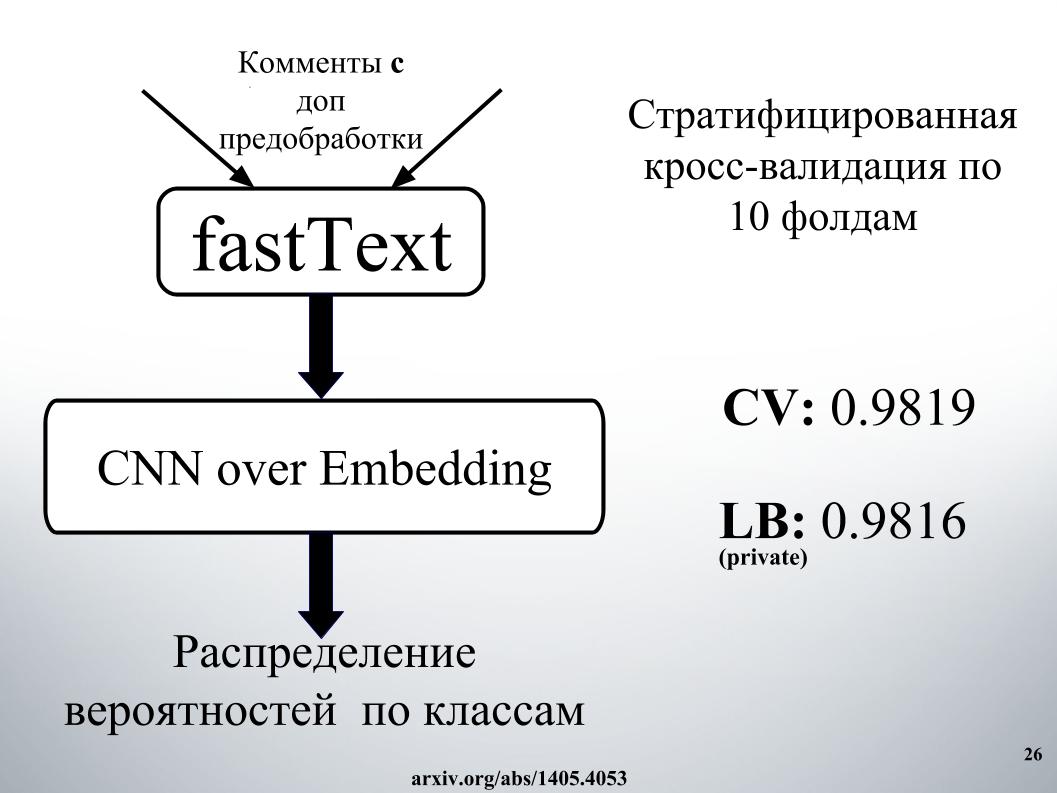
And the second approach, he taught with another embedding, but the results were worse. Mostly all used fastText.
I wanted to say about the approach of our other colleague, Andrey, with his nickname Laol in ODS. He taught a lot of the public kernel, stakal them like not in himself, and it really gave very cool results. It was possible not to do all this, but simply to take a bunch of public kernels of different, even on tf-idf there are, gru all convoluted.
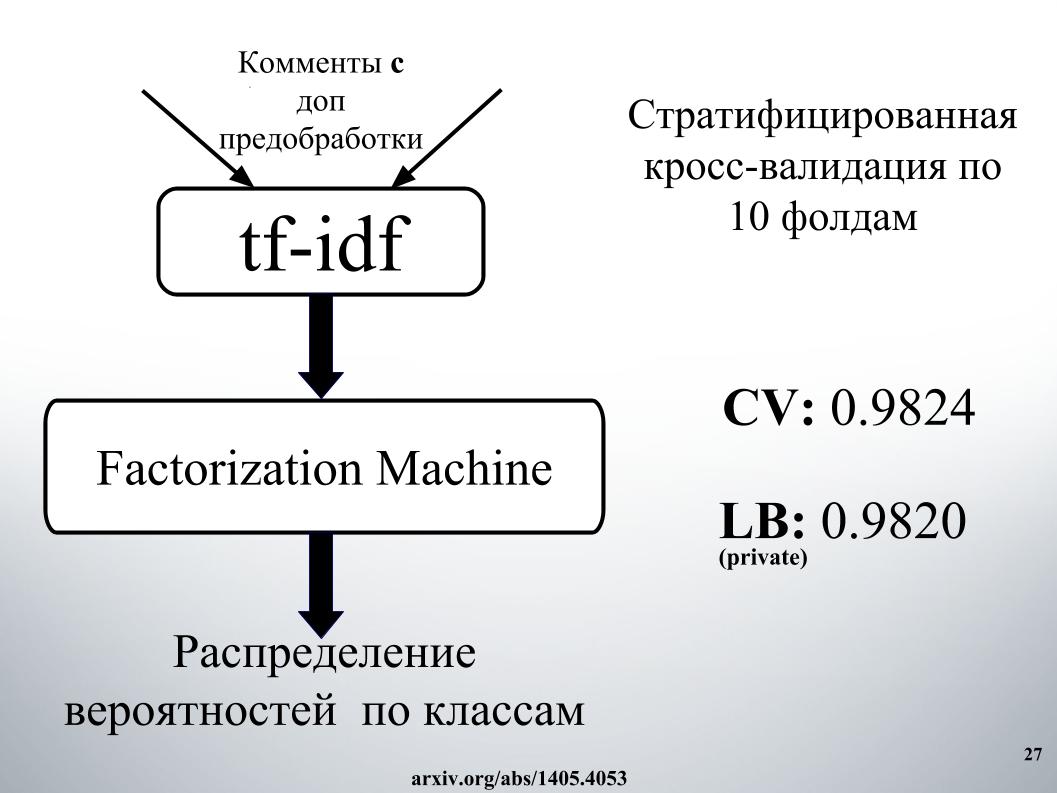
He had one of the best approaches, with which we stayed in the top 15 for a long time, until Alexey and Atanas joined us, he bleached blending and stacking it all. And also a very cool moment, which, as I understood, none of the teams used, we later made features from the results of the organizers API. About this will tell Alexey.
Alexey Noskov:
- Hello. I'll tell you about the approach that I used, and how we completed it.

Everything was simple enough for me: 10 folds of cross-validation, models pre-trained on different vectors with different preprocessing, so that they have more diversity in the ensemble, a little augmentation and two development cycles. The first one, which basically worked at the beginning, trained a certain number of models, looked at errors on cross-validation, on what examples it made obvious mistakes, and corrected the preprocessing on this basis, because it’s just clearer how to fix them.
And the second approach, which was used more at the end - taught some set of models, looked at correlations, found blocks of models that were weakly correlated with each other, strengthened the part consisting of them. This is the cross-validation correlation matrix between my models.
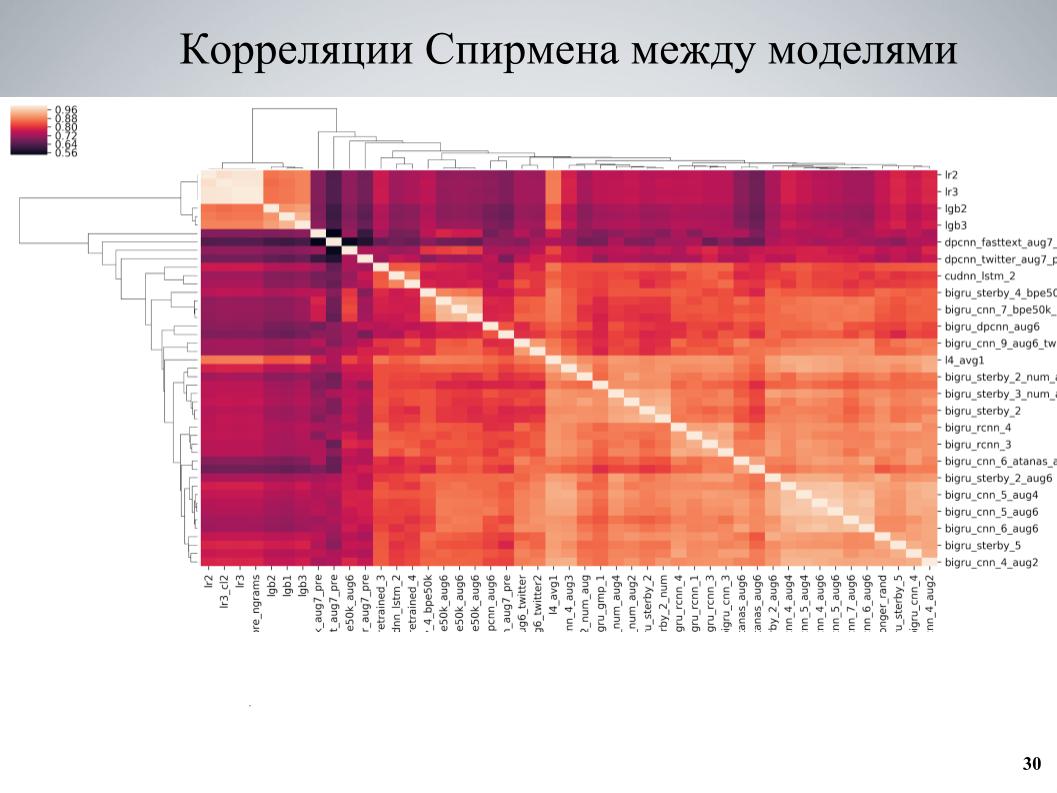
Here it can be seen that it has a block structure in places, while the models were of good quality, were poorly correlated with the others, and the fact that I took these models as a basis, taught several different variations of them differing in different hyper parameters or preprocessing, and then added to the ensemble.

For augmentation, the idea that Pavel Ostyakov published on the forum sparked the most. It was that we can take a comment, translate it into some other language, and then back. As a result of double translation, reformulation is obtained, something is lost a little, but on the whole, a similar, slightly different text is obtained, which can also be classified and thus expanded.
And the second approach, which did not help so much, but also helped, is that you can try to take two arbitrary comments, usually not very long, glue them together and take as a label on the target association of the labels or slightly tap where there is only one they contained a label.
Both of these approaches worked well, if they were not applied in advance to the entire train-set, but changed the set of examples to which the augmentation is applied to each epoch. Each era in the process of forming a batch we choose, say, 30% of examples, which are driven through translations. Rather, somewhere in advance somewhere in parallel is already in memory, we simply select the version for translation based on, and add it to the batch during its training.

An interesting difference was models trained in BPE. There SentencePiece - Google tokenizer, which allows you to split into tokens, which will not UNK at all. A limited dictionary in which any string is broken into some tokens. If in a real text the number of words is greater than the target size of the dictionary, they begin to break up into smaller pieces, and an intermediate approach is obtained between the character level and word level models.
It uses two basic construction algorithms: BPE and Unigram. For the BPE algorithm, it was easy enough to find predicted embeddings in the network, and with some fixed vocabulary — I just earned a good dictionary of 50k — you could still train models that were good (indiscernible — ed.), A little bit worse, than usual on fastText, but they were very poorly correlated with all the others and gave a good boost.
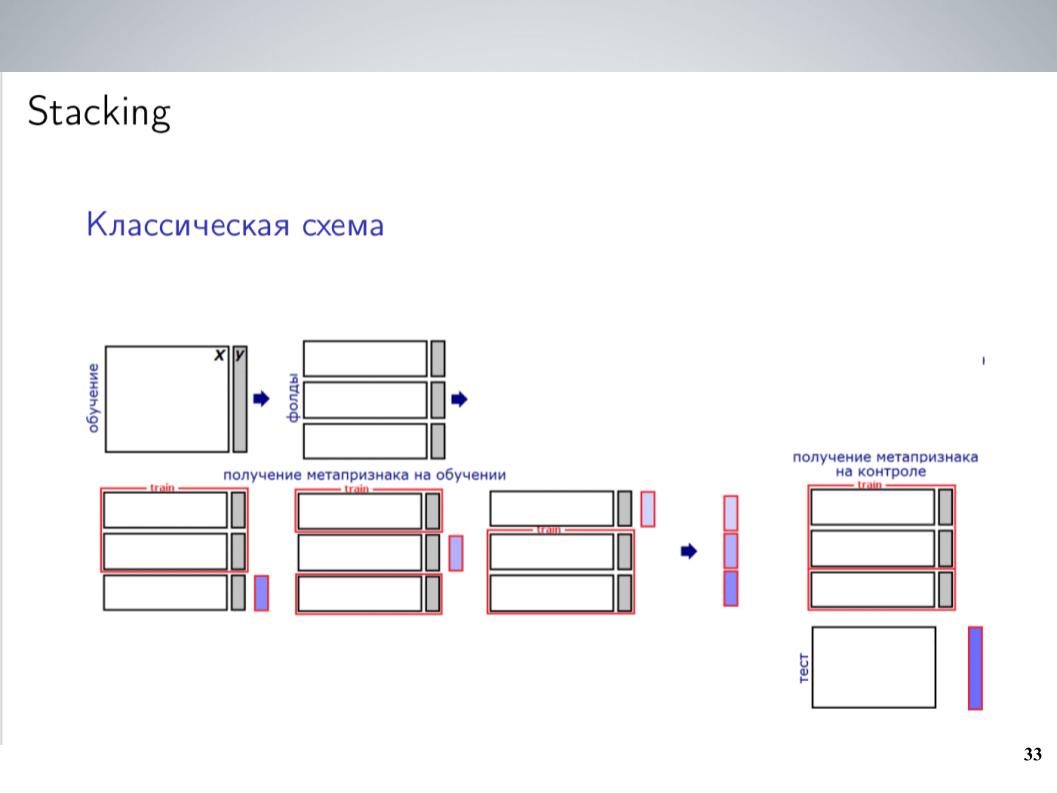
This is a classic stacking scheme. I, as a rule, used a blending of all my models without weights for most of the competition before the unification. This gave the best results. But after the merger, I was able to create a slightly more complicated scheme, which in the end gave a good boost.

I had a large number of models. Just throw them all in some kind of steker? It didn’t work very well, he retrained, but since the models were groups that were quite strongly correlated, I simply united them into these groups, within each group I averaged and received 5–7 groups of very similar models, from which as features for the next level used averaged values. He taught LightGBM on this, bagal 20 launches with different samples, threw away some meta-features in the same way that Atanas did, and in the end it finally began to work, to give some boost over simple averaging.

Most of all, in the end, I added the API that Andrew found and which contains a similar set of labels. The organizers built models for them initially. Since it was originally different, the participants did not use it, it was impossible to simply compare it with those that we needed to predict. But if it was thrown as meta-features into a well-functioning stacking, it gave a great boost, especially on the TOXIC class, which, apparently, was the most difficult on the leaderboard, and allowed us to jump to several places at the end, literally on the last day .

Since we found out that stacking and API work so well for us, before the final submission we doubted how well it would transfer to private. It worked very suspiciously well, so we chose two submissions by the following principle: one is a blend of models without an API that was obtained before, plus stacking with metafics from the API. It turned out 0.9880 in public and 0.9874 in private. Here I have confused the mark.

And the second is a blend of models without an API, without using stacking and without using LightGBM, since there were fears that this is some kind of small retraining for public, and we can go a long way with this. It didn’t go off, and in the end we got the tenth position with a score of 0.9876 to private. Everything.