
annotation
Processing data in real time exactly once ( exactly-once ) is an extremely nontrivial task and requires a serious and thoughtful approach throughout the entire chain of calculations. Some even believe that such a task is impossible . In reality, I would like to have an approach that provides fault tolerant processing without any delays at all and the use of various data warehouses, which puts forward even more stringent requirements for the system: concurrent exactly-once and persistent layer heterogeneity. To date, this requirement does not support any of the existing systems.
The proposed approach will consistently reveal the secret ingredients and the necessary concepts that make it relatively easy to implement heterogeneous processing concurrent exactly-once in literally two components.
Introduction
The developer of distributed systems goes through several stages:
Stage 1: Algorithms . Here is the study of basic algorithms, data structures, programming approaches like OOP, etc. The code is exclusively single-threaded. The initial phase of entry into the profession. However, quite difficult and can last for years.
Stage 2: Multithreading . Further, there are questions of extracting maximum efficiency from iron, multithreading, asynchrony, racing, debagging, strace, sleepless nights arise ... Many people get stuck at this stage and even begin to catch an unexplainable thrill from some point. But only a few reach an understanding of the architecture of virtual memory and memory models, lock-free / wait-free algorithms, various asynchronous models. And almost no one ever verifies multithreaded code.
Stage 3: Distribution . There is such a trash going on, that neither in a fairy tale to say nor a pen to describe.
It would seem that something complicated. Making a transformation: many threads -> many processes -> many servers. But each transformation step introduces qualitative changes, and they all fall on the system, crushing it and turning it into dust.
And the point here is in changing the error handling domain and the presence of shared memory. If before there was always a piece of memory that was available in each stream, and if desired, in each process, now there is no such piece and cannot be. Every man for himself, independent and proud.
If earlier a crash in the stream buried the stream and the process at the same time, it was good, because did not lead to partial refusals, now partial refusals are becoming the norm and every time before each action you think: “what if?”. It is so annoying and distracting from writing, in fact, the actions themselves, that the code because of this grows not by times, but by orders of magnitude. Everything turns into noodles for handling errors, states, switching and saving context, recovery due to failures of one component, another component, unavailability of some services, etc. etc. Screwing all this good monitoring can be great to spend the night away for your favorite laptop.
Whether the matter is multithreading: I took a mutex and went to shred the common memory into pleasure. Beauty!
As a result, we have that the key and proven patterns in the battles took away, but new ones, for some reason, were not delivered, and it turned out like a joke about how the fairy waved her wand and the tower fell off the tank.
However, in distributed systems there is a set of proven practices and proven algorithms. However, every self-respecting programmer considers it his duty to reject well-known achievements and build his own good, despite the accumulated experience, a considerable number of scientific articles and academic research. After all, if you can in algorithms and multithreading, how can you get into a mess with distribution? Two opinions here can not be!
As a result, systems are buggy, data diverges and deteriorates, services periodically become unavailable for recording, or even completely inaccessible, because suddenly the node has fallen, the network has stopped, Java has consumed a lot of memory and GC has blunted, and many more other reasons allowing to delay before the authorities.
However, even with well-known and proven approaches, life does not become easier, because distributed reliable primitives are heavyweight with serious requirements for the logic of executable code. Therefore, the corners are cut wherever possible. And, as is often the case, with corners that are hastily cut off, simplicity and relative scalability appear, but the reliability, availability and consistency of the distributed system disappears.
Ideally, I would like not to think about the fact that our system is distributed and multi-threaded, i.e. work on the 1st stage (algorithms), without thinking about the 2nd (multithreading + asynchrony) and 3rd (distribution). This method of isolating abstractions would significantly increase the simplicity, reliability, and speed of writing code. Unfortunately, at the moment it is possible only in dreams.
However, separate abstractions allow for relative isolation. One of the typical examples is the use of coroutines , where instead of asynchronous code we get synchronous, i.e. we move from the 2nd stage to the 1st, which allows us to significantly simplify the writing and maintenance of the code.
The article consistently reveals the use of lock-free algorithms for building robust consistent distributed scalable real-time systems, i.e. how lock-free achievements of the 2nd stage help in the implementation of the 3rd, reducing the task to single-threaded algorithms of the 1st stage.
Formulation of the problem
This task only illustrates some important approaches and is presented as an example for introducing the context into the context. It is easy to generalize it to more complex cases, which will be done later.
Task: processing streaming data in real time .
There are two streams of numbers. The handler reads the data of these input streams and selects the last numbers for a certain period. These numbers are averaged over this time interval, i.e. in a sliding data window for a specified time. The resulting average value must be recorded in the output queue for further processing. In addition, if the number of numbers in the window exceeds a certain threshold, then increase by one the counter in the external transaction database.
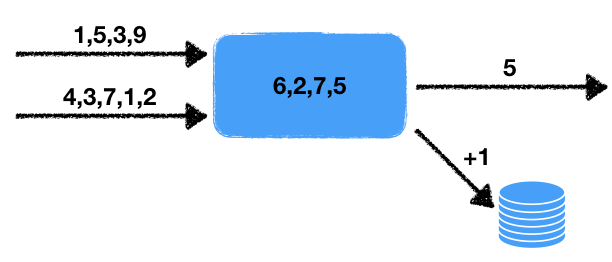
We note some features of this problem.
- Non-determinism There are two sources of non-deterministic behavior: these are reading from two streams, as well as a time window. It is clear that the reading can be done in different ways, and the final result will depend on the sequence in which the data will be extracted. The time window also changes the result from launch to launch, because the speed of work will depend on the amount of data in the window.
- The state of the handler . There is a handler state in the form of a set of numbers in the window, on which the current and subsequent work results depend. Those. we have a stateful handler.
- Interaction with external storage . It is necessary to update the counter value in the external database. The principal point is that the type of external storage differs from the storage of the state of the handler and the threads.
All this, as will be shown below, seriously affects the tools used and the possible ways of implementation.
It remains to add a small bar to the task, which immediately translates the task from the area of extreme complexity into the impossible area: the guarantee is necessary concurrent exactly-once .
Exactly-once
Exactly once is often interpreted too widely, which emasculates the term itself, and it stops responding to the original requirements of the problem. If we are talking about a system that works locally on one computer - then everything is simple: take more, throw further. But in this case we are talking about a distributed system, in which:
- The number of handlers can be large: each processor handles its own piece of data. At the same time, the results can be put in different places, for example, an external database, possibly even sharding.
- Each handler can suddenly stop its processing. Failsafe system implies the continuation of work even in case of failure of individual parts of the system.
Thus, we must be prepared for the fact that the handler may fall, and another handler must pick up the work already done and continue processing.
Here the question immediately arises: what exactly will mean exactly once in the case of a non-deterministic handler? After all, every time we restart, we will receive, generally speaking, different resulting states. The answer here is simple: with exactly-once, there is such an execution of the system in which each input value was processed exactly once, giving a corresponding output result. At the same time, this execution does not have to be physically on the same node. But the result should be as if everything were processed on some one logical node without crashing.
Concurrent exactly-once
To aggravate the requirements, we introduce a new concept: concurrent exactly-once . The principal difference from the simple exactly-once is the absence of pauses during processing, as if everything was processed on one node without drops and without pauses . In our problem, we will require exactly concurrent exactly-once , for simplicity, in order not to consider comparison with existing systems that are not available today.
The consequences of such a requirement will be discussed below.
Transactional
To make the reader feel more deeply about the difficulty that has arisen, let's consider various bad scenarios that need to be considered when developing such a system. We will also try to use a common approach that will allow us to solve the above problem, taking into account our requirements.
The first thing that comes to mind is the need to record the state of the handler and the input and output streams. The state of the output streams is described by a simple queue of numbers, and the state of the input streams is described by their position. In fact, the flow is an endless queue, and the position in the queue uniquely specifies the location.

There is the following naive implementation of the handler using some kind of data storage. At this stage, the specific properties of the storage will not be important to us. We will use the Pseko language to illustrate the idea (Pseko: = pseudo code):
handle(input_queues, output_queues, state): # input_indexes = storage.get_input_indexes() # while true: # items, new_input_indexes = input_queues.get_from(input_indexes) # state.queue.push(items) # duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) output_queues[0].push(avg) if need_update_counter: # (B) db.increment_counter() # (C) storage.save_state(state) # (D) storage.save_queue_indexes(new_input_indexes) # (E) input_indexes = new_input_indexes
Here is a simple single-threaded algorithm that reads data from input streams and records the necessary values according to the task described above.
Let's see what will happen in case of a node crash at arbitrary points in time, as well as after resuming work. It is clear that in case of a drop in the points (A) and (E) everything will be fine: either the data have not yet been recorded and we will simply restore the state and continue on another node, or all the necessary data have already been recorded and just continue the next step.
However, in case of a fall at all other points, unexpected troubles await us. If a crash occurs at point (B) , then when the handler is restarted, we will restore the states and re-write the average value at about the same interval of numbers. In the case of a fall at point (C) in addition to a duplicate of the average, a duplicate will appear in increment of value. And in the case of a fall in (D) we get the inconsistent state of the handler: the state corresponds to the new point in time, and we will read the values from the input streams old.

In this case, when rearranging write operations, nothing fundamentally changes: inconsistency and duplicates will remain so. Thus, we conclude that all actions to change the state of the handler in the repository, the output queue and the database should be performed transactionally, i.e. all at the same time and atomically.
Accordingly, it is necessary to develop a mechanism so that different storages can change their state transactionally, and not inside each independently, but transactionally between all storages simultaneously. Of course, you can put our repository inside an external database, but the task assumed that the database engine and the framework for processing streaming data are separated and work independently of each other. Here I want to consider the most difficult case, because simple cases considered uninteresting.
Competitive responsiveness
Consider concurrent execution exactly once in more detail. In the case of a fault-tolerant system, we require the continuation of work from a certain point. It is clear that this point will be some point in the past, because to preserve performance, it is impossible to save all moments of state change in the present and future in the storage: either the last result of operations or a group of values for increasing throughput is saved. This behavior immediately leads us to the fact that after restoring the state of the handler, there will be some delay in the results, it will grow with an increase in the size of the group of values and the size of the state.
In addition to this delay, there are also delays in the system associated with loading the state to another node. In addition, the detection of a problem node also takes some time, and often quite a lot. This is due primarily to the fact that if we set a short detection time, then frequent false alarms are possible, which will lead to all sorts of unpleasant special effects.
In addition, with the increase in the number of parallel handlers, it suddenly turns out that not all of them work equally well even in the absence of failures. Sometimes blunts occur, which also lead to delays in processing. The reason for such blunts can be varied:
- Software : GC pauses, memory fragmentation, allocator pauses, kernel interruption and task scheduling, problems with device drivers causing slower work.
- Hardware : high load on the disk or network, CPU throttling due to cooling problems, overload, etc., slowing down the disk due to technical problems.
And this is not an exhaustive list of problems that can lead to slower handlers.
Accordingly, the slowdown is a reality with which one has to live. Sometimes this is not a serious problem, and sometimes it is extremely important to maintain a high processing speed despite failures or slowdowns.
Immediately, the idea of duplication of systems arises: we will launch not one but two processors for the same data stream, or even three processors. The problem here is that in this case duplicates and inconsistent behavior of the system can easily arise. Usually, frameworks are not designed for this behavior and assume that the number of handlers at each time point does not exceed one. Systems that allow the described duplication of execution are called concurrent exactly-once .
This architecture allows us to solve several problems at once:
- Fail-safe behavior: if one of the nodes falls, then the other just continues to work as if nothing had happened. There is no need for additional coordination, because the second handler is executed regardless of the state of the first.
- Removal of blunts: who first provided the result, he did well. The other will just have to pick up a new state and continue from now on.
Such an approach, in particular, makes it possible to complete a complicated, heavy, long settlement in a more predictable time, since the likelihood that both will blunt and fall significantly less.
Probabilistic assessment
Let us try to evaluate the advantages of duplication of performance. Suppose, on average, something happens to the handler every day: either GC is blunted, or the node is lying, or the containers have become cancer. Suppose we also prepare data bursts in 10 seconds.
Then the probability that something will happen during the creation of the pack is 10 / (24 · 3600) ≃ 1e-4 .
If you run two handlers in parallel, then the probability that both poploheet ≃ 1e-8 . So this event will come in 23 years! Yes, the system does not live so much, so this will never happen!
Moreover, if the preparation time of the pack will be even less and / or blunts will occur even less often, then this figure will only increase.
Thus, we conclude that the approach under consideration significantly increases the reliability of our entire system. It remains only to solve a small question: where to read about how to make a concurrent exactly once system. And the answer is simple: here it is necessary to read.
Semi-transactions
For further presentation, we need the concept of semitransaction . The easiest way to explain it is by example.
Consider transferring funds from one bank account to another. The traditional approach using Pseco transactions can be described as follows:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
However, what to do if such transactions are not available to us? Using locks, this can be done as follows:
transfer(from, to, amount): # lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
This approach can lead to deadlocks, because locks can be taken in different sequences in parallel. To correct this behavior, it is enough to enter a function that simultaneously takes several locks in a deterministic sequence (for example, sorts by key), which completely eliminates possible deadlocks.
However, the implementation can be somewhat simplified:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # , # .. db.set(db.get...) lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
Such an approach also makes the final state consistent, preserving invariants of the type of preventing unnecessary expenditure of funds. The main difference from the previous approach is that in such an implementation we have a certain period of time in which the accounts are in a non-consistent state. Namely, such an operation implies that the total state of funds in the accounts does not change. In this case, there is a time gap between lock_from.release() and db.lock(to) , during which the database may produce a non-consistent value: the total amount may differ from the correct one in a smaller direction.
In fact, we broke one money transfer transaction into two half-transactions:
- The first half-transaction does the checking and withdraws the necessary amount from the account.
- The second half-transaction records the withdrawn amount to another account.
It is clear that fragmentation of a transaction into smaller ones, generally speaking, violates transactional behavior. And the above example is no exception. However, if all semi-transactions in chains are fully executed, the result will be consistent with all invariants preserved. This is an important property of the chain of half-transactions.
By temporarily losing some consistency, we nevertheless acquire another useful feature: independence of operations, and, as a result, better scalability. Independence is manifested in the fact that half-transaction each time works with only one line, reading, checking and changing its data, without communicating with other data. This way you can shard a database whose transactions work with only one shard. Moreover, this approach can be used in the case of heterogeneous storages, i.e. half-transactions can begin on one type of storage and end on another. Such useful properties will be used in the future.
A natural question arises: how to implement semi-translations in distributed systems and not ogresti? To resolve this issue, it is necessary to consider the lock-free approach.
Lock-free
As is known, lock-free approaches sometimes improve the performance of multi-threaded systems, especially in the case of competitive access to a resource. However, it is not at all obvious that such an approach can be used in distributed systems. Let's dig into the depths and consider what lock-free is and why this property will be useful in solving our problem.
Some developers sometimes do not quite clearly imagine what a lock-free is. The narrow-minded look suggests that this is something related to atomic processor instructions. Here it is important to understand that lock-free means the use of “atomics”, the opposite is not true, i.e. not all “atomic” give lock-free behavior.
An important property of the lock-free algorithm is that at least one thread makes progress in the system. But for some reason, many of this property is given for definition (such a blunt definition can be found, for example, in Wikipedia ). Here it is necessary to add one important nuance: progress is made even in the case of blunts of one or several streams. This is a very critical moment that is often overlooked, with serious consequences for a distributed system.
Why does the absence of a progress condition of at least one thread negate the notion of a lock-free algorithm? The fact is that in this case the usual spinlock will also be lock-free. Indeed, the one who took the lock will make progress. There is a stream with progress => lock-free?
Obviously, the lock-free stands for no locks, while spinlock by its name means that it is a real lock. That is why it is important to add a condition about progress, even in the case of blunts. After all, these delays can last indefinitely for a long time, because the definition says nothing about the upper time boundary. And if so, then such delays will be equivalent in some sense to shutting down the streams. In this case, lock-free algorithms will produce progress in this case.
But who said that lock-free approaches are applicable exclusively for multi-threaded systems? Replacing the threads in the same process on the same node with the processes on different nodes, and the shared memory of the threads with the shared distributed storage, we get a lock-free distributed algorithm.
The fall of a node in such a system is equivalent to delaying the execution of the thread for a while, since for restoration of work this time is necessary. At the same time, the lock-free approach allows other participants in the distributed system to continue working. Moreover, special lock-free algorithms can be run in parallel with each other, detecting a competitive change and cutting duplicates.
The exactly-once approach implies the presence of a consistent distributed storage. Such storages as a rule represent a huge persistent key-value table. Possible operations: set , get , del . However, a more complicated operation is required for the lock-free approach: CAS or compare-and-swap. Let us consider in more detail this operation, the possibilities of its use, as well as what results it gives.
CAS
CAS or compare-and-swap is the main and important synchronization primitive for lock-free and wait-free algorithms. Its essence can be illustrated by the following Pseco:
CAS(var, expected, new): # , atomic, atomic: if var.get() != expected: return false var.set(new) return true
Sometimes, for optimization, they return not the true or false , but the previous value, since very often such operations are performed in a cycle, and to get the expected value, you first need to read it:
CAS_optimized(var, expected, new): # , atomic, atomic: current = var.get() if current == expected: var.set(new) return current # CAS CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
This approach can save one reading. As part of our consideration, we will use a simple form of CAS , since If desired, such optimization can be done independently.
In the case of distributed systems, each change is versioned. Those. we first read the value from the repository, retrieving the current version of the data. And then we try to write, expecting that the version of the data has not changed. At the same time, the version is incremented each time the data is updated:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
This approach allows you to more accurately control the update values, avoiding the problem of ABA . In particular, versioning is supported by Etcd and Zookeeper.
Note the important property that gives the use of CAS_versioned operations. The fact is that such an operation can be repeated without harming the higher logic. In multithreaded programming this property has no special value, since there if the operation failed, then we know for sure that it did not apply. In the case of distributed systems, this invariant is violated, since the request may reach the recipient, and the successful response is no longer. Therefore, it is important to be able to re-send requests without fear of violating high-level logic invariants.
This property is what the CAS_versioned operation CAS_versioned . In fact, you can endlessly repeat this operation until the real answer from the recipient returns. That, in turn, throws out a whole class of errors associated with network interaction.
Example
Let's take a look at how, based on CAS_versioned and half-transaction, to transfer from one account to another, which belong, for example, to different instances of Etcd. Here, I assume that the CAS_versioned function CAS_versioned already implemented appropriately based on the provided API.
withdraw(from, amount): # CAS- while true: # version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS- while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
Here we have broken our operation into half-transactions, and each half-transaction is performed through the operation CAS_versioned . This approach allows you to work independently with each account, allowing the use of heterogeneous storage, unrelated to each other. The only problem that awaits us here is the loss of money if the current process falls between the half-transactions.
Turn
In order to go further, it is necessary to implement a queue of events. The idea is that to communicate handlers with each other, you must have an ordered message queue, in which data is not lost or duplicated. Accordingly, all interaction in the chain of handlers will be built on this primitive. It is also a useful tool for analyzing and auditing incoming and outgoing data streams. In addition, mutations of the states of the handlers can also be made through a queue.
The queue will consist of a pair of operations:
- Add a message to the end of the queue.
- Receiving a message from the queue at a given index.
In this context, I do not consider deleting messages from the queue for several reasons:
- Several handlers can read from the same queue. Synchronization of deletion will be a non-trivial task, although not impossible.
- It is useful to keep the queue at a relatively long interval (day or week) for the possibility of debugging and auditing. The usefulness of this property is difficult to overestimate.
- You can delete old items either according to the schedule or by placing TTL on the elements of the queue. It is important to ensure that the handlers have time to process the data before the broom arrives and cleans everything up. If the processing time is about seconds, and TTL is about days, then nothing like this should happen.
For the storage of elements and the effective implementation of the addition we need:
- Value with current index. This index indicates the end of the queue for adding items.
- , .
lock-free
: . :
- CAS .
- .
, , .
- lock-free . , , . Lock-free? Not! , 2 : . lock-free, — ! , , , . . , .. , .
- . , . .
, lock-free .
Lock-free
, , : , .. , :
push(queue, value): # index = queue.get_current_index() while true: # , # var = queue.at(index) # = 0 , .. # , if var.CAS_versioned(0, value): # , queue.update_index(index + 1) break # , . index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # cur_index, version = queue.get_current_index_versioned() # , # , . if cur_index >= index: # - , # break if queue.current_index_var().CAS_versioned(version, index): # , break # - . # , ,
. , ( — , , ). lock-free . ?
, push , ! , , .
. : . , - , - . , , .. . . ? , .. , , .
, , . Those. . , , . , .
, . , . , , . , .
, , , .
. .
, :
- , .. stateless.
- , — .
, , concurrent exactly-once .
:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
. :
handle(input, output, state): # index = state.get() while true: value = input.get(index) output.push(value) index += 1 # state.set(index)
exactly-once . , , , .
exactly-once , , . .., , , , , — :
# get_next_index(queue): index = queue.get_index() # while queue.has(index): # queue.push index = max(index + 1, queue.get_index()) return index # . # true push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # queue.update_index(index + 1) return true return false handle(input, output, state): # # {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # : , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # , input_index += 1 # , push_at false, # fsm_state = {PREPARING, input_index} state.set(fsm_state)
push_at ? , . , , , . , . . - , lock-free .
, :
- : .
- , : .
: concurrent exactly-once .
? :
- , ,
push_at false. . - , . , , .
concurrent exactly-once ? , , . , . .
:
# , , # .. true, # true. # false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # , , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # , # if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

, . , .
kernel panic, , .. . . : , . , .
, , .
: .
: , , , , :
# : # - input_queues - # - output_queues - # - state - # - handler - : state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes case {HANDLING, user_state, input_indexes}: # inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # , next_indexes = next(inputs, input_indexes) # # user_state, outputs = handler(user_state, inputs) # , # fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # , # output_index = output_queues[output_pos].get_next_index() # fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # if output_queues[output_pos].push_at_idempotent( value, output_index ): # , output_pos += 1 # , PREPARING. # # fsm_state = if output_pos == len(outputs): # , # {HANDLING, user_state, input_indexes} else: # # , # {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

: HANDLING . , .., , . , . , PREPARING WRITING , . , HANDLING .
, , , . , . , .
. . .

:
my_handler(state, inputs): # state.queue.push(inputs) # duration state.queue.trim_time_window(duration) # avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none none ]
, , concurrent exactly-once handle .
:
handle_db(input_queue, db): while true: # tx = db.begin_transaction() # . # , # index = tx.get_current_index() # tx.write_current_index(index + 1) # value = intput_queue.get(index) if value: # tx.increment_counter() tx.commit() # , , #
. Since , , , , concurrent exactly-once . .
— . , , .
, , . , , .
. , . Since , . . .
— . , , . , - , , . , .. , , .
. , , . , , .
. , . : , . , .
, , :
- , . .
- . , .
- . , . , , . Those. . : .
, , -, , -, .
, . :
transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
withdraw , , deposit : ? deposit - (, , ), . , , , , ? , , - , .
, , , . , , , . , . , , . Since , , . , : , — .
, .
: , , , , . , - :
, , .
, , .. , , . , .
: lock-free , . , .. , .
CAS . , :
# , handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # ... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # , output_index
, . . :
- PREPARING . , .
- WRITING . . , PREPARING .
, . , , — . :
- . , , .. , .
- , .. . , .
, lock-free , , .
, . , Stale Read , . — CAS: . :
- Distributed single register — (, etcd Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — (, MySQL, PostgreSQL ..):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL :
- Strict Consistency
: ? , , . , , CAS . , , Read My Writes .
Conclusion
exactly-once . , .. , , , . , , , , .. , .
lock-free .
:
- : .
- : .
- : : exactly-once .
- Concurrent : .
- Real-time : .
- Lock-free : , .
- Deadlock free : , .
- Race condition free : .
- Hot-hot : .
- Hard stop : .
- No failover : .
- No downtime : .
- : , .
- : .
- : .
- : .
, . But that's another story.

:
- Concurrent exactly-once.
- Semi-transactions .
- Lock-free two-phase commit, .
- .
- lock-free .
- .
Literature
[1] : ABA.
[2] Blog: You Cannot Have Exactly-Once Delivery
[3] : .
[4] : 3: .
[5] : .