Preprocessing is a general term for all manipulations performed on data before transferring their model, including centering, normalizing, shifting, rotating, cropping, etc. As a rule, preprocessing is required in two cases.
- Data cleansing . Suppose there are some artifacts in the images. To facilitate model learning, artifacts must be removed during the preprocessing stage.
- Supplement data . Sometimes small datasets are not enough for high-quality deep learning of the model. Approach with the addition of data is very useful in solving this problem. It is the process of transforming each sample of data in various ways and adding such modified samples to the data set. In this way, you can increase the effective size of the data set.
Let us consider some possible transformation methods for preprocessing and their implementation through Keras.

Data
In this and the following articles, a data set will be used to analyze the emotional coloring of images. It contains 1500 examples of images divided into two classes - positive and negative. Consider some examples.
 Negative examples
Negative examples Positive examples
Positive examplesCleaning transformations
Now consider the set of possible transformations that are commonly used to clean data, their implementation and the impact on images.
All code snippets can be found in the
Preprocessing.ipynb book.
Rescaling
Images are usually stored in RGB (Red Green Blue) format. In this format, the image is represented by a three-dimensional (or three-channel) array.
 RGB decomposition of the image. Chart taken from Wikiwand
RGB decomposition of the image. Chart taken from WikiwandOne dimension is used for channels (red, green, and blue), the other two represent a location. Thus, each pixel is encoded by three numbers. Each number is usually stored as an 8-bit unsigned integer type (from 0 to 255).
Rescaling is an operation that changes the numeric range of data by simply dividing it by a predetermined constant. In deep neural networks, it may be necessary to limit the input data to a range from 0 to 1 due to possible overflow, optimization issues, stability, etc.
For example, we will rescale our data from the range [0; 255] in the range [0; one]. Hereinafter, we will use the Keras
ImageDataGenerator class, which allows performing all transformations on the fly.
Create two instances of this class: one for transformed data, the other for source data:

(or for default data). You only need to specify the scaling constant. Moreover, the
ImageDataGenerator class allows you to stream data directly from a folder on your hard disk using the
flow_from_directory method.
All parameters can be found in the
documentation , but the main parameters are: the path to the stream and the target image size (if the image does not match the target size, the generator simply cuts it or increases it). Finally, we will get a sample from the generator and consider the results.
Both images are visually identical, but the reason is that the Python tools * automatically rescale the images.
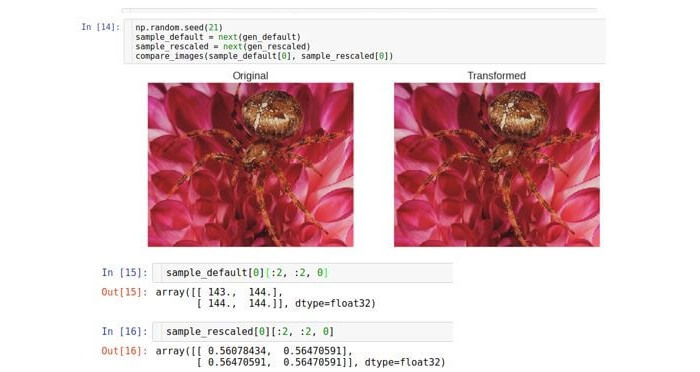
default range so that they can be displayed on the screen. Consider raw data (arrays). As you can see, raw arrays differ exactly 255 times.
Grayscale Translation
Another type of transformation that can be useful is a
conversion to shades of gray , which converts a color RGB image into an image in which all colors are represented by shades of gray. Conventional image processing can translate to grayscale in combination with a subsequent threshold setting. This pair of transformations can discard noisy pixels and determine the shapes in the image. Today, all these operations are performed by convolutional neural networks (CNN), but converting to shades of gray as a preprocessing stage can still be useful. Run this step in Keras with the same generator class.
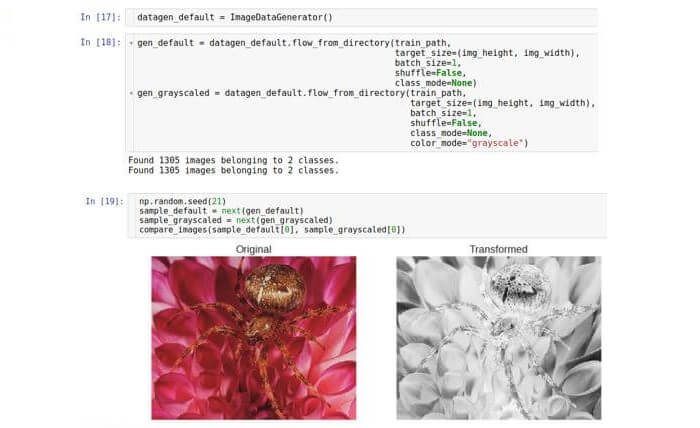
Here we create only one instance of the class and take two different generators from it. The second generator sets the
color_mode parameter to “grayscale” (default value is “RGB”).
Sample centering
We have already seen that the raw data values range from 0 to 255. Thus, one sample is a three-dimensional array of numbers from 0 to 255. In the light of the principles of stability optimization (getting rid of the problem of disappearing or saturating values), it
may be necessary to normalize the data set so that the average of each sample data is 0 .
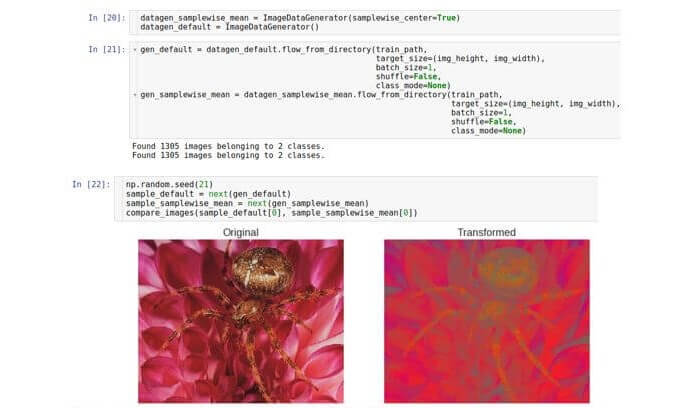
To do this, calculate the average value for the entire sample and subtract it from each number in the sample.
In Keras, this is done using the
samplewise_center parameter.
Normalization of SD of samples
This preprocessing stage is based on the same idea as centering the samples, but instead of setting the average to 0 from, it sets the standard deviation to 1.

Normalization of the MSE is controlled by the parameter
samplewise_std_normalization . It should be noted that these two methods of normalizing samples are often used together.
This transformation can be applied in deep learning models to increase the stability of optimization by reducing the effect of exploding gradient problems.
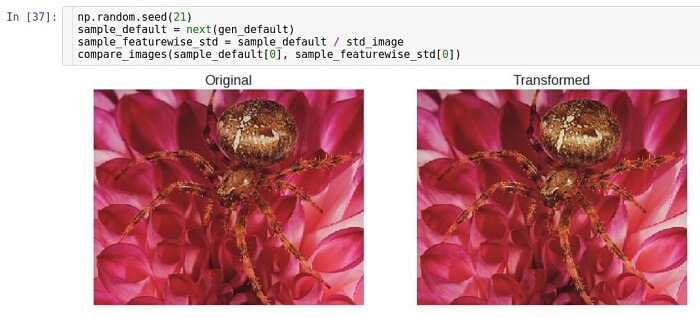
Feature centering
In the two previous sections, the normalization technique was used, examining each individual sample of data. There is an alternative approach to the normalization procedure. Consider each number in the image array as a sign. Then
each image is a feature vector . There are many such vectors in the data set; therefore, we can consider them as some unknown
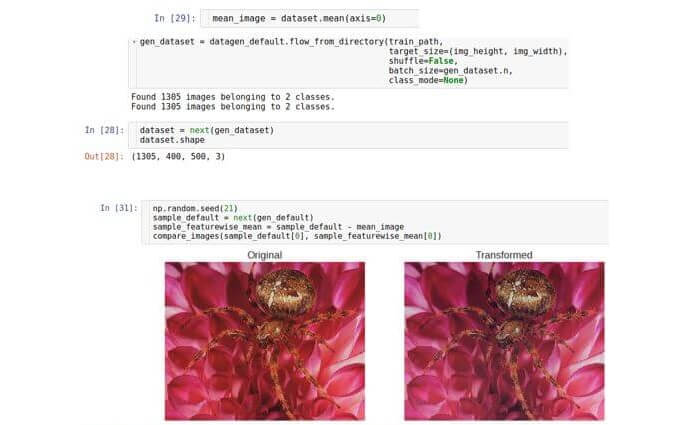
distribution . This distribution is multiparameter, and its dimension will be equal to the number of features, that is, width × height × 3. Although the true distribution of the data is unknown, you can try to normalize it by subtracting the average value of the distribution. It should be noted that the mean value is a vector of the same dimension, that is, is also an image. In other words, we average over the entire data set, and not over one sample.
There is a special Keras parameter called
featurewise_centering , but unfortunately, as of August 2017, there was an error in its implementation; therefore we implement it independently. First, we count the entire data set into memory (we can afford it, since we are dealing with a small data set). We did this by setting the packet size to be equal to the size of the data set. Then we calculate the average image over the entire data set and, finally, subtract it from the test image.
Normalization of RMS signs
The idea of normalizing the standard deviation is exactly the same as the idea of centering. The only difference is that instead of subtracting the average value, we divide by the value of the standard deviation. Visually, the result is not much different. The same was happening

when rescaling, since the normalization of the standard deviation is nothing more than rescaling with a specifically calculated constant, and for simple rescaling, the constant is specified manually. Note that a similar idea of normalizing data packets underlies the modern technology of deep learning, called
BatchNormalization .
Transformations with addition
In this section, we consider several transformations that are dependent on data that explicitly use the graphical nature of the data. These types of transformations are often used in data completion procedures.
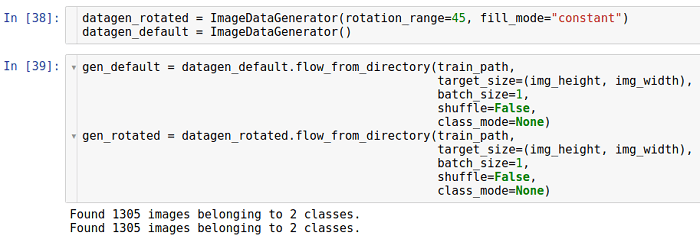
Rotation
This kind of transformation rotates the image in a certain direction (clockwise or counterclockwise).
The parameter that allows rotation is called
rotation_range . It indicates the range in degrees, from which a rotation angle is selected randomly with a uniform distribution. It should be noted that during rotation the image size does not change. Thus, some parts of the image can be cropped, and some filled.
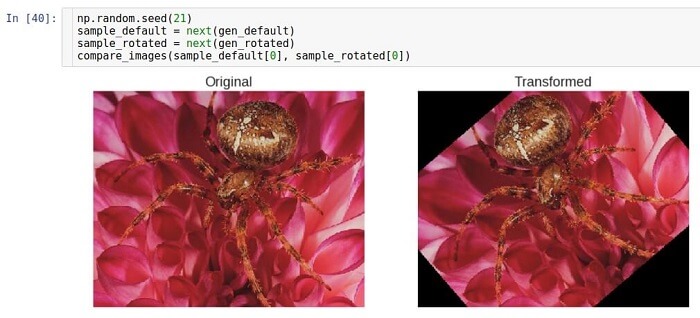
The fill mode is set using the
fill_mode parameter. It supports various ways of filling, but here we use the
constant method as an example.
Horizontal shift
This kind of transformation shifts the image in a certain direction along the horizontal axis (left or right).

The shift size can be determined using the
width_shift_range parameter and is measured as part of the full width of the image.
Vertical shift
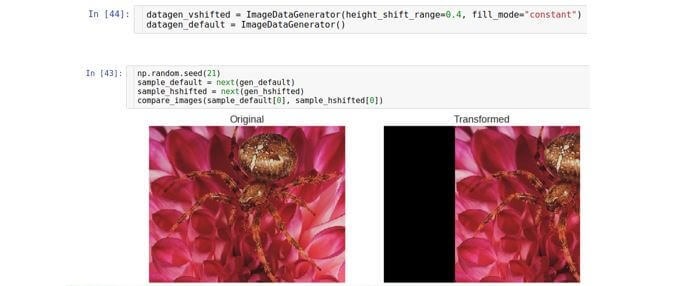
Shifts the image along the vertical axis (up or down). The parameter that controls the shift range is called the
height_shift generator and is also measured as part of the full height of the image.
Pruning
Converting a cropping or cropping shifts each point in the vertical direction by an amount proportional to the distance from that point to the edge of the image. Note that in the general case the direction does not have to be vertical and is arbitrary.
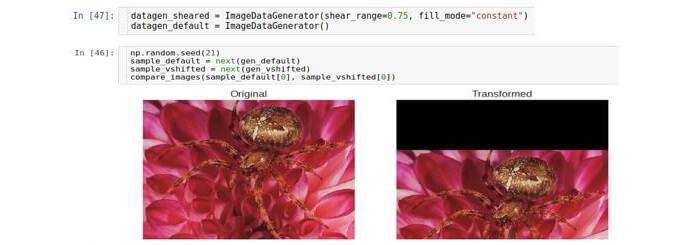
The parameter controlling the displacement is called
shear_range and corresponds to the deflection angle (in radians) between the horizontal line in the original image and the image (in the mathematical sense) of this line in the transformed image.
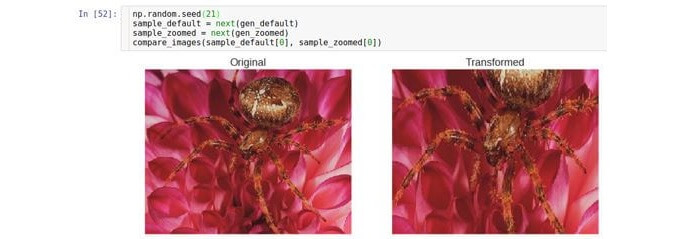
Approximation / removal

This type of transformation approximates or removes the original image. The
zoom_range parameter controls the zoom factor.
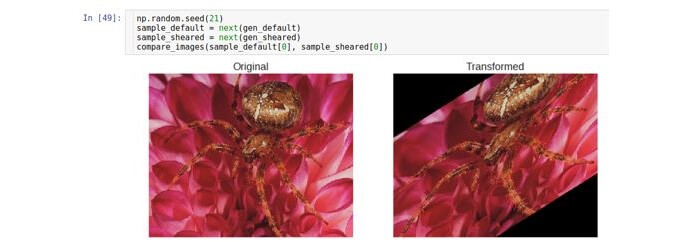
For example, if
zoom_range is 0.5, then the approximation factor will be selected from the range [0.5, 1.5].
Horizontal coup

Flips the image about the vertical axis. It can be turned on or off using the
horizontal_flip parameter.
Vertical coup

Flips the image about the horizontal axis. The
vertical_flip parameter (of type Boolean) controls the presence or absence of this transformation.
Combination
Apply all the described types of transformations of the add-on at the same time and see what happens. Recall that the parameters for all transformations are randomly selected from a specific range; thus, we must obtain a collection of samples with a considerable degree of diversity.
We initiate the
ImageDataGenerator with all the available parameters and check on the image of the red hydrant.

Note that the
constant filling mode was used only for better visualization. Now we will use a more advanced fill mode, called the
nearest ; this mode assigns the empty pixel the color of the nearest existing pixel.
Conclusion
This article provides an overview of the basic techniques for image preprocessing, such as: scaling, normalizing, rotating, shifting and cropping. They also demonstrated the implementation of these transformation techniques with the help of Keras and their introduction into the process of deep learning, both technically (class
ImageDataGenerator ) and ideologically (data supplement).