
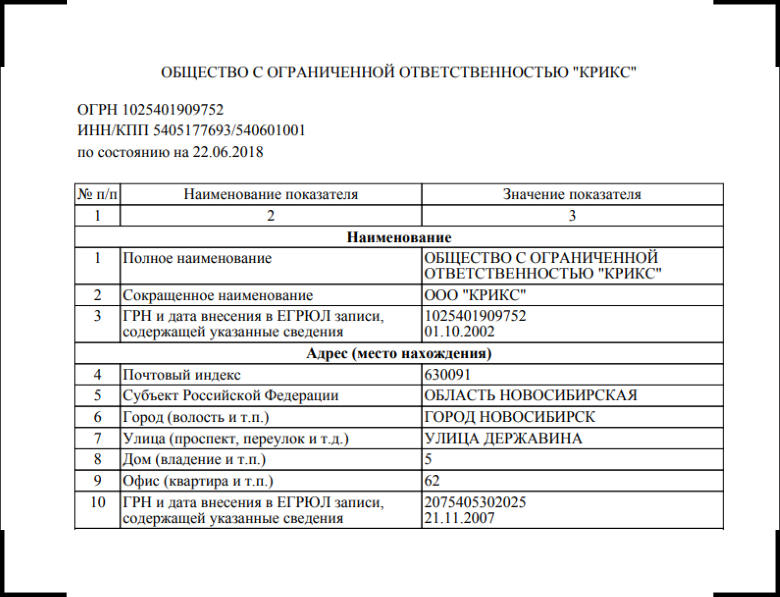
Last week we released
an article about the Incorporation
device - a state register with data of 10 million companies. That material talks about basic things, so it's better to start with it.
Here we will reveal a rich and fertile topic - problems of the Incorporation, which do not let our developers get bored.
Periodically, the xml structure breaks
In 2017, once every two or three months, updates brought xml files in the wrong format. There's a complete set: unknown tags, unclosed tags, data type mismatch. For example, the date type is specified in xsd, and in fact there is an incomprehensible line.
When this happens, it remains to write to tech support and wait humbly. Nothing more can be done. But I must admit that in 2018 there were no problems, everything is clear.
And in full unloading for 2015 lies the broken xml, which will never be fixed. The FTS said that they knew about it, but did not intend to repair it: take, say, the following updates.
Updates appear in folders of long-past dates.
Situation: you downloaded the full reference book for the beginning of 2018, applied all updates and roll updates every day. You are relaxed and undisturbed, because you know: your database contains the most current data on legal entities.
But you nevertheless missed one fact: tonight the Federal Tax Service not only released another update, but also planted new files in a folder three months old. Whose, your base is irrelevant.
Backdating updates are of two types:
- change existing files;
- add new ones.
To remove something, we have not seen.
We fight with all this here. In our local directory is the current data slice from the FTS server - the standard. Every night we download absolutely all the archives from the Unified State Registry server and compare with the standard.
New files are found clearly as: in the local directory they simply do not exist. If the file was, but the dates of its changes in the reference and new databases are different, compare the checksums. When they are different, take a new xml-ku and apply the update.
But there is a nuance! Sometimes in an update backdating comes irrelevant information, then it can not be used. Now there will be a slightly tangled example, watch your hands.
For example, on May 21, an update for Chamomile LLC was released. It lies in the folder
06/21/2018 . And on May 22, the Federal Tax Service put the file in the directory on
06/20/2018 , there is also something about “Chamomile” in it. This is something we will not touch. Although the new file is fresh, its content is irrelevant due to the update on May 21.
Records disappear between years
It would seem that if you take the archive
01 /
01 /2015_FULL and consistently roll all the updates for 2015, you will receive data from
01/ 01 /2016_FULL. And no!
The usual situation from our imperfect world:
- The whole of 2016 in the register is nothing about the company. Not in the full archive at the beginning of the year, nor in the updates.
- On 01/01/2017_FULL the company suddenly appears and lives quietly all year.
- And then bang - on 01/01/ 2018_FULL there is no company again. If you are lucky, later she will come in one of the updates, but it is not at all a fact.
About 1000 legal entities disappear from year to year.
 This wonderful LLC was lit up in the Unified State Register of Companies only once: in the update of 02/21/2017. The company is nowhere else, in any complete unloading.
This wonderful LLC was lit up in the Unified State Register of Companies only once: in the update of 02/21/2017. The company is nowhere else, in any complete unloading.Therefore, it will not be possible to take the full unloading at the beginning of the year and apply all updates until today. Excuse me to start in 2015, otherwise your Unables will be incomplete.
Xsd suddenly changes
A couple of times since 2015, the Federal Tax Service has suddenly changed xsd. It looks like this: the update comes, you try to disassemble it according to the old format, but nothing happens. Cheers up!
Tune out a new xsd - a matter of, in general, everyday. The problem is that no one warns of changes. Aerobatics is to post an ad in an arbitrary section on the FTS website, but usually there isn’t any. You will learn everything in fact.
It is not clear how to identify branches
As I said in the previous article, the branches in the Unified Statements Incorporation are not separate entries, they are attributes of legal entities. By law, branches and representative offices cannot exist on their own, which is why they are kept in the record of the main company.
But our customers have their own needs: they provide services to branches of other companies, sign common documents with them, and maintain branches in their accounting systems as separate entities. Because of this, we convert branches and representative offices from Incorporation into separate cards and link them to the main record.
Created branch cards need to be identified. The structure of the Incorporation provides for KPP, abbreviated name, full name, and even the name in Latin. But to make it more fun, the FTS is guaranteed to fill in only the address. How to show branches, not the same addresses to display.
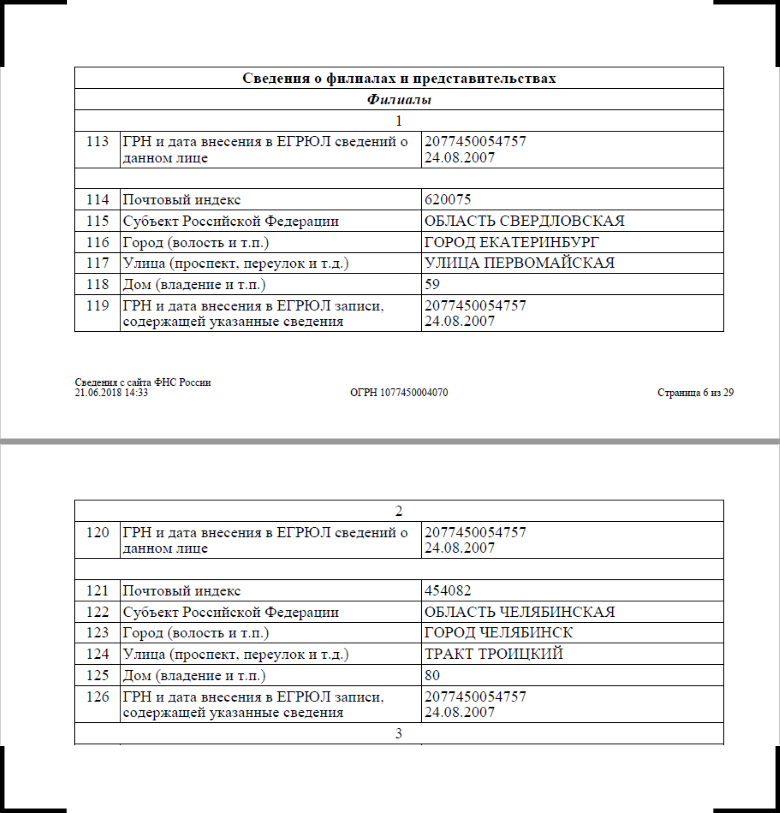 A typical example: branches in the unloading have nothing but an address
A typical example: branches in the unloading have nothing but an addressAt first, we still look in the field with an abbreviated name: suddenly there is something lying there. In 50% of cases, the field is really not empty, but even then it’s too early to rejoice: the name may be the same for all branches of a legal entity. As an identifier, this is no more useful than an empty field.
If the name of the branch is empty or non-unique, we create it ourselves.
For example, take all the same LLC "Daisy". It has three branches with empty names and such addresses:
- Moscow, Turchaninov Lane;
- Moscow, Ozerkovskaya Embankment;
- St. Petersburg, Nevsky Prospect.
We will take those data about the company, that is, and turn them into a sane name-branch identifier.
- Add the word “Branch” or “Division” to the name; for them, the Incorporated provides for various attributes.
- We include in the name of the short name of the main organization. Now we have three identical names “Branch Romashka LLC”.
- We take the addresses of branches and in brackets we will add to the names different parts of the addresses.
We attribute the address to the unique part: for the first two branches of “Chamomile” it is the full address, and for the third - only “St. Petersburg”. If all cities were different, they would add only cities to the names of branches.
In our example, the branches will turn out like this:
- “Romashka LLC” branch (Moscow, Turchaninov Lane) ”;
- "Branch Romashka LLC (Moscow, Ozerkovskaya Embankment)";
- “Branch Romashka LLC (St. Petersburg)”.
Yes, if a branch in the Unified State Register of Companies has a name, but a non-unique one, we skip the first two steps. We add the address part to this non-unique name.
Address for the name, we take a maximum to the street, because the hell begins with the home part like “dmvld 3, r. 5, pom. 14/51, of. 145 ". To disassemble this is difficult, but as part of the name of the branch it looks ridiculous. Therefore, branches located on the same street, we unite. There are even different branches in the same building! Fortunately, there are few.
Just take and connect the register will not work
In addition to these problems, the Unified Statements Register is full of errors at the level of symbols, addresses, and other trifles. For example, when instead of “LLC” you meet three zeros in the directory, it doesn’t even surprise you.
There are also addresses with errors, where without them. For example, “Leningrad” instead of “St. Petersburg” is a very significant case. A more down-to-earth version: the address of the organization Zheleznodorozhny of the Moscow Region is indicated as a city, although it has been around Balashikha for several years.
In fact, the reference book is all right, because the Unified Register of Legal Services stores the details of the constituent documents of the organization. But to work with the database, to search for it, the data must be brought to reality. Our users are looking for organizations located in St. Petersburg, and not once registered in Leningrad.
Therefore, parry the Unified Statements and get a base suitable for industrial exploitation is another task. Let me remind the volumes: if you take the complete reference book for the beginning of 2015 and all the updates until today, you get 100 million records.
For parsing the Incorporation, we wrote an algorithm: at the input it receives all the entries from 2015, and at the output it gives 10 million actual ones. Cope somewhere in an hour. An important part of the process is our
Single Client product. He puts the data in order: cleans addresses, finds duplicates, corrects typos.
If you like to parse complex reference books, structure the data and bring them to a human mind, come to us to work. Now we are looking for a javista for the “Factor” product. Salary - from 175 000 to 275 000 ₽, details - on hh.ru. And we also need QA: from 90,000 to 140,000 rubles for hands, details on the same hh .