
Hi, Habr! My name is Alexey Pristavko, I am the director of web projects in the company DataLine. My article today is about fixing or preventing back-end performance problems with web applications.
It’s about how to optimize web applications that suffer from chronic scalability, performance, or reliability issues.
All interested - welcome under the cat!
Terminology
Let's first understand the terminology. Speaking about the performance of web projects or web systems, I primarily mean the back-end and server component. What happens when loading pages in the browser is a completely different story, which, most likely, I will devote to a separate article.
- The measure of application performance will be the number of processed requests per second (RPS) and the speed of their execution (TTFB - Time to First Byte).
- Accordingly, under the scalability of the system we will understand the pool of possibilities for increasing the RPS.
Now about reliability. Here it is necessary to separate two concepts: fault tolerance and disaster recovery.
- Resistance to failures - the ability of the system in case of failure of one or several servers to continue working within the required parameters.
- Systems that have a full redundant backup (the so-called second leg) and are capable of working without a strong drawdown with the complete failure of one of the data centers are considered to be resistant to disasters .
At the same time, a disaster-proof system is a fault-tolerant system. The situation in which a disaster-resistant, but not fail-safe system continues to work only on one "shoulder" is quite normal. But if one of the servers fails, the system will also fail.
Now that we’ve dealt with key concepts and refreshed current terminology, it’s time to go directly to the basics of optimization and life hacking.
How to start optimization

How to understand where to start optimization? Before you rush to optimize, take a deep breath and take the time to research the application.
Be sure to draw a detailed scheme. Display on it all the components of the application and their relationships. By examining this scheme, you will be able to detect previously inconspicuous vulnerabilities and potential points of failure.
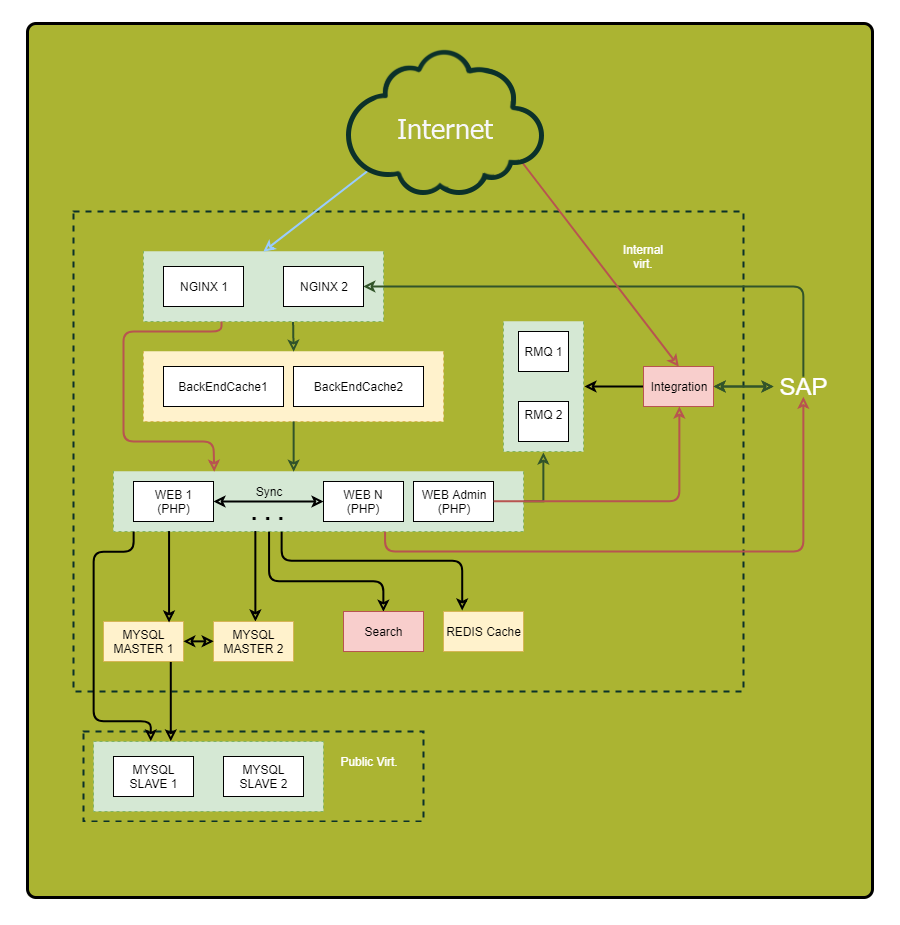
"What? Where? When? ”- we optimize queries
Pay special attention to synchronous requests. Let me remind you, these are such requests, when we send a request in the same stream and wait for an answer on it. This is where the causes of serious brakes lie, when something goes wrong on the other side. Therefore, if you can reduce the number of synchronous requests or replace them with asynchronous ones, do it.
Here are some little tricks to help you track down requests:
- Assign a unique identifier to each incoming request. Nginx has a built-in variable $ request_id for this. Transfer the identifier in the headers to the back-end and write to all logs. So you can conveniently trace requests.
- Log not only the end of the request to the external component, but also its beginning. So you measure the actual duration of the external call. It may differ significantly from what you see in the remote system, for example, due to network problems or DNS brakes.
So, the data is collected. Now we will analyze the problem points. Define:
- Where is the most time spent?
- Where does most requests go?
- Where are the most "long" requests?
As a result, you will receive a list of the most interesting parts of the system for optimization.
Tip: If a point “collects” many small queries, try combining them into one big query to reduce overhead. Long query results often make sense to cache.
Cache wisely
There are general caching rules that you should rely on when optimizing:
- The closer the cache to the consumer, the faster the work. For the application, the “closest” place will be RAM. For the user - his browser.
- Caching speeds up data acquisition and reduces the load on the source.
If ten web servers make the same database queries, a centralized intermediate cache, such as Redis, will give a higher percentage of hits (compared to the local cache) and reduce the overall load on the database, which will significantly improve the overall picture.
Tip 1: Make component caching of the finished page on the Nginx side using Edge Side Includes. It fits well with the microservice / SOA architecture and offloads the system as a whole, greatly improving the response speed.
Tip 2: Keep track of the size of objects in the cache, the hit ratio and the volume of write / read. The larger the object, the longer it will be processed. If you write to the cache more often or more than you read, such a cache is not your friend. It should either be removed, or to think about improving its effectiveness.
Tip 3: Use your own database caches, wherever possible. Their proper configuration can speed up the work.
Load profiles
Go to the load profiles. As you know, there are two main types: OLAP and OLTP.
- For OLAP (Online Analytical Processing), the amount of traffic spent per second is important.
- For OLTP (Online Transaction Processing), the key indicator is the response speed, millisecond timings.
Most often it is effective to separate these two types of load. At a minimum, you will need separate tuning of the database and, possibly, other components of the system.
Tip: Requests for reading from the admin are usually processed as OLAP. Create a separate copy of the database and a web server for this task to unload the main system.
Database

So, we naturally came to one of the most difficult stages of optimization - namely, to optimize the database.
Let me remind you a general rule: the smaller the base, the faster it works. The organization of the database itself is crucial when it comes to speed.
If possible, store
historical data , application logs and
frequently used data in different databases. Even better, post them to different servers. This will not only facilitate the life of the main database, but also give more space for further optimization, for example, in some cases it will allow using different indices for different loads. Also, the “uniformity” of the load simplifies the life of the database server's scheduler and optimizer.
And again about the importance of planning.
In order not to puzzle over the optimization where it is not much needed, choose the iron, based on the tasks.
- For smaller, but frequent requests, it is better to take more processor cores.
- Under heavy requests - fewer cores with higher clock speeds.
Try to put the working volume of the database in RAM. If this is not possible or there is a large number of write requests, it’s time to look in the direction of transferring databases to SSD disks. They will give a significant increase in the speed of work with the disk.
Scaling

Above, I described the key mechanics of increasing application performance without increasing its physical resources.
Now we will talk about how to choose a scaling strategy and increase resiliency.
There are two types of system scaling:
- vertical - the growth of resources while maintaining the number of entities;
- horizontal - growth in the number of entities.
We grow in height
Let's start by choosing a vertical scaling strategy.
To begin, consider the
increase in system power . If your system is running under one server, you will have to make a choice between increasing the capacity of the current server or buying another one.
It may seem that the first option is simpler and safer. But it will be more far-sighted to purchase another server and get a greater fault tolerance as a performance bonus. I spoke about this at the beginning of the article.
If there are several servers in your system and there is a choice - to increase the capacity of existing ones or to purchase some more, pay attention to the financial side. For example, one powerful server may be more expensive than two 50% “weaker”. Therefore, it is reasonable to dwell on the second compromise. At the same time, with a large number of servers, the ratio of performance, power consumption and cost of a full rack is crucial.
We grow in width
Horizontal system scaling is a story about fault tolerance and clustering. In general, the more instances of one entity we have, the higher the resiliency of the whole solution.
Probably the first thing you want to scale is
application servers . The first obstacle on this path is the organization of work with centralized data sources. In addition to databases, it is also session data, and static content. Here's what I advise you to do:
- To store sessions, use Couchbase, rather than the familiar Memcached, since it works with the same protocol, but, unlike memcached, supports clustering.
- All statics , especially large amounts of images and documents, are stored separately and given away using Nginx, and not from the application code. So you will save on flows and facilitate the management of infrastructure.
"Tightening" the database
The most difficult to scale database. There are two main techniques for this: sharding and replication. Consider them.
When
replicating, we add completely identical copies of the database to the system; when
sharding , we add logically separated parts, shards. At the same time, it is extremely desirable to carry out sharding in parallel with replication (replication) of each shard, so as not to lose fault tolerance.
Remember: often a database cluster consists of a single master node that accepts a write stream and several slaves used for reading. In terms of fault tolerance, this is slightly better than a single server, since overall fault tolerance is determined by the least stable element of the system.
Schemes with more than two database wizards (the “ring” topology) without confirming the record on each of the servers, very often suffer from inconsistency. In case of failure of one of the servers, it will be extremely difficult to restore the logical integrity of data in the cluster.
Tip: If in your case it is not rational to have several master servers, consider the architectural possibility of operating the system without a master for at least one hour. In the event of a crash, this will give you time to replace the server without idle the entire system.
Tip: If there is a need to keep more than 2 database wizards, I recommend that you consider NoSQL solutions, since many of them have built-in mechanisms for bringing data into a consistent state.
In pursuit of fault tolerance, in no case do not forget that replication insures you
only against a physical server failure . It will not save from logical data corruption due to user error.
Remember: Any important data must be backed up and stored as an independent, non-editable copy.
Instead of conclusion
Finally - a couple of tips about performance when creating backups:
Tip 1: Remove data from a separate database replica, so as not to overload the active server.
Tip 2: Have an extra, slightly time-lagged database replica on hand. In the event of an accident, this will help reduce the amount of data lost.
The methods and techniques cited in this article can in no case be applied blindly, without analyzing the current situation and understanding what you would like to achieve. You may encounter “re-optimization”, and the resulting system will be only 10% faster, but 50% more vulnerable to accidents.
That's all. If you have any questions, I will be happy to answer them in the comments.