Telling what caches are, what is Result Cache, how it is made in Oracle and in other databases is not very interesting and quite standard. But everything acquires completely different colors when it comes to specific examples.
Alexander Tokarev (
shtock ) built his report on Highload ++ 2017 based on case studies. And it was relying on cases that told me when a homemade cache could be convenient, what a pain server-side Result Cache was and how to replace it with a client one, and generally brought out some useful tips on setting up Result Cache in Oracle.
About the speaker: Alexander Tokarev works for DataArt and deals with issues related to databases both in terms of building systems from scratch and optimizing existing ones.
Let's start with a few rhetorical questions. Have you worked with Oracle Result Cache? Do you believe that Oracle is a database, convenient for all cases? According to Alexander’s experience, most people answer the last question in the negative,
one hundred dour pragmatists account for one dreamer But thanks to his faith, progress is moving.
By the way, Oracle already has 14 databases - so far 14 - what will happen in the future is unknown.
As already mentioned, all problems and solutions will be illustrated with specific cases. This will be two cases from DataArt projects, and one third-party example.
Database caches
To begin with, what are the caches in the databases. Everything is clear here:
- Buffer cache - data cache - cache for data pages / data blocks;
- Statement cache - cache of statements and their plans - cache of queries plan;
- Result cache - cache of row results - rows from queries;
- OS cache - operating system cache.
And Result cache, by and large, is used only in Oracle. He was once in MySQL, but then he was heroically cut out. In PostgreSQL, it also does not exist, it is present in one form or another only in the third-party product pgpool.
Case 1. Retailer's vault
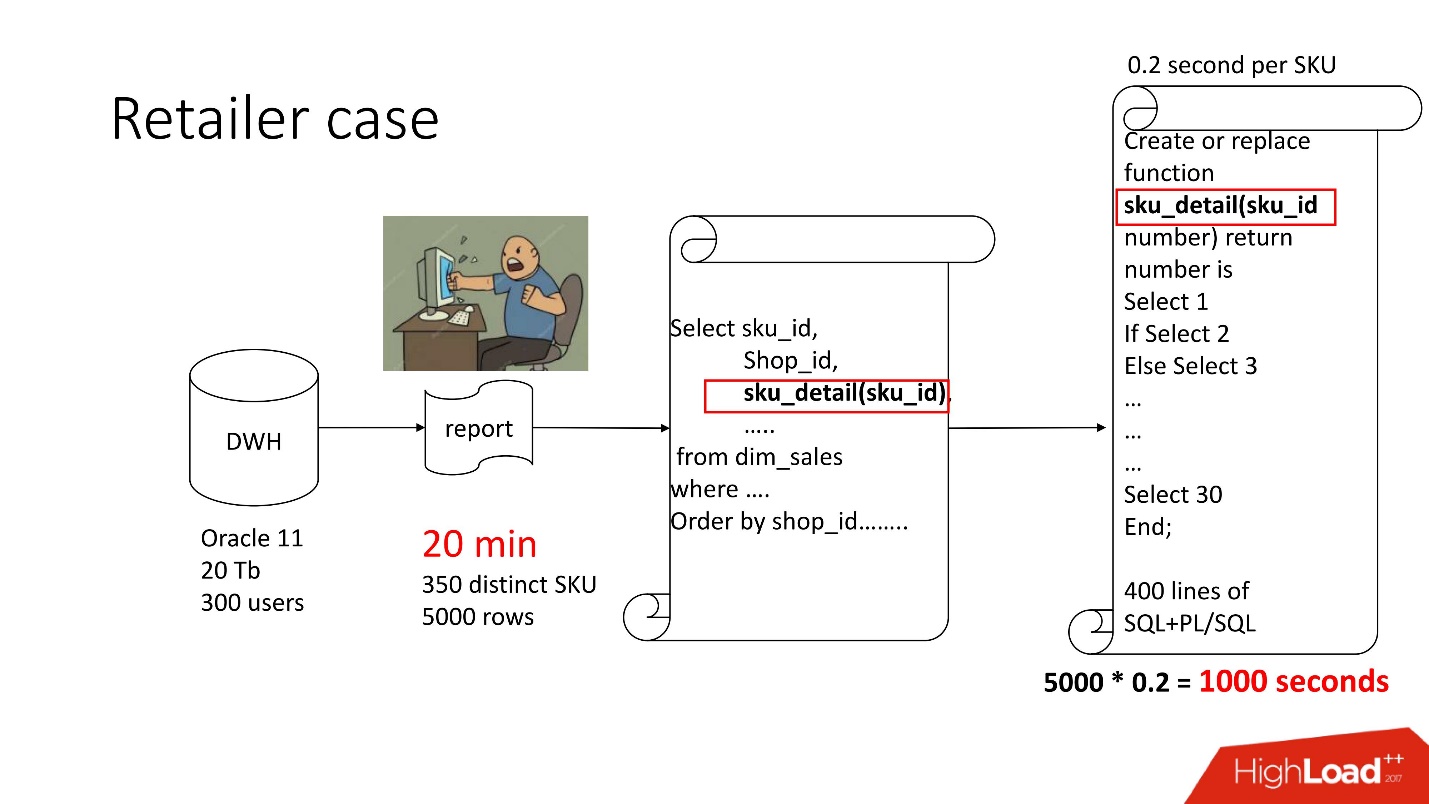
Above is the product schema that we had on maintenance - a repository (Oracle 11, 20 Tb, 300 users), and there is some dreary report in which there were 350 unique products for 5,000 data lines. It took about 20 minutes to get it, and users were sad.
The presentation of this report, like all the others, is posted on the Highload ++ conference website.
This report has SELECT, JOINs and a function. The function as a function, everything would be fine, only it calculates a mysterious parameter, which is called “transfer pricing value”, it works 0.2 seconds - like nothing, but it is called as many times as there are rows in the table. This function has 400 SQL + PL / SQL lines, and since product on support, change it scary.
For the same reason, result_cache could not be used.
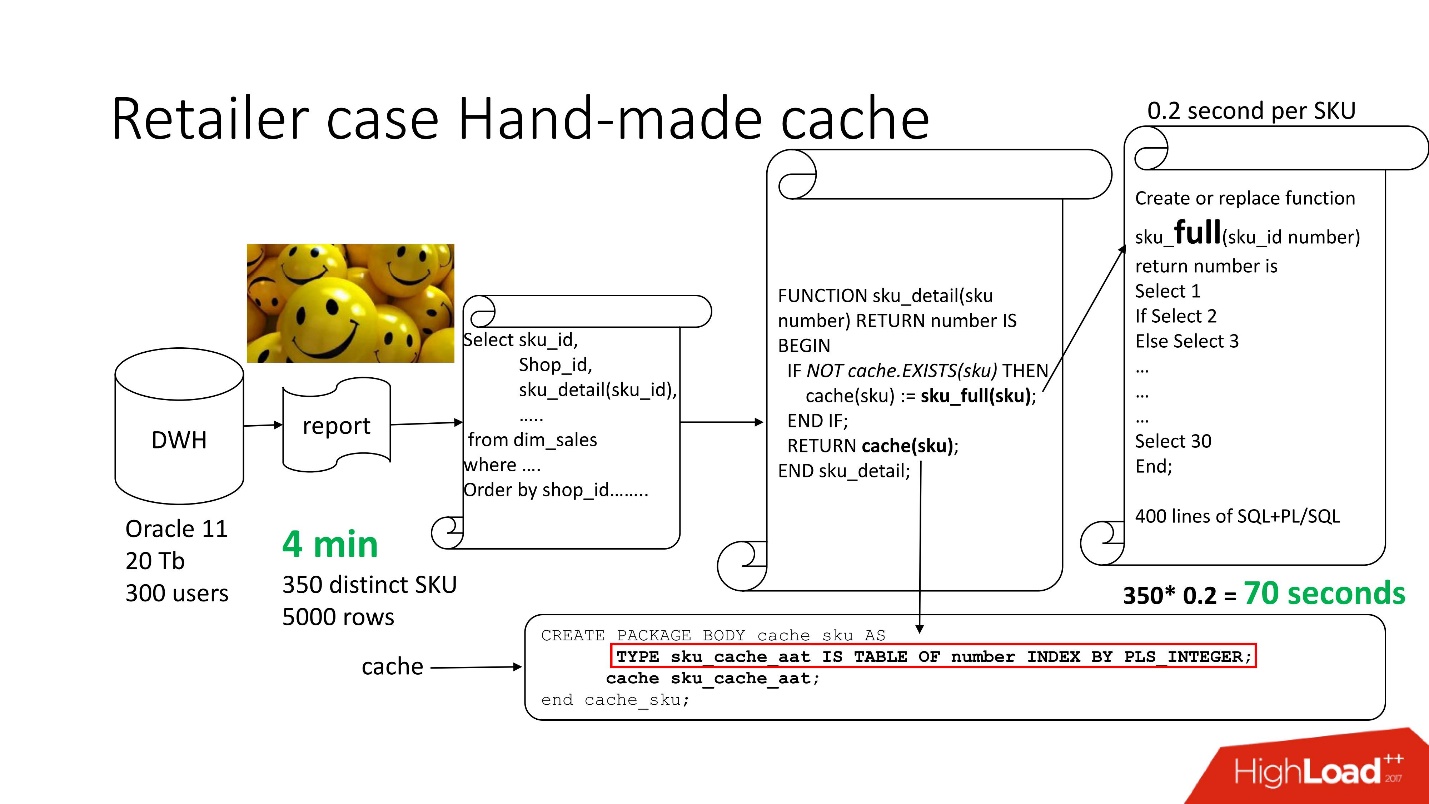
To solve the problem, we use the standard
approach with hand-made caching : the first 3 blocks of the scheme are left, as it were, our function sku_detail () is simply renamed to sku_full () and we declare an associative array, where respectively:
- the keys are our SKUs (commodity items),
- values is the calculated price of the transfer conversion.
We make an obvious cache (sku) function: if there is no such id in our associative array, our function starts, the result is cached, saved and returned. Accordingly, if there is such an id, then all this does not happen. In fact, we got
on demand cache .
Thus, we have reduced the number of function calls to the number that is actually needed.
Report processing time decreased to 4 minutes , all users felt good.
Hand-made Cache Memory
The disadvantages and advantages of this system are clear from this big smart picture, to which we will address a lot - this is the memory architecture.
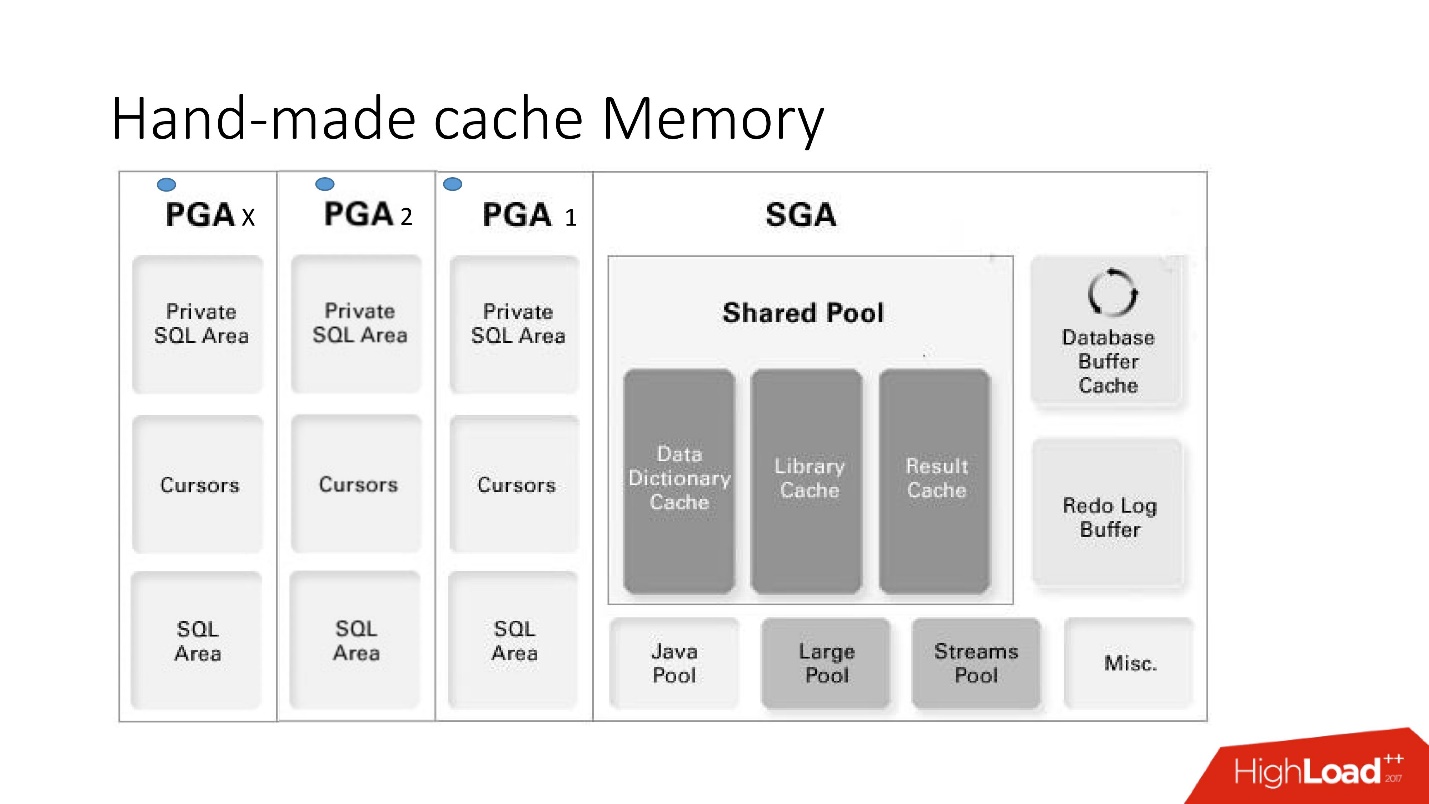
It is important to understand in which of the memory areas the collections are located. They are placed in a memory area called PGA.
Program global area is instantiated for each database connection. This is what determines the advantages and disadvantages, because more connections are more memory, and
memory is expensive, server-side , admins are gentle.

- Pros: everything works very quickly, it is very easy to do, there is no need to configure, there are no problems with inter-process activation.
- The disadvantages are clear: if the stored logic is prohibited in the project, they cannot be used, there is no automatic invalidation mechanism, and since the cache memory is allocated within one database session and not an instance, then its consumption is overestimated . Moreover, in the case of the connection pool use case, one should not forget to reset the caches, if for each session the caching should be different.
There are other options for hand-made caches based on materialized views, temporary tables, but they are heavy on the I / O system, so we don’t consider them here. They are more applicable to other databases, in which usually similar problems are solved by the fact that the stored procedure materializes in some kind of intermediate table and, before addressing a heavy query, data is taken from it. And only if the necessary one was not found there, then the original request is called.

The above is an illustration of this approach to caching to get a list of related products in MsSQL. In general, the approach is relatively similar, but it does not work in the database memory in terms of both data acquisition and initial filling, due to this it
can be slower .
In general, self-made result_cache are widely used, but in-database result_cache is another approach to the implementation of this task. It and how it did not work out a quick win, we will look further.
Case 2. Processing financial records
So, our second case.
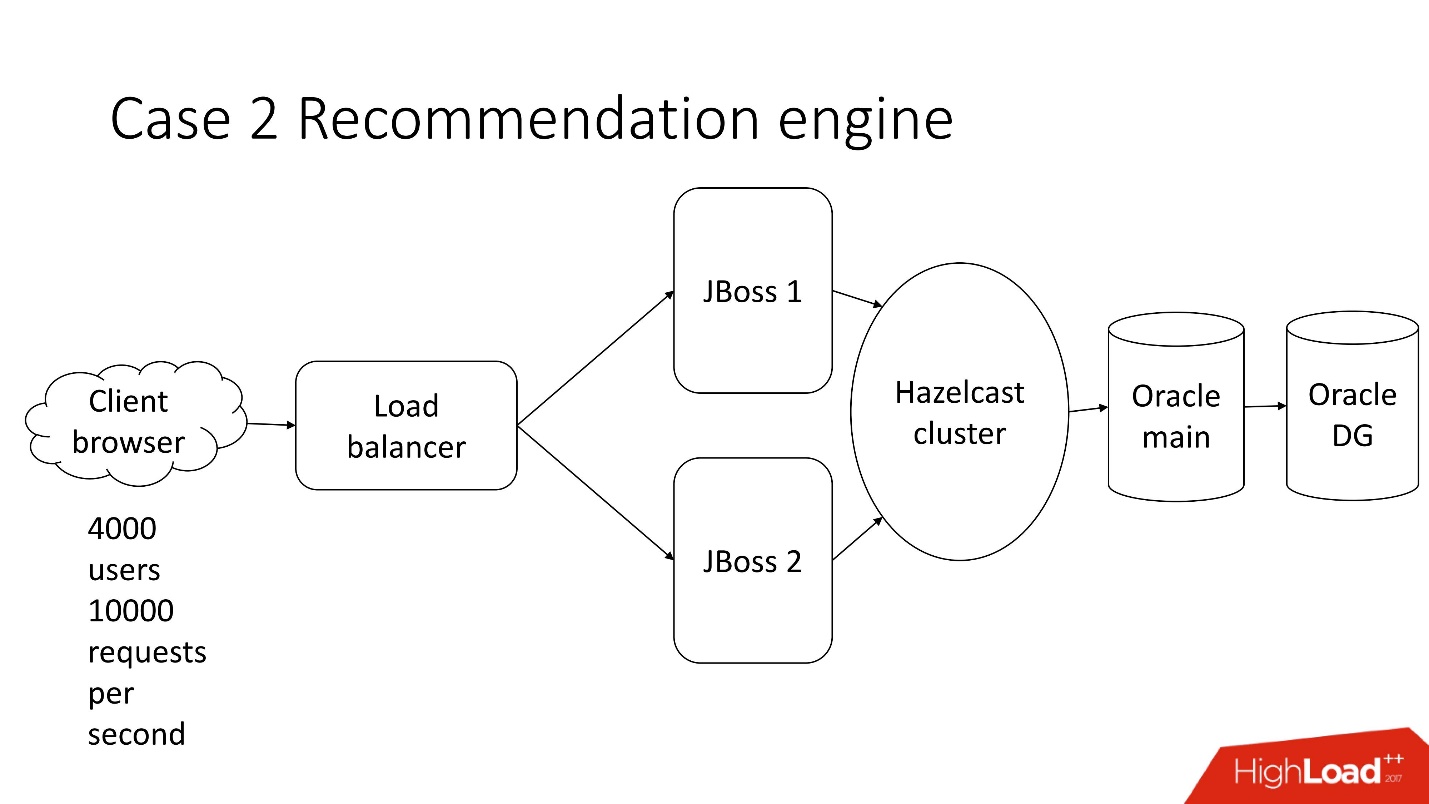
This is a system of semi-automated processing of financial documentation - a dreary enterprise with a classical architecture, which includes:
- thin client;
- 4000 users who live in different parts of the globe;
- balancer;
- 2 JBoss for calculating business logic;
- in-memory cluster;
- core Oracle;
- backup instance of Oracle.
One of the many tasks of this system is the
calculation of recommendations .

There are documents, for each indicator that is not automatically recognized by the system, a set of indicators is offered either from previous client documents, or from a similar industry, or for similar returns, and the indicator is compared with the recognized value so as not to offer too much. What is important, the
documents are multilingual .
The user selects the desired value and repeats the operation for each blank line.
Simplified, this task consists in the following: documents are received in the form of key-value pairs from different recognition systems, and somewhere the parameters are recognized, and somewhere not. It is necessary to make so that as a result users processed documents and all values became recognized. The recommendation is aimed at simplifying this task and takes into account:
- Multilingual - about 30 languages. Each language has its own stemming, synonyms and other features.
- Previous data from this customer, or, in the case of their absence, customer data from the same industry or a similar customer.
In fact, it is about 12 very complex rules.
Initial assumptions:- Not more than 100 users at the same time;
- 2-3 columns for recognition;
- 100 lines.
No highload at all - everything is boring.
So, it's time to release. Code freeze happened, everyone is afraid to touch Java, and it takes at least 5 minutes to process the document.
They come to the database development team for help. Of course, because
if something slows down in the JVM, then of course, you need to change or repair the database .

We studied the documents and realized that in key-value pairs, the values are often repeated - 5-10 times. Accordingly, we decided to use the database to cache, because it has already been tested.
We decided to use the Oracle server-side Result Cache because:
- SQL optimization opportunities have been exhausted because it uses the Oracle full text search engine;
- cache will be used for duplicate parameters;
- most of the data for recommendations is recalculated once an hour, as they use the full-text index;
- PL / SQL is not allowed .
Oracle Result Cache
Result cache - a technology from Oracle for caching results - has the following properties:
- this is the memory area in which all the results of the queries are collided;
- read consistent, and it is automatically disabled;
- A minimum number of changes to the application is required. You can make it so that the application does not need to be changed;
- bonus - you can cache PL / SQL logic, but it is forbidden here.
How to turn it on?Method number 1
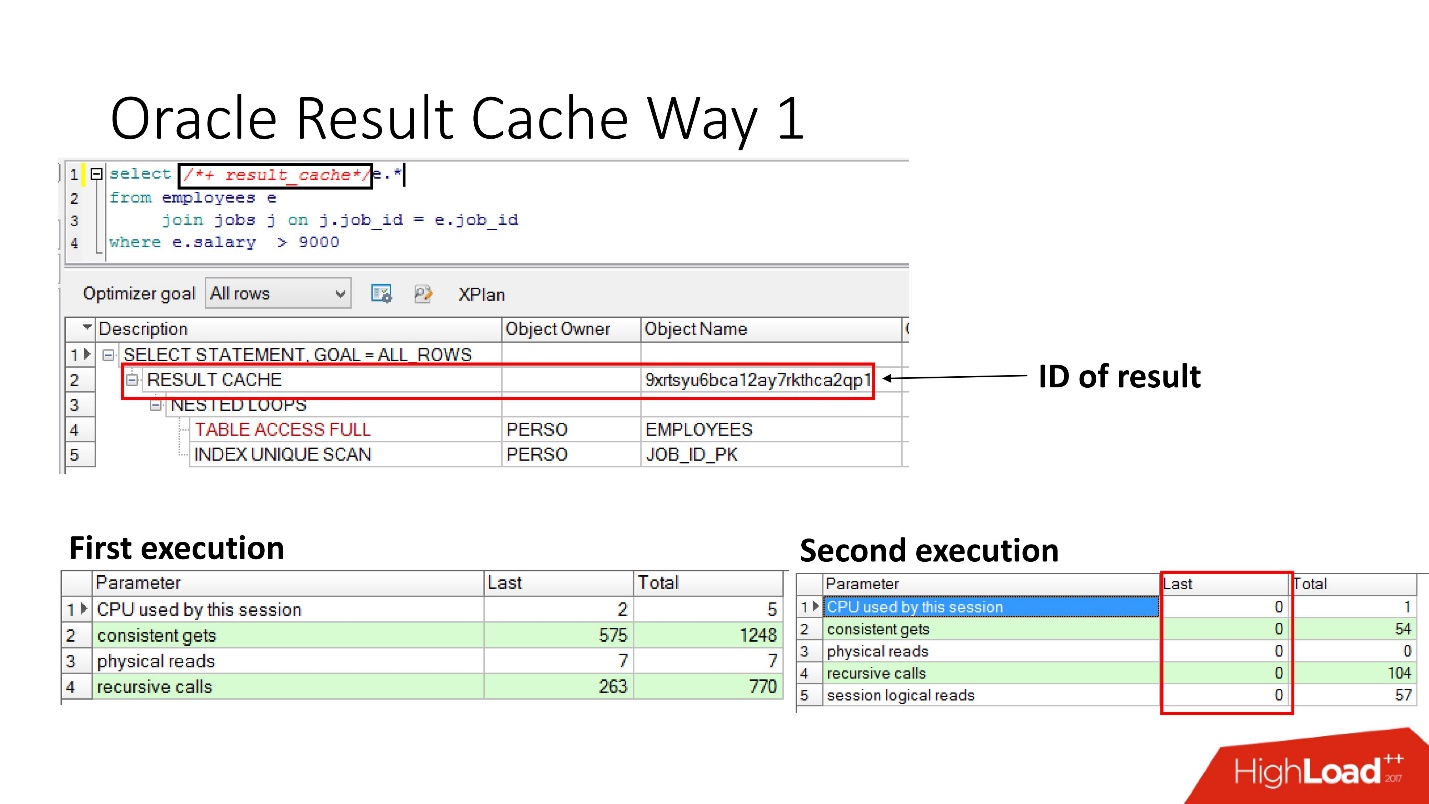
Very simple -
specify the instruction result_cache . The slide shows that the result identifier has appeared. Accordingly, the first time the query is executed, the database will do some work, with the subsequent execution in this case no work is needed. All is well.
Method number 2
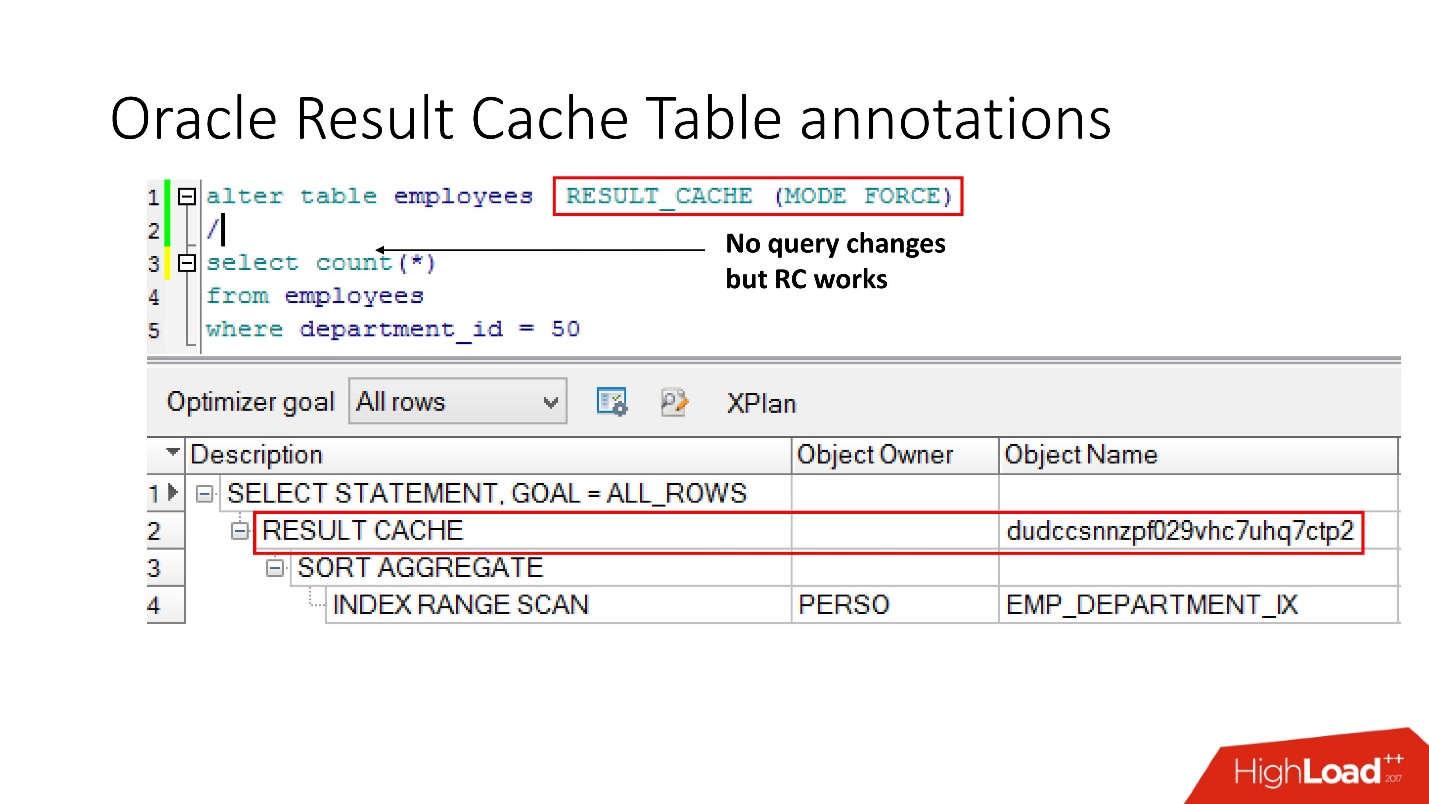
The second way allows application developers to do nothing is the so-called annotations. We specify for the table a check mark that the request to it should be placed in result_cache. Accordingly, there is no hint, the application is not touched, but everything is already in result_cache.
By the way, what do you think, if the query refers to two tables, one of which is marked as result_cache, and the second is not, will the result of such a query be cached?
The answer is no, not at all.
In order for it to be cached, all tables participating in the query must have result_cache annotation.
Dependency Tracking
There are corresponding ideas in which you can see what the dependencies are.
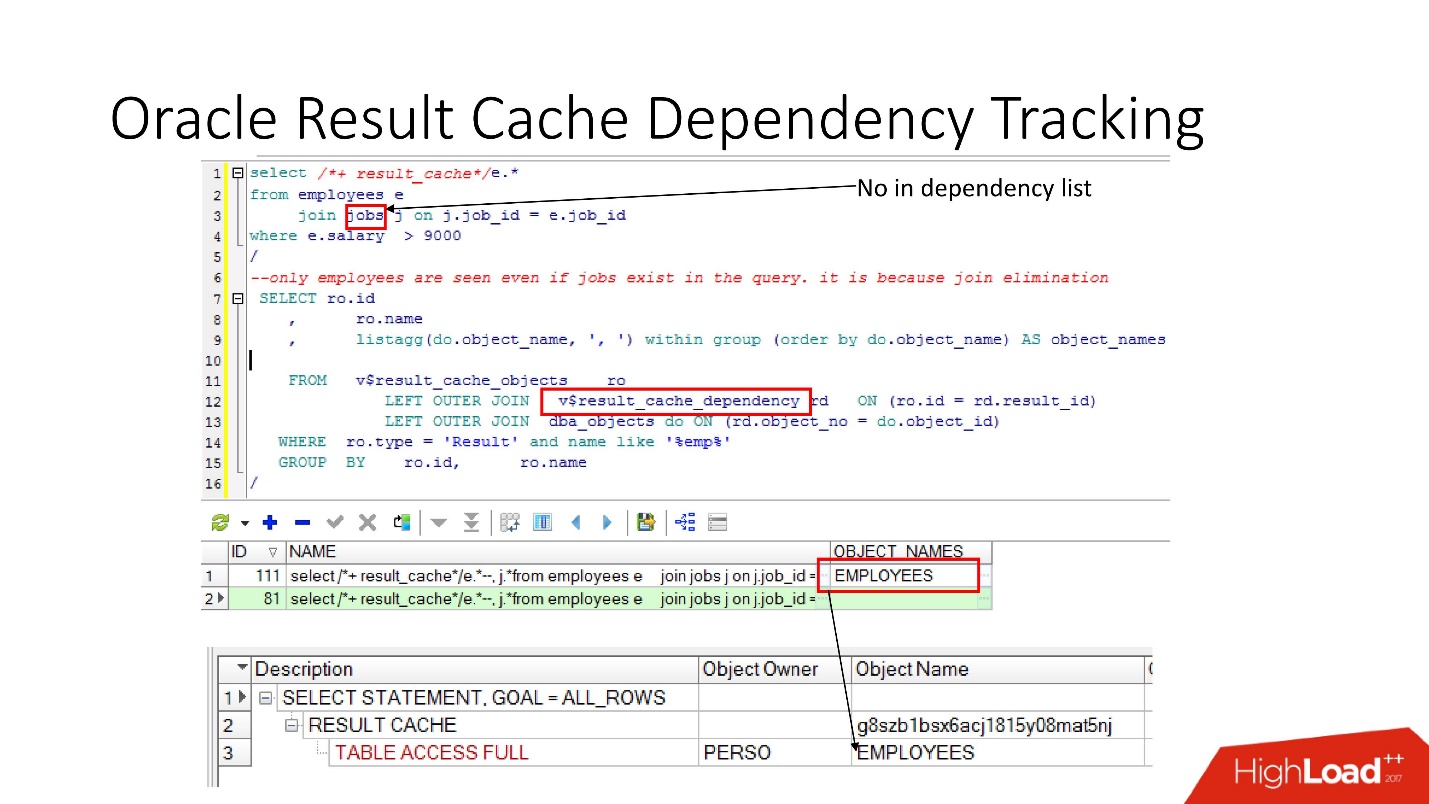
In the example above, a JOIN query is some kind of table in which there is one dependency. Why? Because Oracle defines dependency not just by syntactic analysis, but implements it
according to the results of the work execution plan .
In this case, such a plan is chosen, because only one table is used, and in fact the jobs table is connected to the employees table via foreign key constraint. If we remove the foreign key constraint, which allows us to do this join elimination transformation, we will see two dependencies, because the plan will change this way.
Oracle does not keep track of what should not be tracked .
In PL / SQL, dependency works at run-time so that you can use dynamic SQL and other things to do.
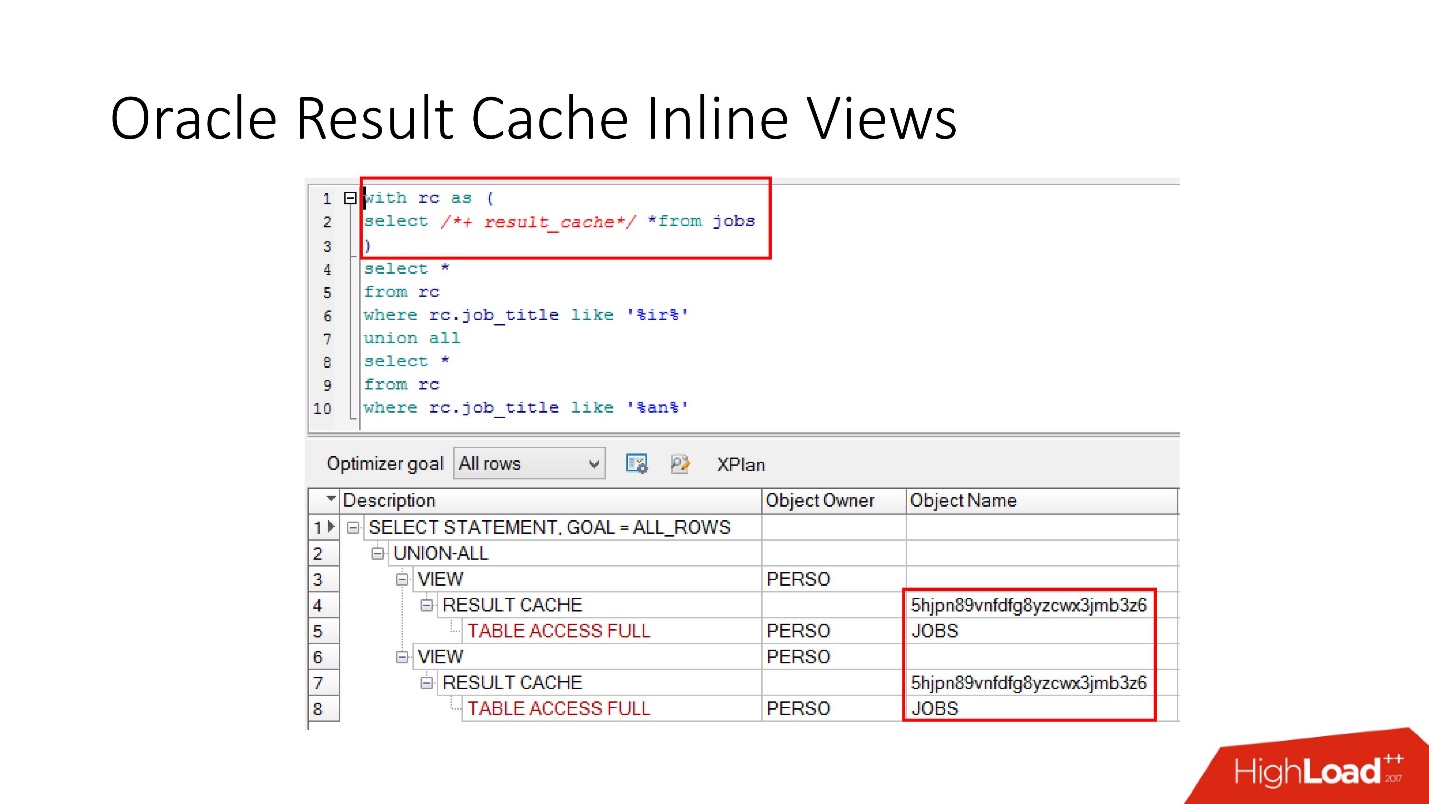
Note that not only the entire request
can be cached ,
you can cache the inline view both in the with view and in the from view . Suppose for some one we need a cache, and another would be better to read from the database so as not to strain it. We take the inline view, again declare as result_cache and see that only one part of the caching is in progress, and for the second, we access the database every time.
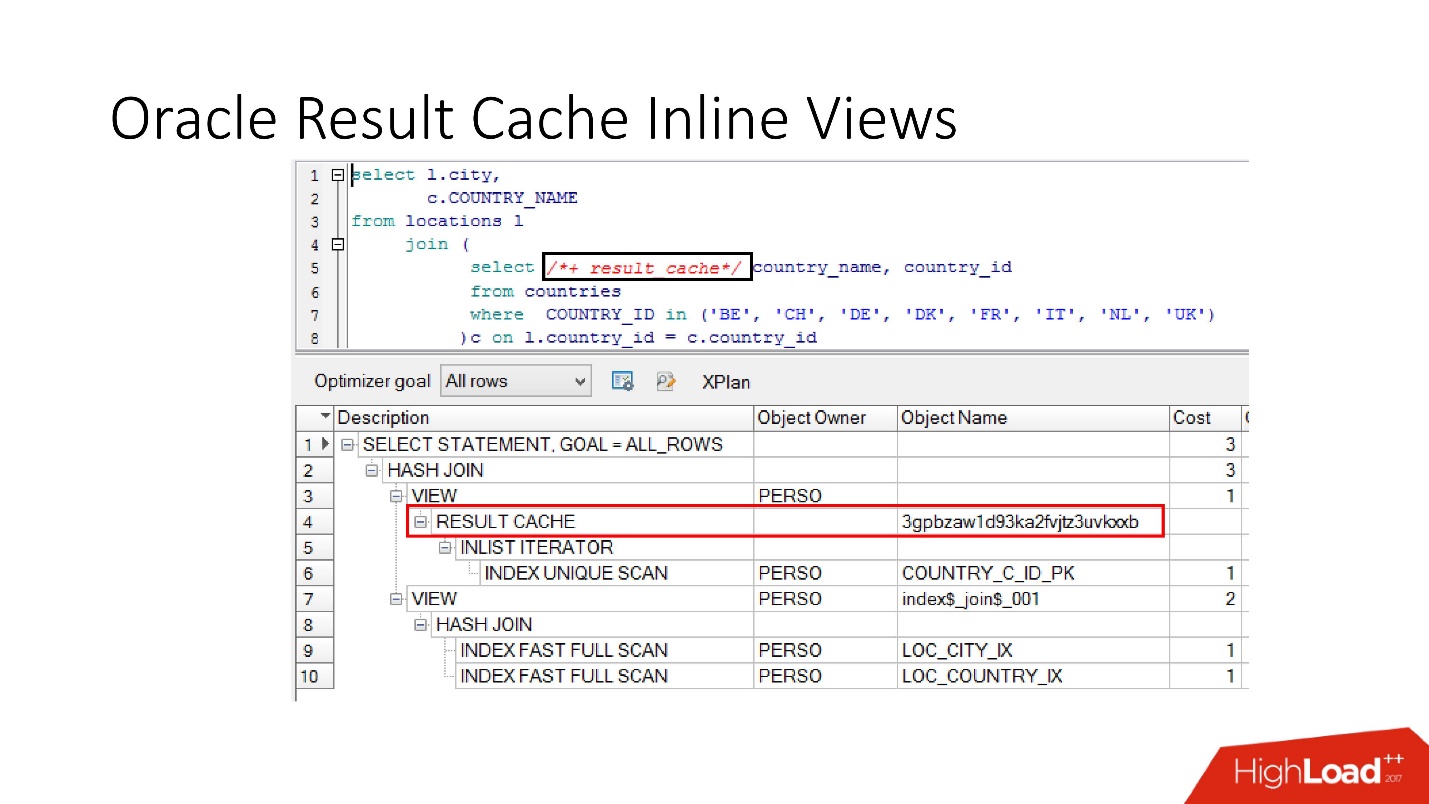
And finally,
there is also encapsulation in
databases , although no one believes this. We take a view, put result_cache in it, and our programmers do not even realize that it is cached. Below we see that in fact only one part of it works.
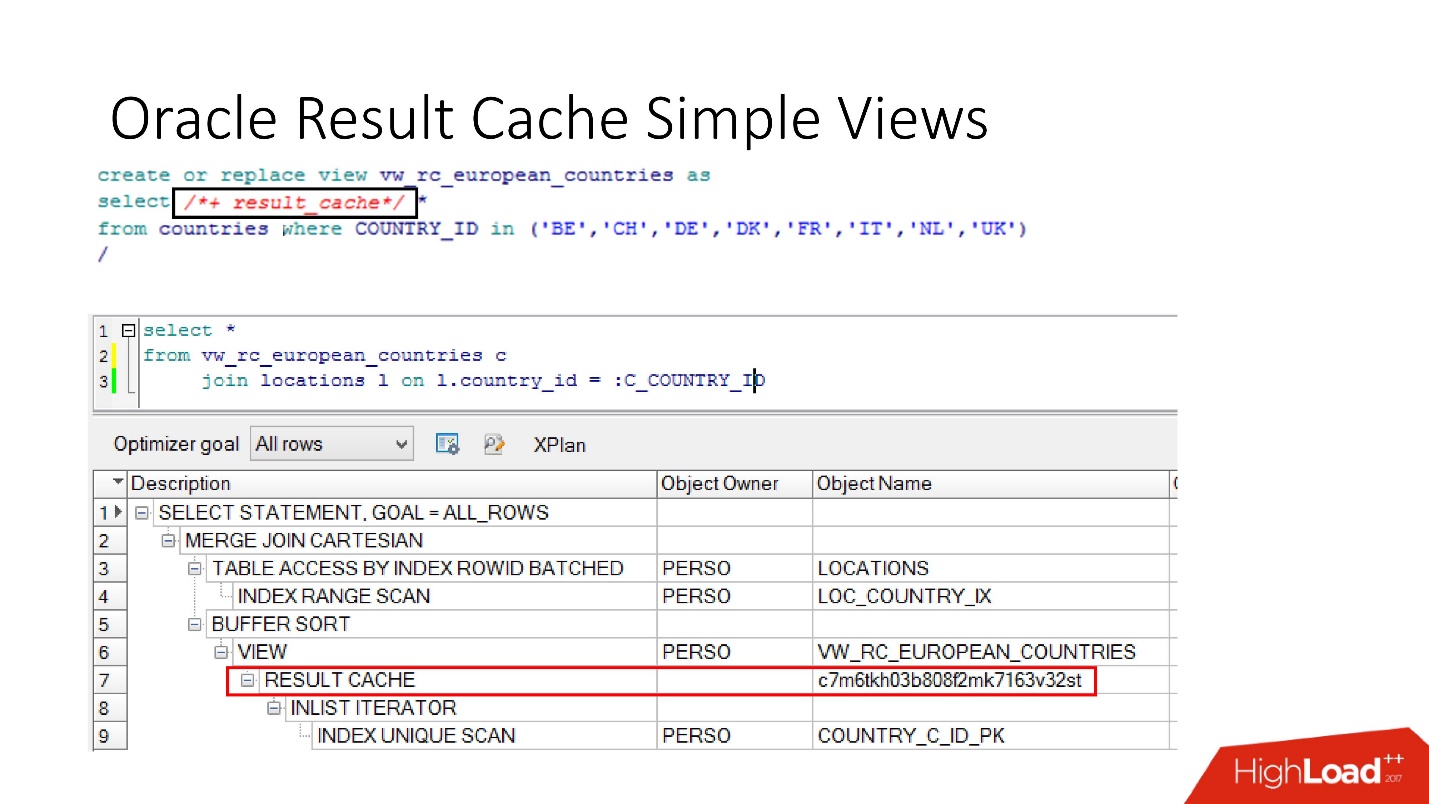
Disability
So, let's see when Oracle invalidates result_cache. Status Published shows the current state of cache validity. When a query to result_cache, as I said, there is no work in the database
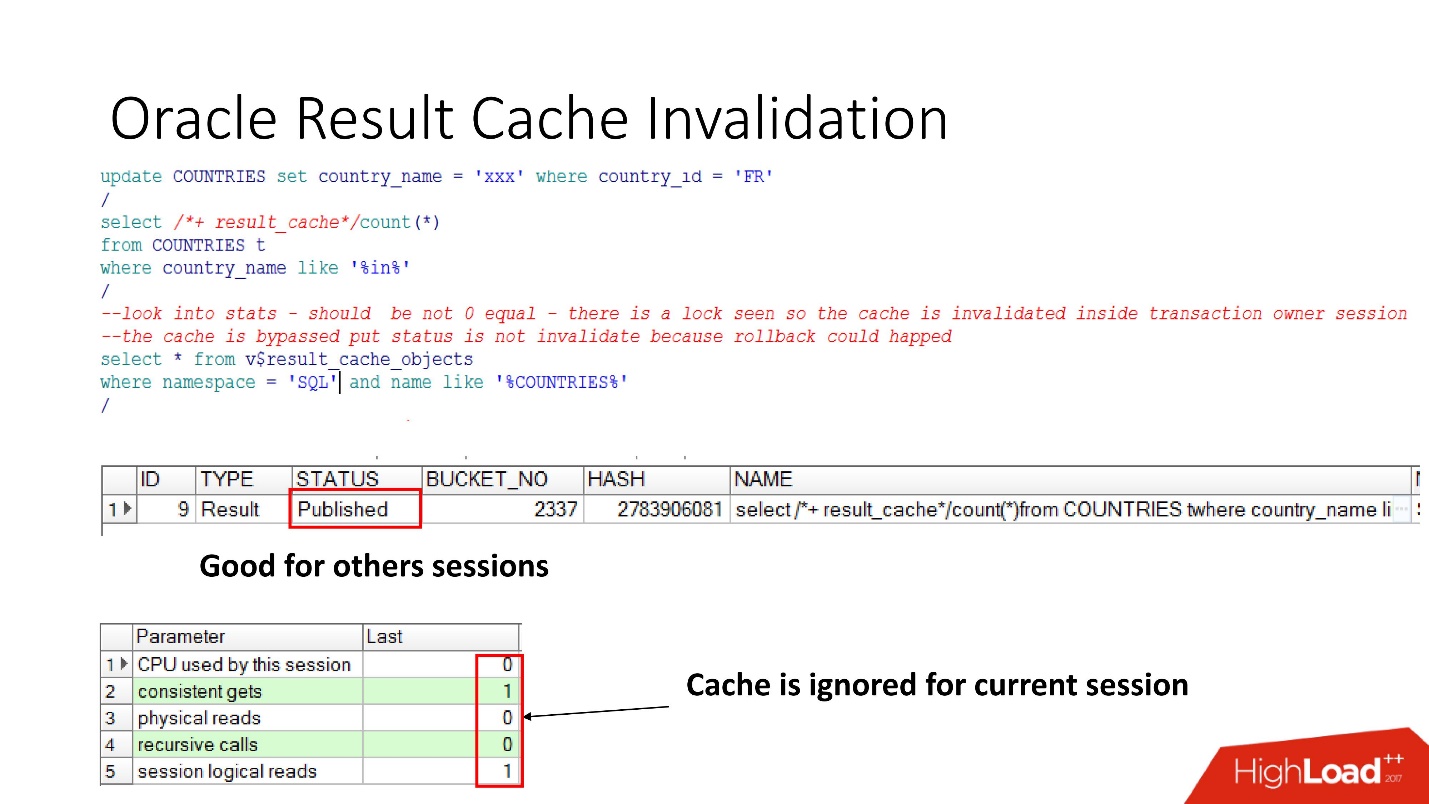
When we made the update, the status was still Published, because the update was not committed and other sessions should see the old result_cache. This is the same notorious consistency in reading.
But in the current session we will see that the load has gone, since it is in this session that the cache is ignored. This is quite reasonable, let's commit - the result will be Invalid, everything works by itself.

It would seem - a dream! Dependency is considered correct - just depending on the request. But no, a number of nuances were revealed.
Oracle produces invalidations and in some unobvious cases :
- When any call to SELECT FOR UPDATE dependencies fly away.
- If there are non-indexed foreign keys in the table, and there was an update on the table marked result_cache, which did not affect anything at all, but something changed in the parent table, the cache will also become invalid.
- This is the most interesting thing that spoils life as much as possible - if there is some unsuccessful update on the table marked as result_cache, nothing worked, but then in the same transaction any other changes were applied that somehow influenced the first table, then all the same result_cache will be reset.
There is also such an anti-pattern about result_cache, when developers, having heard that there is such a cool thing, think: “Oh, there is a repository! Now let's take some query that works on 2-3 partitions - on the current date and on the previous one, mark it as result_cache, and it will always be taken from memory! ”
But when they change the patrician afterthought, the entire cache flies, because in fact, the dependency tracking unit in result_cache is always a table, and I don’t know if there will ever be partitions or not.
We thought and decided that we would go into the production of a recommender system with such things:
- We will not cache all our tables, we take only the necessary ones.
- We set result_cache for a long-running query.
All checked, conducted performance tests,
processing time - 30 s . Everything is great, go to the production!
Nakati - went to sleep. We come in the morning. We see the letter: "Recognition takes at least 20 minutes, sessions hang." Why do they hang? How did
30 seconds turn into 20 minutes ?
Began to understand, look into the database:
- 400 active sessions;
- on average, there are 500 lines in the recognition document;
- speakers minimum - 5-8;
- the number of sessions in the database is always equal to the number of application user multiplied by 3! And result_cache does not like to refer to it frequently.
After conducting an internal investigation, we found out that Java developers make recognition in 3 threads.
We were upset - 5-fold load, fall, degradation, and even with such parameters, there should be no such sinking.
Obviously, you need to understand.
Monitoring

We have two key things to monitor:
- V $ RESULT_CACHE_OBJECTS - a list of all objects;
- V $ RESULT_CACHE_STATISTICS - aggregate statistics of result_cache as a whole.
MEMORY_REPORT - this is a variation on the theme, we will not need them.
Oracle is magical! There is great documentation, but it is designed for those who migrate from other databases to read and think that Oracle is very cool! But
all the information on result_cache lies only on support .

There is a nuance, which is that as soon as we turn to these objects in order to solve the problem, we aggravate it, finally burying ourselves! Prior to Oracle12.2, before the patch of which was released in October last year, these queries make result_cache unavailable for status and recording until they are fully considered.
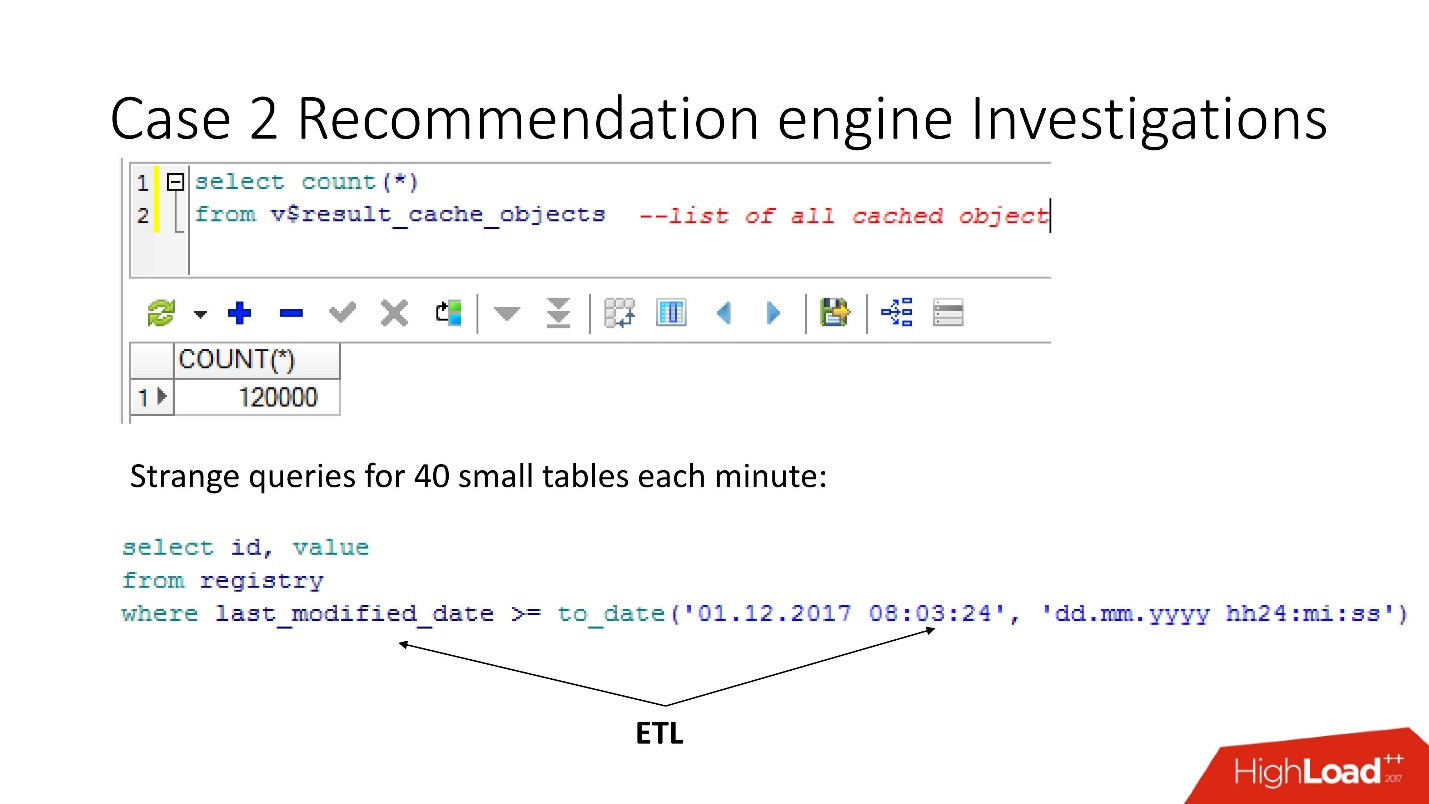
So, using the v $ result_cache_objects view, we found out that there are thousands of entries in the list of cached objects — much more than we expected. Moreover, these were objects from some kind of non-our requests for strange tables - small tables, and last_modified_date requests. Obviously,
someone has set ETL on our base .
Before we go to curse the ETL developers, we checked that the result_cache force option was enabled for these tables, and remembered that we turned it on ourselves, since some of this data was often required by the application and caching was appropriate.
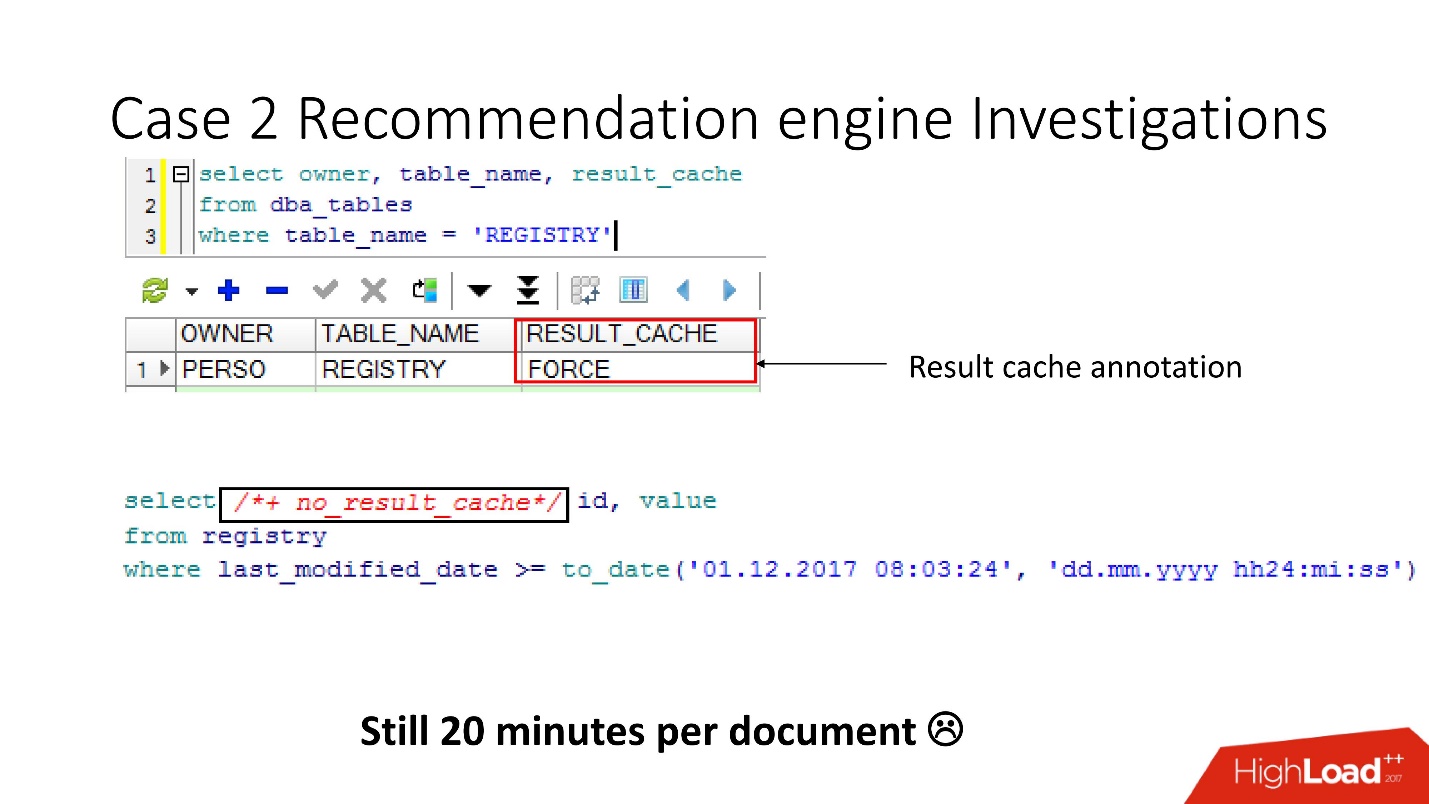
And it turned out that
all these requests just take and wash our cache . Fortunately, the developers had the opportunity to influence ETL in production, so we were able to modify the result_cache to eliminate these minute requests.
Do you think feel better? - Do not feel better! The number of cached objects decreased, and then increased again to 12,000. We continued to study what else is cached, since the speed did not change.

We look - a lot of requests, and so smart, but all incomprehensible. Although the one who worked with Oracle 12 knows that DS SVC is adaptive statistics. It is needed to improve performance, but when there is a result_cache, it turns out that it kills it, because there is a competition. It goes without saying, it is written
only on support .
We knew how workload works and understood that in our case, adaptive statistics would not greatly improve our plans. Therefore, we heroically turned it off - the result, as written in the secret manual - 10 minutes per document. Not bad, but still not enough.
Latches
The competition between result_cache and DS SVC arises from the fact that in Oracle there are latches (latches) - lightweight small locks.

Without going into details of how they work, we try to put the named latch several times - it did not work - Oracle takes and falls asleep
Anyone who is in the subject can say that the result_cache is put on two latches for each block during fetch. These are the details. There are two kinds of snaps in result_cache:
1. Latch for that period while we are writing data to result_cache.

That is, if you have a query running for 8 seconds, for the period of these 8 seconds other similar queries (the keyword “same”) will not be able to do anything, because they are waiting for the data to be written to result_cache. Other requests will be written, but they will wait for the lock only on the first line. How long they have to wait is unknown, it is an undocumented parameter result_cache_timeout. After that, they begin to ignore result_cache, and work slowly. However, as soon as the blocking from the last line was removed during the placement, they automatically start working again with result_cache.
2. The second type of locks - to receive from result_cache, too, from the 1st line to the last.
But since the fetch comes from instant memory, they are removed very quickly.

Be sure to keep in mind that when a DBA sees a latch in a database, it starts saying: “Latch! Wait time - everything is gone! "And here the most interesting game begins:
convince the DBA that the wait time from the latches is actually incomparably less than the repetition time of the request .

As our experience shows, our measurements, the
latches on result_cache, occupy 10% of the queries themselves .
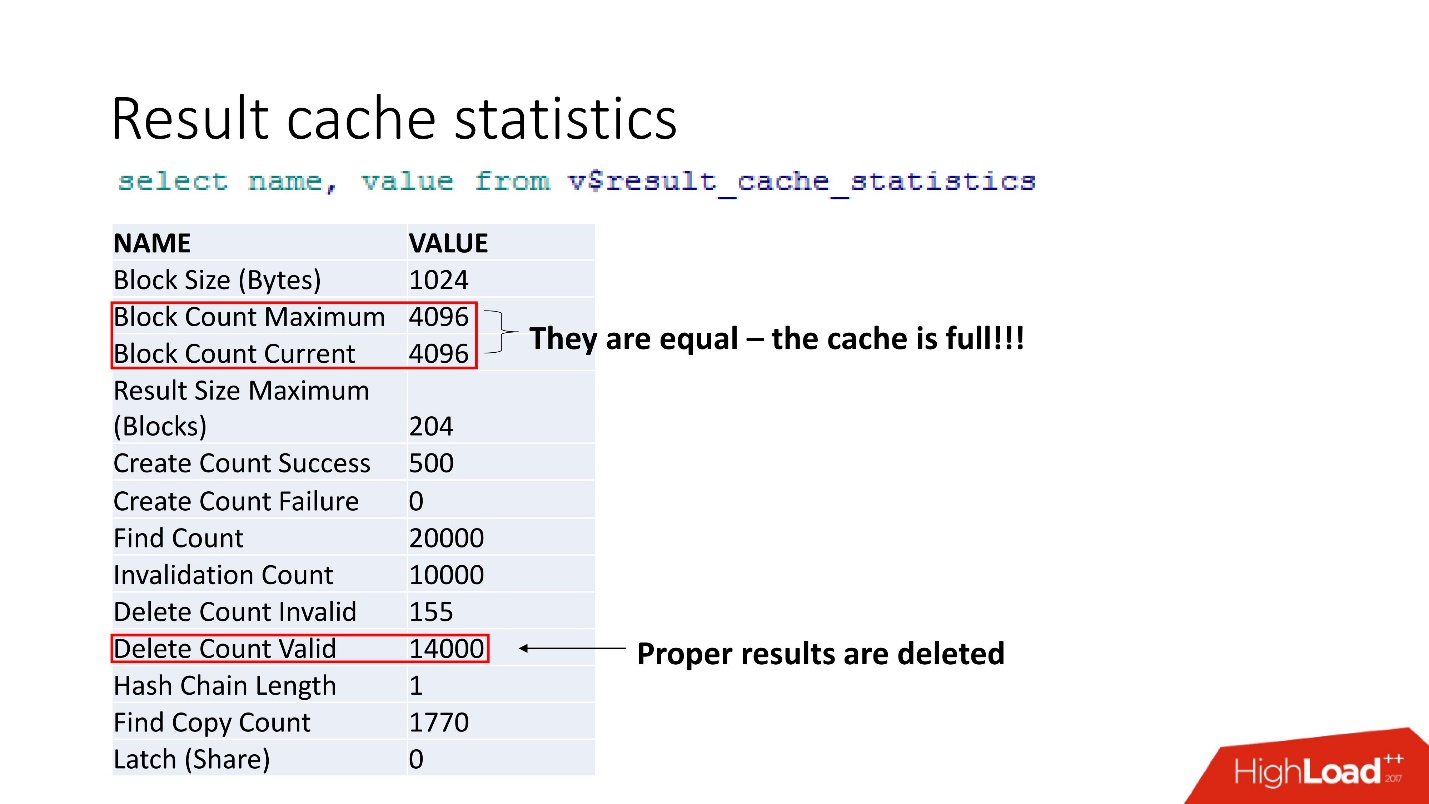
This is aggregated statistics. The fact that everything is bad can be understood by the fact that the cache is clogged. Another confirmation - Proper results are deleted. That is, the
cache is overwritten . It seems that we are smart and always consider the memory size - we took the size of the lines of our cached result for our recommendation, multiplied by the number of lines, and something went wrong.

At support, we found 2 bugs that say that
when the result_ overflow overflows, performance degradation occurs . And this is also fixed in the very secret patch.
The secret is that memory is allocated in blocks. In our case, of course, it’s also added that workload has grown 5 times. Therefore, when calculating the memory, it is not necessary to multiply by the width of your data, but multiply by the block size, and then there will be happiness.
What else can you customize?Parameters of the sea: there are documented and undocumented parameters. In fact, we do not need all these parameters.
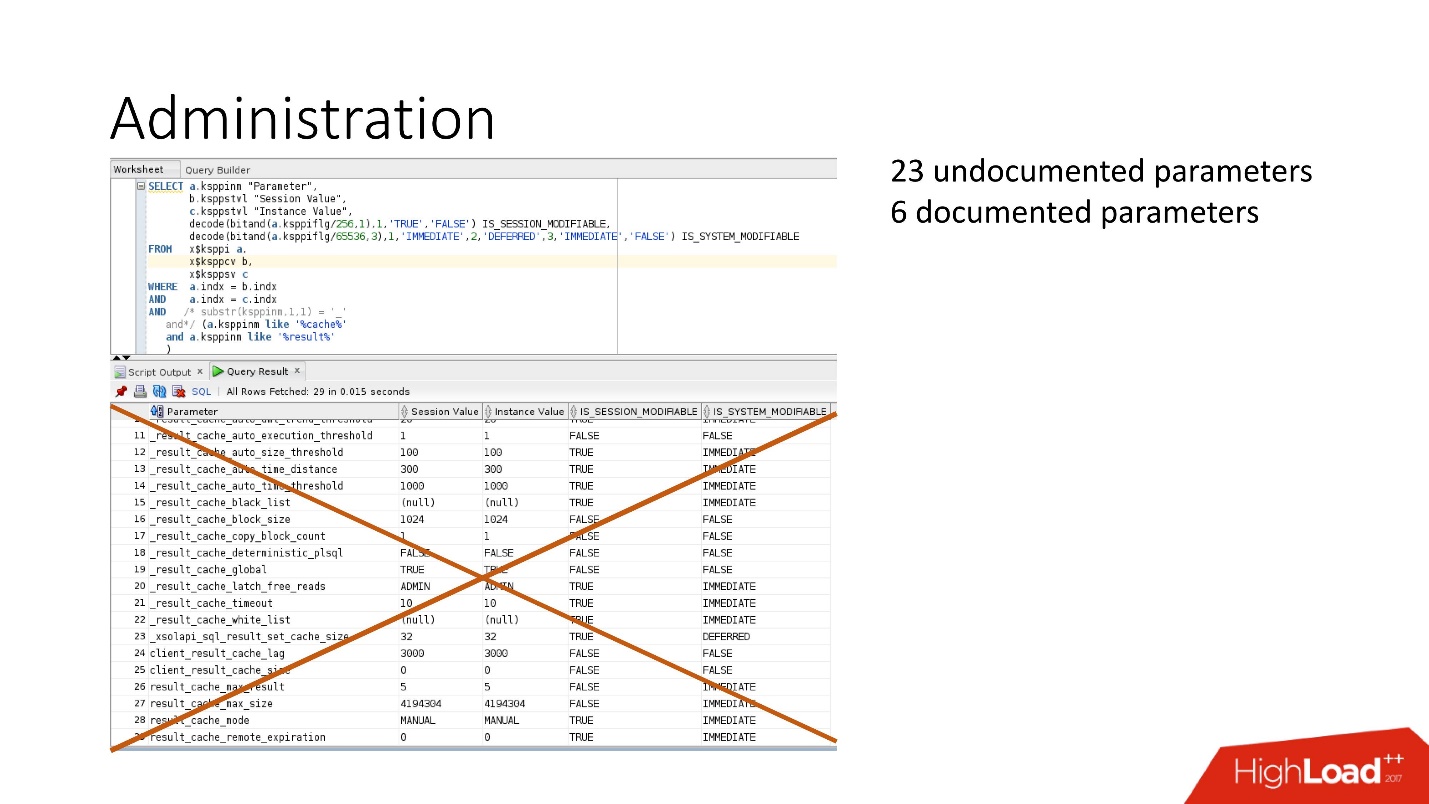
In fact, 4 parameters are enough:
- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
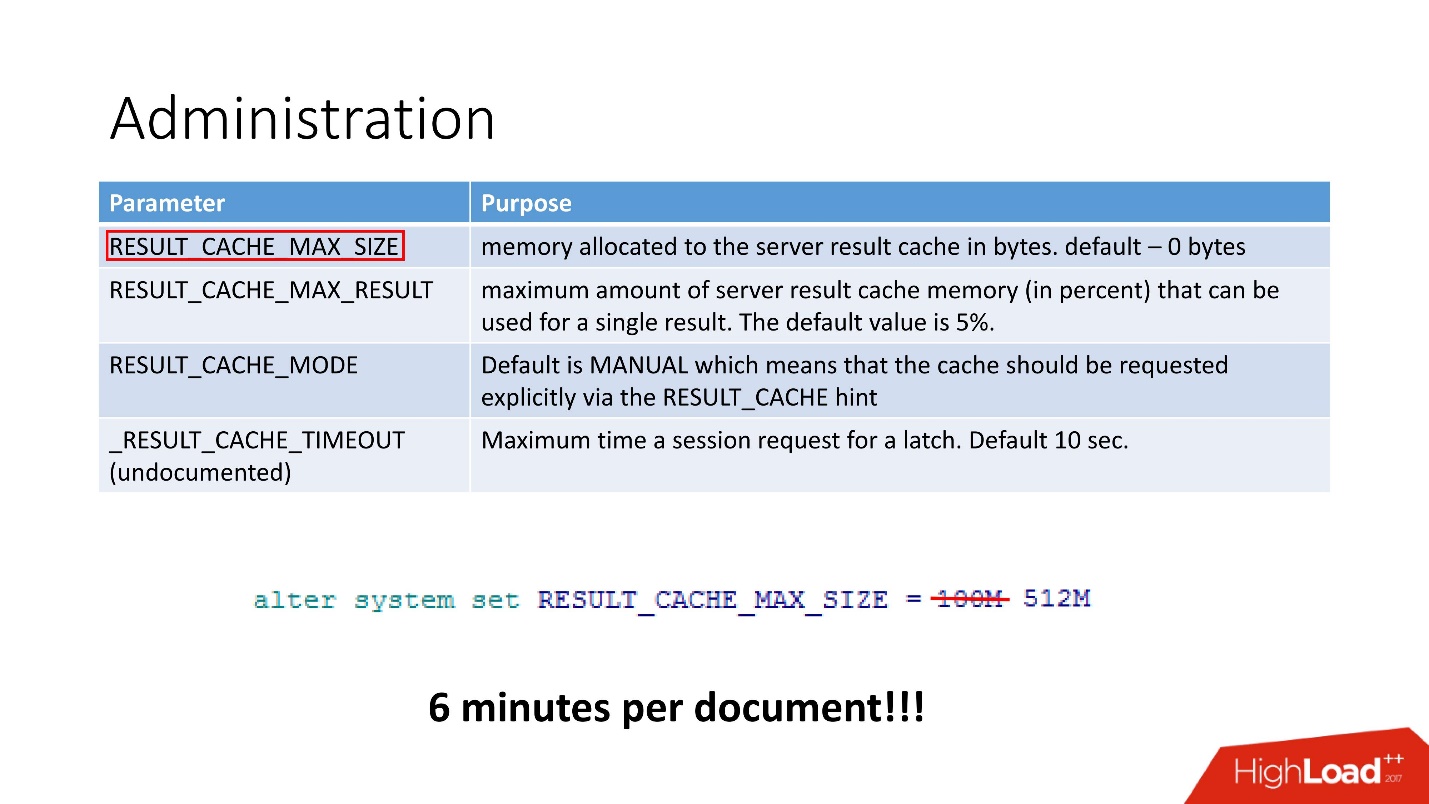
Even one thing was enough for us - cache size. After we replaced 100 MB with 512 MB, the document processing time was reduced to 6 minutes.
Still digging further, suddenly there is still something strange. For example, Invalidation Count = 10,000.
The one who does nothing is not mistaken. Through some research, we found that job updates of recommendations were disabled, which led to constant data updates. Accordingly, the cache is constantly disabled. We ran the job at one-hour intervals, as was intended, which automatically turned off the constant table update.
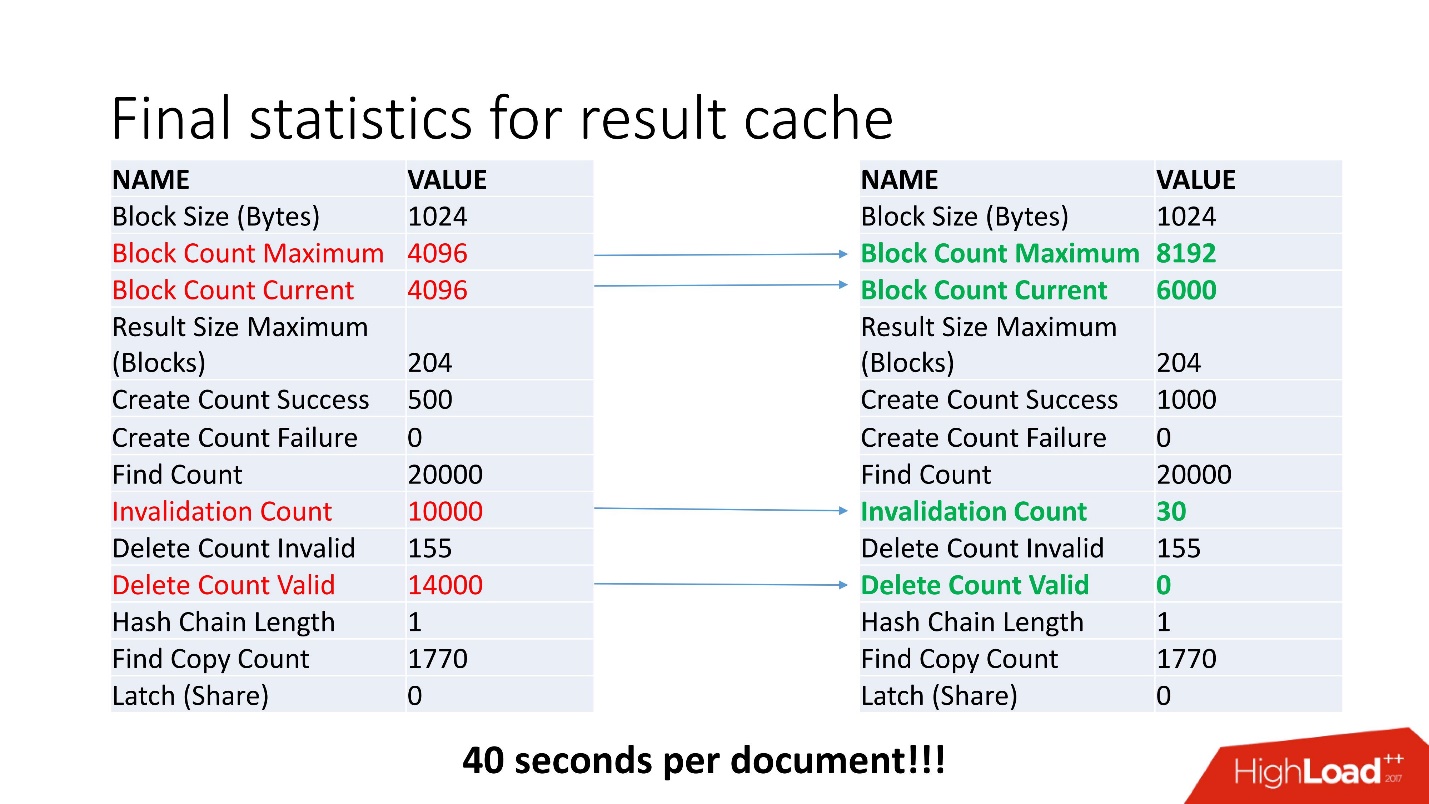
There is always free space, invalid only at the moment of cache recalculation, and there is no data deletion.
With a fivefold increase in load, we received a document processing speed of 40 seconds .
The most important thing is not to overwhelm the cache. While we were all exploring this, we discovered a bunch of undocumented chips that are in the Oracle kernel. They are wonderful!
 SHELFLIVE
SHELFLIVE is a parameter that allows read-consistent cache dying, that is, the cached request will die in 10 seconds and the cache will be cleaned. This parameter was built into the new version of the application. It is important that the cache is also deleted if there was a change in the data.
There is an even more interesting option -
SNAPSHOT . It is convenient if the fact of the change is not critical for the cache, there is no need to keep read-consistent and no latches - then changing the data will not invalidate the cache.
The limitations are clear:

- Dictionaries - there is no possibility of caching objects in the SYS scheme.
- Cannot cache temporary and external tables. It is important that in fact it is possible, and Oracle obviously does not limit this, but this leads to the fact that you can see the contents of the temporary tables of other users. Moreover, Oracle declares that it is fixed, but in 12.2 this problem is still present. By the way, for some reason the external table is also written in support, not in the official documentation.
- You cannot use nondeterministic sql and pl / sql functions: current_date, current_time, etc. There is a secret move, how to bypass the restrictions with current_time, because you always want to cache data for the current date.
- Cannot use pipeline functions.
- The input and output parameters of the cache should be of simple data types, that is, no CLOB, BLOB, etc.
Result cache inside Oracle
Result_cache is a feature of Oracle Core. It is actually used in a heap of everything, everything associated with the job uses result_cache (by the way, that secret hint where we discovered it is highlighted) and everywhere that is connected with APEX.

Everything related to Dynamic sampling and adaptive statistics, that is, everything that makes your prediction more correct, works on result_cache.

Oracle internals for result cache
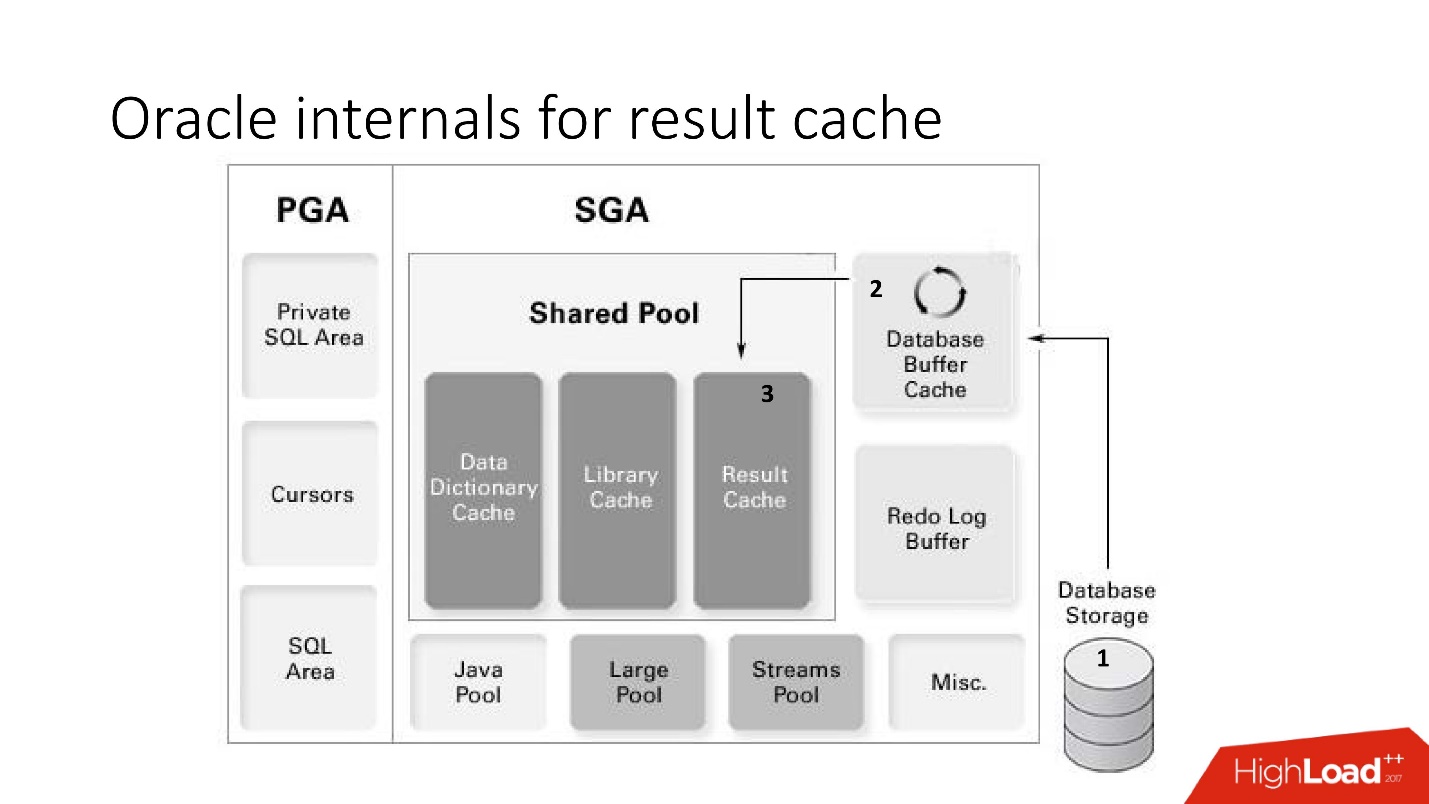
Let's return to the memory scheme and briefly summarize the work of result_cache:
- upon request, the data comes from the storage level (storage) to the buffer cache;
- data from the buffer cache falls into the result_cache memory;
- result_cache is in a shared pool.
 Pros:
Pros:- Minimal impact on application code.
- No need to bother with the stored logic in the database and read-consistent.
- Result_cache, as we have seen, is pretty fast.
Minuses:- Expensive database memory.
- May result in performance degradation if you configure the cache incorrectly.
We are not alone!
From all this, there may be a feeling that we are so Krivorukov. But look at Oracle's support, for example, for September 29, 2017: the new version of the Oracle E-Business suite crashes due to result_cache, because they decided to speed it up.

However, we are not interested in the very fact of the existence of problems, but in ways to prevent them. In the wilds of the Internet, I found a very informative letter to the support service of one of the leading Russian cloud loyalty systems that failed and the system was unavailable for an hour.

A dramatic increase in the time to issue from the cache during the roll of patches occurred in consequence:
- blocking due to incorrectly calculated cache size;
- and, possibly, locks, for example, in v $ result_cache_memory or dbms_result_cache.memory_report, since the bug on them is not closed.
However, bugs tests are written so cunningly that they actually clearly state that there is an error in v_result_cache_objects.Do not read the documentation, read the support note - everywhere it says on support that it will be bad.
 To cope with the problem, this company did roughly the same thing as we did: we increased the size of the cache and turned off something. For me personally, it’s interesting how they did it, because you can disable it in three ways:
To cope with the problem, this company did roughly the same thing as we did: we increased the size of the cache and turned off something. For me personally, it’s interesting how they did it, because you can disable it in three ways:- remove hint result_cache;
- set hint no result_cache;
- use black_list, that is, without changing the application, to prohibit caching something.
What is the conclusion from here?- Always before you roll something, consider how it will affect the use of memory;
- Turn off the cache for the period of loading, that is, quickly disconnected, poured and turned on. It is better that the system slows down a bit, but earns it, than it went down.
As we have noticed, the main problem of caches on the server is the consumption of expensive server memory . Oracle has a third, final solution.Client side result cache
 The diagram of its device is shown on the above, these are the main components of the database and the driver.At the first call, the client-side Result Cache goes to the database, which is pre-configured, gets the size of the client cache from the database, and instantiates this cache on the client once during the first connection. The cached query first accesses the database, and writes the data to the cache. The remaining threads request a common driver cache, thereby saving memory and server resources. By the way, sometimes depending on the load, the driver sends statistics on the use of the cache to the database, which can then be viewed.An interesting question is how is the invalidation?There are two modes of invalidation, which are sharpened on the parameter Invalidation lag. This is how much Oracle allows the driver cache to be non-consistent.The first mode is used when requests are frequent and Invalidation lag does not occur. In this case, the thread will go to the database, update the caches and read data from it.
The diagram of its device is shown on the above, these are the main components of the database and the driver.At the first call, the client-side Result Cache goes to the database, which is pre-configured, gets the size of the client cache from the database, and instantiates this cache on the client once during the first connection. The cached query first accesses the database, and writes the data to the cache. The remaining threads request a common driver cache, thereby saving memory and server resources. By the way, sometimes depending on the load, the driver sends statistics on the use of the cache to the database, which can then be viewed.An interesting question is how is the invalidation?There are two modes of invalidation, which are sharpened on the parameter Invalidation lag. This is how much Oracle allows the driver cache to be non-consistent.The first mode is used when requests are frequent and Invalidation lag does not occur. In this case, the thread will go to the database, update the caches and read data from it.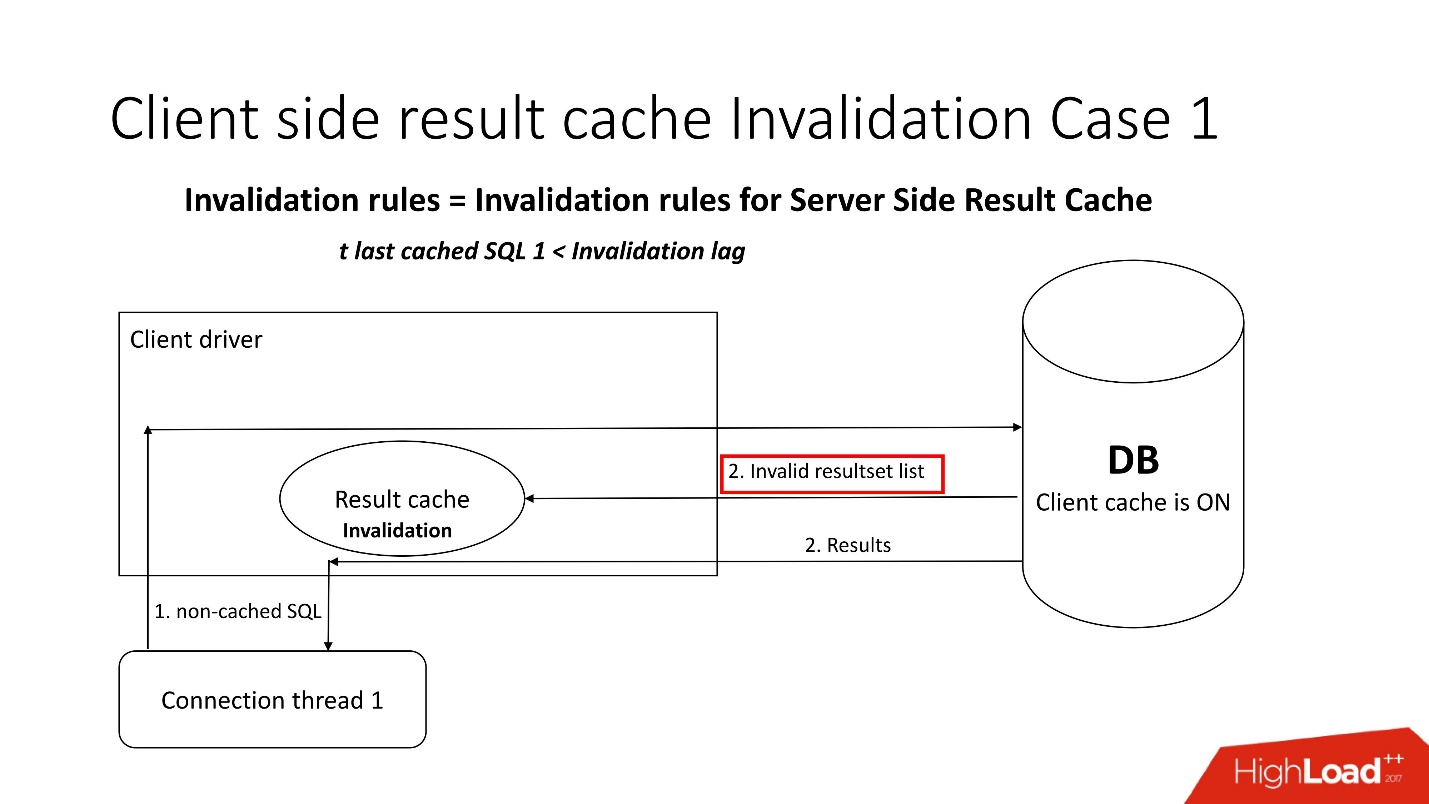 If the Invalidation lag fails, then any noncacheable query, referring to the database, brings the list of invalid objects in addition to the query results. Accordingly, they are marked in the cache as invalid, and everything works as in the picture from the first scenario.In the second case, if more time has passed than the Invalidation lag, then the client’s result_cache itself goes to the database and says: “Give me a list of changes!” That is, he himself maintains his adequate state.Configuring the client-side Result Cache is very simple . There are 2 parameters:
If the Invalidation lag fails, then any noncacheable query, referring to the database, brings the list of invalid objects in addition to the query results. Accordingly, they are marked in the cache as invalid, and everything works as in the picture from the first scenario.In the second case, if more time has passed than the Invalidation lag, then the client’s result_cache itself goes to the database and says: “Give me a list of changes!” That is, he himself maintains his adequate state.Configuring the client-side Result Cache is very simple . There are 2 parameters:- CLIENT_RESULT_CACHE_LAG — cache lag value;
- CLIENT_RESULT_CACHE_SIZE - size (minimum 32 KB, maximum - 2 GB).

From the point of view of the application developer, the client cache is not particularly different from the server cache, they also added hint result_cache. If it was, then it will simply start to be used client - that on .Net, that in Java.

After 10 iterations of the query, I received the following.

The first call is the creation, then 9 cache accesses. The table indicates that the memory is also allocated in blocks. Also pay attention to SELECT - it is not very intuitive. I, frankly, before I began to deal with this, I did not even know that there was such a presentation of
GV$SESSION_CONNECT_INFO . Why Oracle did not bring it directly to this table (and this is a table, not a view) I could not understand. But that is why I believe that this functionality is not very much in demand, although it seems to me that it is very useful.
Advantages of client caching:- cheap client memory;
- any drivers are available —JDBC, .NET, etc .;
- minimal impact in application code.
- Reducing the load on the CPU, I / O, and in general the database;
- No need to learn and use all sorts of clever caching layers and APIs;
- no snaps.
Disadvantages:- consistency in reading with a delay - in principle, now it is a trend;
- need Oracle OCI client;
- 2GB limit per client, but in general, 2 GB is a lot;
- For me personally, the key limitation is that there is little information about production.
On support, which we always use when working with result_cache, I found only 5 bugs. This suggests that, most likely, it is very few people need.
So, we pile up everything that is said above.
Hand-made cache
Bad scripts:- Instant change - if, after changing the data, the cache should instantly become irrelevant. For self-made caches, it is hard to create a correct invalidation in case of changes in the objects on which they are built.
- If the use of logic stored in the database is prohibited by the development policies.
Good scripts:- There is a strong team of database developers.
- Implemented PL / SQL logic.
- There are restrictions that do not allow the use of other caching techniques.
Server side Result cache
Bad scripts:- There are a lot of different results that just wash the entire cache;
- Requests take longer than _RESULT_CACHE_TIMEOUT, or this parameter is configured incorrectly.
- Cache loads results from very large sessions in parallel threads.
Good scripts:- Reasonable amount of cached results.
- Relatively small data sets (200–300 lines).
- Quite expensive SQL, otherwise it will take all the time to latch.
- More or less static tables.
- There is a DBA, which in case of what will come and save everyone.
Client side Result cache
Bad scripts:- When that problem of instantaneous invalidation arises.
- Requires thin drivers.
Good scripts:- There is a normal middle layer development team.
- A lot of SQL is already being used without the use of an external cache layer that can be easily connected.
- There are restrictions on the glands.
findings
I believe that my story about the pain Server side Result cache, so the conclusions are as follows:
- Always estimate the size of the memory correctly, taking into account the number of queries, not the number of results, ie: blocks, APEX, job, adaptive statistics, etc.
- Do not be afraid to use the automatic flush out cache options (snapshot + shelflife).
- Do not overload the cache with queries while loading large amounts of data; disable result_cache before this. Warm up the cache.
- Make sure that _result_cache_timeout meets your expectations.
- NEVER use FORCE for the entire database. Need a database in memory - use a specialized in-memory solution.
- Check whether the FORCE option is adequately used for individual tables so that it does not work out, as we do with third-party ETL.
- Decide whether adaptive statistics are as good as Oracle describes (_optimizer_ads_use_result_cache = false).
Highload ++ Siberia next Monday, the schedule is ready and published on the site. In the subject of this article there are several reports:
- Alexander Makarov (CFT Group of Companies) will demonstrate a method for identifying bottlenecks in the operation of the server software using the example of an Oracle database.
- Ivan Sharov and Konstantin Poluektov will tell you what problems arise when migrating a product to new versions of the Oracle database, and also promise to give recommendations on the organization and conduct of such work.
- Nikolay Golov will tell you how to ensure data integrity in the microservice architecture without distributed transactions and tight connectivity.
See you in Novosibirsk!