The first and
second part of "Evaluation of ThunderX2 from Cavium: the dream of the Arm server came true."
Java performance
SPECjbb 2015 is a Java Business Benchmark test that is used to evaluate the performance of servers running typical Java applications. It uses the latest features of Java 7 and XML, messanging with security.

Please note that we have updated version SPECjbb 1.0 to version 1.01.

We tested SPECjbb with four groups of transaction and back-end injectors. The reason why we use the Multi JVM test is that it is more close to real conditions: several virtual machines on a server are common practice, especially on servers with more than 100 threads. The Java version is OpenJDK 1.8.0_161.
Every time we publish the results of SPECjbb, we get comments that our indicators are too low. Therefore, we decided to spend a little more time and pay attention to the various settings.
- Kernel settings, such as task scheduler timings, clearing page cache
- Disable power-saving features, manually setting c-state behavior.
- Installing fans at maximum speed (spend a lot of energy in favor of a couple of extra performance points)
- Disable RAS features (for example, memory scrub)
- Numerous settings for various Java parameters ... It’s not realistic, because every time you run an application on different machines (which often happens in a cloudy environment), expensive specialists need to tune parameters for a specific machine, which, moreover, can cause the application to stop on other machines
- Configure very specific SKU-specific NUMA settings and CPU bindings. Migrating between two different SKUs in the same cluster can lead to serious performance problems.
In a production environment, the setting should be simple and, preferably, not too specific for the machine. For this purpose, we applied two types of settings. The first one is a very simple setup to measure out-of-box performance to place everything on a server with 128 GB of RAM:
"-server -Xmx24G -Xms24G -Xmn16G"For the second setting, in search of the best throughput, we played with “-XX: + AlwaysPreTouch”, “-XX: -UseBiasedLocking” and “specjbb.forkjoin.workers”. “+ AlwaysPretouch” resets all memory pages before launch, which reduces the performance impact on new pages. "-UseBiasedLockin" disables baised lock, which is enabled by default. Biased locking gives priority to a stream that has already loaded contended data into the cache. The reverse side of Biased locking is quite complex additional processes (Rebias), which can reduce productivity, in case of an incorrectly chosen strategy.
The graph below shows the maximum performance for our MultiJVM SPECJbb test.

ThunderX2 achieves performance from 80 to 85% of the performance of the Xeon 8176. This figure is enough to surpass the Xeon 6148. Interestingly, Intel and Cavium systems achieve their best results in various ways. In the case of Dual ThunderX2, we used:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingWhile the Intel system has achieved the best performance, while leaving the offset of the lock (by default). We noticed that the Intel system — probably because of the relatively “odd” number of threads — has a slightly lower average processor load (a few percent) and a larger L3 cache, which makes biased locking a good strategy for this architecture.
Finally, we have Critical-jOPS, which measures throughput by response time limitations.

With the active use of a large number of threads, you can get significantly more Critical-jOPS by increasing the distribution of RAM on the JVM. Surprisingly, the Dual ThunderX2 system - with its higher number of threads and lower clock frequency - shows the best time, providing high bandwidth, while maintaining a 99 percent response time to a certain limit.
Increasing the heap size helps Intel to slightly close the gap (up to x2), but at the expense of bandwidth (from -20% to -25%). It seems that the Intel chip needs more configuration than the ARM. To explore this further, we turned to the Transparant Huge Pages (THP).
Java performance: large pages
Usually for a CPU, it is rare for someone to replay another one in factor 3, but we decided to investigate the matter further. The most obvious candidate was “Huge Pages,” or as everyone except the Linux community, calls it “Large Pages.”
Each modern processor caches virtual and physical memory mappings in its TLBs. The “normal” page size is 4 KB, so with 1536 elements the Skylake core can cache about 6 MB per core. Over the past 15 years, DRAM capacity has grown from a few GB to hundreds of GB, and therefore TLB misses have become a concern. A TLB slip is quite expensive - you need several memory accesses to read a few tables and finally find the physical address.
All modern processors support large pages. In x86-64 (Intel and AMD), the popular option is 2 MB, 1 GB page is also available. Meanwhile, a large page on ThunderX2 is at least 0.5 GB. The use of large pages reduces the number of TLB misses (although the number of entries in the TLB is usually much lower for large pages), reduces the number of memory accesses necessary for a TLB miss.
Nevertheless, the time passed before Linux supported this feature in a convenient way to work. Memory fragmentation, conflicting and difficult to customize settings, incompatibilities and especially very confusing names caused a lot of problems. In fact, many software providers still advise server administrators to disable large pages.
To this end, let's see what happens if we turn on the Transparent Huge Pages and save the best settings discussed earlier.
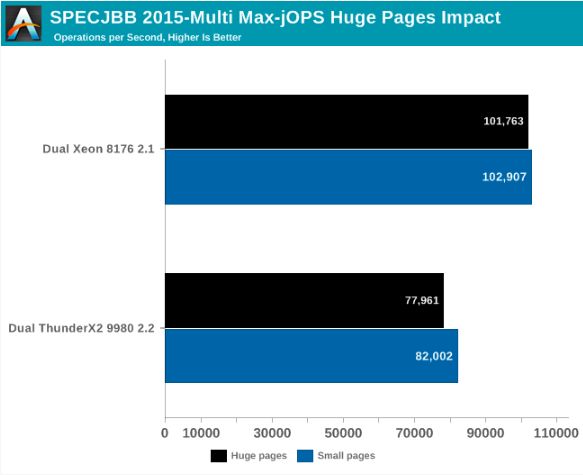
Overall, for Max-jOPs, the performance impact is not exciting; in fact, this is a small regression. Xeon loses about 1% of its bandwidth, ThunderX2 - about 5%.
We now turn to the consideration of the Critical-jOPS metric, where throughput is measured as the 99th percentile of the response time limit.

A huge difference! Instead of losing, Intel goes beyond ThunderX2. However, it should be noted that 4-KB page performance seems to be a serious weakness in Intel architecture.
Apache Spark 2.x Benchmarking
Last in the list, but not least, our arsenal is the Apache Spark test. Apache Spark is the brainchild of Big Data processing. Accelerating Big Data applications remains a priority project at the university lab where I work (Sizing Servers Lab at the University of West-Flanders), so we prepared a guideline that uses many of the Spark functions and is based on use in the real world.

The test is described in the diagram above. We start with 300 GB of compressed data collected from CommonCrawl. These compressed files are a large number of web archives. We unzip the data on the fly to avoid a long wait, which is mainly related to the storage device. Then we extract meaningful text data from the archives using the Java library “BoilerPipe”. Using the Stanford CoreNLP Natural Language Processing Tool, we extract entities (“words that mean something”) from the text, and then calculate which URLs have the greatest occurrence of these objects. The Alternating Lessest Square algorithm is used to recommend which URLs are most interesting for a particular subject.
In order to achieve better scaling, we launch 4 performers. Researcher Esley Heyvaert reconfigured the Spark test so that it can work on Apache Spark 2.1.1.
Here are the results:

(*) EPYC and Xeon E5 V4 are older, run on Kernel 4.8 and slightly older Java 1.8.0_131 instead of 1.8.0_161. Although we expect the results to be very similar to the kernel 4.13 and Java 1.8.0_161, since we did not see a big difference in the Skylake Xeon between these two settings.
Data processing is very parallel and loads the processor very intensively, but the “shuffle” phases require a lot of interaction with the memory. The time spent communicating with the storage device is negligible. The ALS phase does not scale across multiple threads, but is less than 4% of the total testing time.
ThunderX2 provides 87% of the performance of the twice as expensive EPYC 7601. Since this indicator scales well with the number of cores, we can estimate that the Xeon 6148 will gain about 4.8. on Apache Spark Thus, while ThunderX2 cannot really threaten Xeon Platinum 8176, it gives the same thing as Gold 6148 and his brother for far less money.
And what is the result
Summing up, our SPECInt tests show that the ThunderX2 cores still have some flaws. Our first negative impression is that the code for intensive branching — especially in combination with the usual L3 cache misses (high DRAM latency) —is rather slow. Thus, there will be special cases when ThunderX2 is not the best choice.
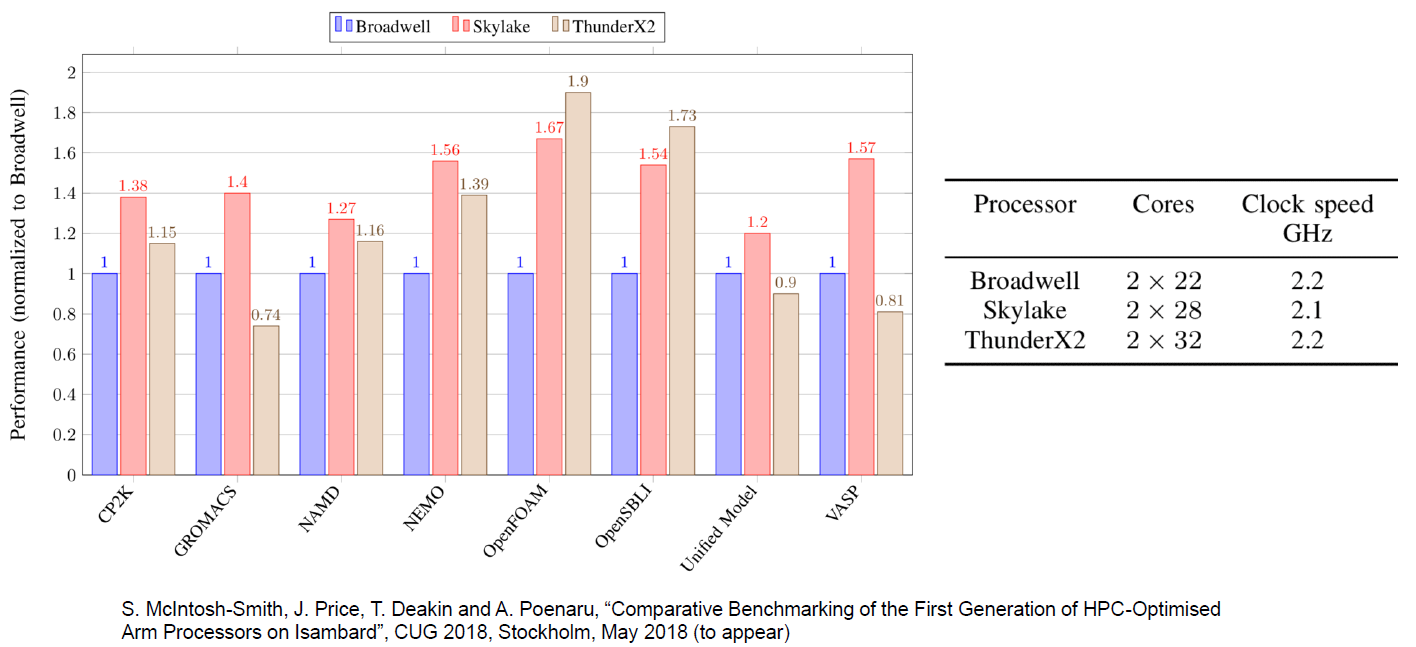
However, in addition to some niche markets, we are quite confident that ThunderX2 will become a solid performer. For example, performance measurements made by our colleagues at the University of Bristol confirm our assumption that intensive HPC workloads, such as OpenFoam (CFD) and NAMD.run, really work well on ThunderX2
According to the results of the early testing of the server software, which we managed to do, we can be pleasantly surprised. Productivity per dollar ThunderX2 both on Java Server (SPECJbb) and on big data processing - now is by far the best on the server market. We have to re-test the AMD EPYC processor and the gold version of the current generation (Skylake) Xeon, but at the same time, 80-90% of the performance of the 8176 processor for one quarter of its cost will be very difficult to beat.
As an additional benefit for Cavium and ThunderX2, it is necessary to mention that in 2018, the Arm Linux ecosystem is already mature; specialized Linux kernels and other tools are no longer needed. You simply install a Ubuntu, Red Hat or Suse server, and you can automate the deployment and installation of software from standard repositories. This is a significant improvement over what we experienced when ThunderX was launched. Back in 2016, a simple installation from the usual Ubuntu repositories could cause problems.
So overall, ThunderX2 is a very powerful contender. This may be even more dangerous for EPYC AMD than for Skylake Xeon from Intel due to the fact that both Cavium and AMD are competing for the same group of customers, given the possibility of rejection from Intel. This is due to the fact that customers who have invested in expensive corporate software (Oracle, SAP) are less sensitive to the cost on the hardware side, so they switch to the new hardware platform much less frequently. And these people invested the last 5 years in Intel, because it was the only option.
This, in turn, means that those who are more flexible and price-sensitive, such as hosting and cloud providers, will now be able to choose an alternative Arm server with an excellent performance-per-dollar ratio. And with HP, Cray, Pengiun, Gigabyte, Foxconn, and Inventec offering systems based on ThunderX2, there is no shortage of quality suppliers.
In short, ThunderX2 is the first SoC that can compete with Intel and AMD in the market for CPU servers. And this is a pleasant surprise: finally, a solution for Arm servers has appeared!
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends,
30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about
How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?