Hello, my name is Dmitry Karlovsky and I am ... unemployed. Therefore, I have a lot of free time for practicing music, sports, creativity, languages, JS-conferences and computer science. About the latest research in the field of semi-automatic partitioning of long calculations into small quanta for several milliseconds, as a result of which a miniature $mol_fiber library $mol_fiber , I will tell you today. But first, let's designate the problems that we will solve ..
This is a text version of the same-name performance on HolyJS 2018 Piter . You can either read it as an article , or open it in the presentation interface , or watch a video .
Issue: Low responsiveness
If we want to have a stable 60 frames per second, then we have only 16 with a trifle of milliseconds to do all the work, including what the browser does to show the results on the screen.
But what if we take the stream for a longer time? Then the user will observe the lagging interface, the slowing animation, and similar UX deterioration.

Issue: No escape
It happens that while we perform calculations, the result is no longer interesting to us. For example, we have a virtual scroll, the user is actively pulling it, but we do not keep up with it and cannot render the actual area until the rendering of the previous one returns control to us to handle user events.

Ideally, no matter how long the work we performed, we should continue to process events and be able to cancel the work that has been started, but not yet completed, at any time.
I'm fast and i know it
But what if our work is not one, but several, but the flow is one? Imagine that you drive on your newly acquired yellow lotus and drive up to the railway crossing. When it is free, you can slip it in a split second. But..

Issue: No concurrency
When the crossing is occupied by a kilometer train, you have to stand and wait ten minutes until it passes. Not for that, you bought a sports car, right?

And how cool it would be if this line was broken into 10 trains of 100 meters each and there would be a few minutes between them to get through! You would not be too long then.
So, what are the current solutions to these problems in the JS world?
Solution: Workers
The first thing that comes to mind: but let's just carry out all the complex calculations in a separate thread? To do this, we have a mechanism for WebWorkers.

Events from the UI stream are transmitted to the worker. There they are processed and instructions are already sent back to what and how to change on the page. Thus, we eliminate the UI stream from a large reservoir of computations, but problems are not all solved in this way, and in addition new ones are added.
Workers: Issues: (De) Serialization
Communication between threads occurs by sending messages that are serialized to the byte stream, transferred to another stream, and there they are sent to objects. All this is much slower than a direct method call within a single thread.

Workers: Issues: Asynchronous only
Messages are transmitted strictly asynchronously. And this means that some of the features you ask for are not available. For example, you cannot stop the ascent of a ui-event from a worker, since by the time the handler is started, the event in the UI thread has already completed its life cycle.
Workers: Issues: Limited API's
The following API is not available to the workers.
- DOM, CSSOM
- Canvas
- GeoLocation
- History & Location
- Sync http requests
- XMLHttpRequest.responseXML
- Window
Workers: Issues: Can't cancel
And again, we have no way to stop the calculations in the wok.

Yes, we can stop the whole worker, but it will stop all the tasks in it.
Yes, you can run each task in a separate worker, but this is very resource intensive.
Solution: React Fiber
Surely, many have heard how FaceBook heroically rewrote React, breaking all the calculations in it into a bunch of small functions that are started by a special scheduler.
I will not go into details of its implementation, as this is a separate big topic. I note only some of the features due to which it may not suit you ..
React Fiber: React required
Obviously, if you use Angular, Vue or another framework other than React, then React Fiber is useless for you.

React Fiber: Only rendering
React - covers only the rendering layer. All other layers of the application are left without any quantization.

React Fiber will not save you when you need, for example, to filter a large block of data by tricky conditions.
React Fiber: Quantization is disabled
Despite the declared support for quantization, it is still turned off by default, as it breaks backward compatibility.

Quantizing in React is still an experimental thing. Be careful!
React Fiber: Debug is pain
When you turn on quantization, the callstack ceases to match your code, which significantly complicates debugging. But we will return to this issue.

Solution: quantization
Let's try to summarize the React Fiber approach so as to get rid of the mentioned drawbacks. We want to stay within one stream, but break long calculations into small quanta, between which the browser can render changes already made to the page, and we respond to events.
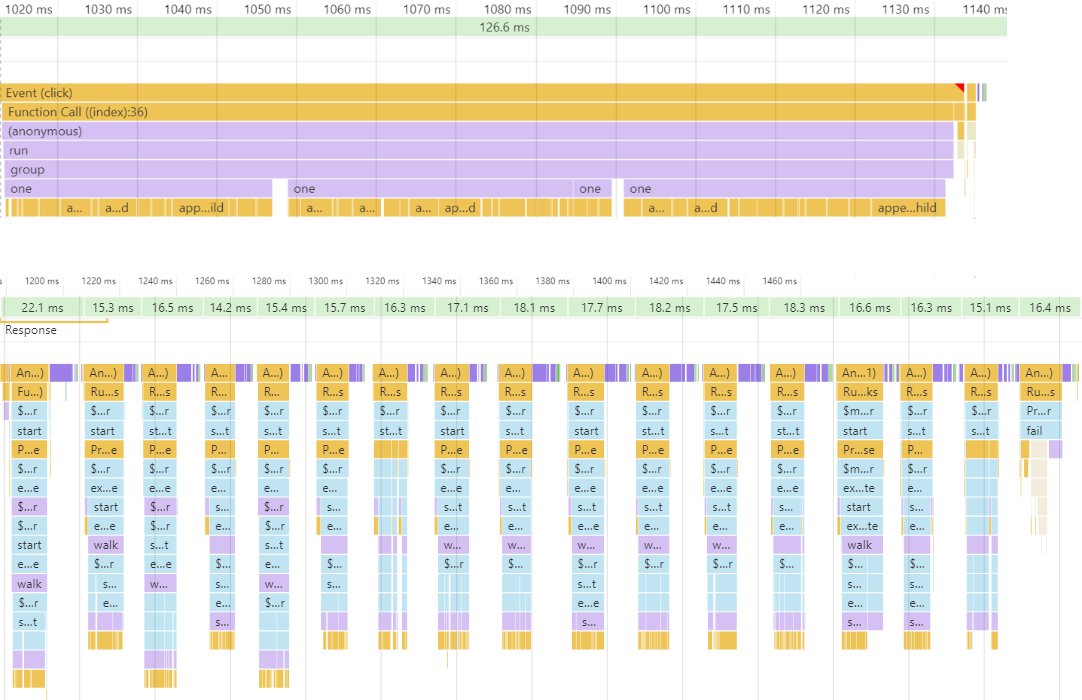
Above, you see a long calculation that stopped the whole world for more than 100ms. And from the bottom - the same calculation, but divided into time slices of about 16 ms, which gave an average of 60 frames per second. Since, as a rule, we don’t know how much time it will take to calculate, we can’t manually break it into pieces by 16ms in advance. therefore, we need some kind of runtime mechanism that measures the time of task execution and when the quantum size is exceeded, pausing the execution until the next frame of the animation. Let's think about what mechanisms we have for implementing such suspended tasks ..
Concurrency: fibers - stackfull coroutines
In languages such as Go and D, there is an idiom like "coroutine with stack", aka "fiber" or "fiber".
import { Future } from 'node-fibers' const one = ()=> Future.wait( future => setTimeout( future.return ) ) const two = ()=> one() + 1 const three = ()=> two() + 1 const four = ()=> three() + 1 Future.task( four ).detach()
In the example code, you can see the one function, which can pause the current fayber, but at the same time it has quite a synchronous interface. The two , three and four functions are normal synchronous functions that do not know anything about the filers. In them you can use all the features of javascript in full. And finally, on the last line, we simply run the four function in a separate file server.
It is quite convenient to use the faybers, but for their support you need support for runtime, which most JS interpreters do not have. However, for NodeJS there is a node-fibers native extension that adds this support. Unfortunately, no faybery are available in any browser.
Concurrency: FSM - stackless coroutines
In languages like C # and now JS, there is support for "stringless coroutines" or "asynchronous functions." Such functions are a state machine under the hood and do not know anything about the stack, so they have to be marked with the special keyword "async", and the places where they can be suspended are "await".
const one = ()=> new Promise( done => setTimeout( done ) ) const two = async ()=> ( await one() ) + 1 const three = async ()=> ( await two() ) + 1 const four = async ()=> ( await three() ) + 1 four()
Since we may need to postpone the calculation at any time, it turns out that we have to do almost all the functions in the application as asynchronous. This is not only that the complexity of the code, so also strongly beats on performance. In addition, many APIs that accept callbacks still do not support asynchronous callbacks. A striking example is the reduce method of any array.
Concurrency: semi-fibers - restarts
Let's try to do something similar to the faybera, using only those features that are available to us in any modern browser ..
import { $mol_fiber_async , $mol_fiber_start } from 'mol_fiber/web' const one = ()=> $mol_fiber_async( back => setTimeout( back ) ) const two = ()=> one() + 1 const three = ()=> two() + 1 const four = ()=> three() + 1 $mol_fiber_start( four )
As you can see, the intermediate functions do not know anything about the interruption - this is the usual JS. Only function one knows about the possibility of suspension. To interrupt the calculation, she simply throws Promise as an exception. On the last line, we run the four function in a separate pseudo-fayber, which keeps track of exceptions thrown inside and if Promise arrives for it, then subscribe to its resolve to restart the fayber.
To show how pseudo-fiberers work, let's write not tricky code ..

Let's imagine that the step function writes something to the console and does some hard work for 20ms. And the walk function calls step twice, logging the entire process. In the middle will show what is now displayed in the console. And on the right, the state of the pseudo-faibers tree
$ mol_fiber: no quantization
Let's run this code and see what happens ..

So far, everything is simple and obvious. The pseudo-fiber tree is, of course, not involved. And everything would be fine, but this code is executed over 40 ms, which is no good.
$ mol_fiber: cache first
Let's wrap both functions in a special wrapper that launches it in a pseudo-file and see what happens ..

Here you should pay attention to the fact that for each place of calling the one function inside the walk fayber, a separate fayber was created. The result of the first call was cached, but instead of the second, Promise was thrown, since we had exhausted our time slice.
$ mol_fiber: cache second
A Promise dropped in the first frame will be automatically killed in the next one, which will restart the walker file.

As you can see, because of the restart, we again brought "start" and "first done" to the console, but the "first begin" no longer exists, since it is in the file with the cache filled earlier, which is why its handler is more not called. When the cache of the fieber walk is filled, all nested faybera are destroyed, since execution will never reach them.
So why first begin deduced once, and first done - two? It's all about idempotency. console.log is a nonidempotent operation, how many times you call it up, so many times it will add an entry to the console. But a fayber performing in another fayber is idempotent, it executes a hendlen only on the first call, and on subsequent ones it immediately returns the result from the cache, without leading to any additional side effects.
$ mol_fiber: idempotence first
Let's wrap console.log into fayber, thus making it idempotent, and see how the program behaves ..

As you can see, we now have entries in the file tree for each call to the log function.
$ mol_fiber: idempotence second
The next time you restart the walker file, repeated calls to the log function no longer result in calls to the real console.log , but as soon as we reach the execution of the filers with the cache empty, the console.log calls are resumed.

Please note that in the console, we now do not display anything extra - exactly what would be displayed in the synchronous code without any faders and quantification.
$ mol_fiber: break
How is the interruption of the calculation? At the beginning of the quantum set deadline. And before launching each fayber, it is checked whether we have reached it. And if they have reached, then Promise rushes, which is resolved in the next frame already and starts a new quantum ..
if( Date.now() > $mol_fiber.deadline ) { throw new Promise( $mol_fiber.schedule ) }
$ mol_fiber: deadline
The deadline for a quantum is simple. To the current time is added 8 milliseconds. Why exactly 8, because there are as many as 16 for training a frame? The fact is that we don’t know in advance how long the browser will need to render, so we need to leave some time for it to work. But sometimes it happens that the browser does not need to render anything, and then at 8ms quanta we can stick another quantum into the same frame, which will give a dense packing of quanta with minimal processor downtime.
const now = Date.now() const quant = 8 const elapsed = Math.max( 0 , now - $mol_fiber.deadline ) const resistance = Math.min( elapsed , 1000 ) / 10
But if we just throw an exception every 8ms, then debugging with an exception stop enabled will turn into a small branch of hell. We need some kind of mechanism to detect this debugger mode. Unfortunately, this can only be understood indirectly: a person needs a time on the order of a second in order to understand whether to continue playing or not. This means that if the control did not return to the script for a long time, then either the debugger was stopped or there was a heavy calculation. To sit on both chairs, we add to the quantum 10% of the elapsed time, but not more than 100 ms. This does not greatly affect the FPS, but it reduces by an order of magnitude the stopping frequency of the debugger due to quantization.
Debug: try / catch
If we are talking about debugging, how do you think where in this code the debugger will stop?
function foo() { throw new Error( 'Something wrong' ) // [1] } try { foo() } catch( error ) { handle( error ) throw error // [2] }
As a rule, it is necessary that he stay where the exception is thrown for the first time, but the reality is that he only stops where it was last thrown, which is usually very far from the place of its origin. Therefore, in order not to complicate debugging, exceptions should never be caught, via try-catch. But completely without exception handling is impossible.
Debug: unhandled events
Typically, runtime provides a global event that occurs for each uncaught exception.
function foo() { throw new Error( 'Something wrong' ) } window.addEventListener( 'error' , event => handle( event.error ) ) foo()
In addition to being cumbersome, this solution has such a flaw that all exceptions fall here at all and it is rather difficult to understand from which filer and filer the event occurred.
Debug: Promise
The best solution for exception handling is promises ..
function foo() { throw new Error( 'Something wrong' ) } new Promise( ()=> { foo() } ).catch( error => handle( error ) )
The function passed to the Promise is called immediately, synchronously, but the exception is not intercepted and safely stops the debugger at the place of its occurrence. A little later, asynchronously, it already calls an error handler, in which we know exactly which filer failed and which one failed. This is exactly the mechanism used in $ mol_fiber.
Stack trace: React Fiber
Let's take a look at the glass rays you get at React Fiber ..
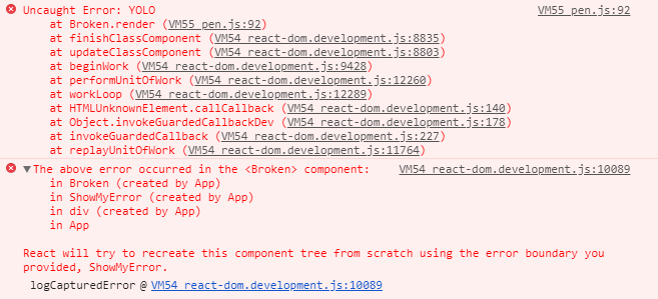
As you can see, we get a lot of React intestines. From the useful here only the point of occurrence of the exception and the names of the components above the hierarchy. Not much.
Stack trace: $ mol_fiber
In $ mol_fiber, we get a much more useful structure: no guts, only specific points in the application code through which it came to an exception.
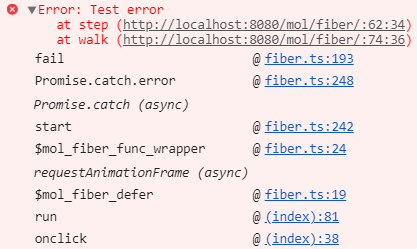
This is achieved through the use of the native stack, promises and automatic removal of guts. If you wish, you can expand the error in the console, as in the screenshot, and see the guts, but there is nothing interesting.
$ mol_fiber: handle
So, to break a quantum, Promise rushes.
limit() { if( Date.now() > $mol_fiber.deadline ) { throw new Promise( $mol_fiber.schedule ) }
But, as you can guess, a Promise can be absolutely any - generally speaking, it’s not important for a file to wait for the next frame, the completion of data loading or something else ..
fail( error : Error ) { if( error instanceof Promise ) { const listener = ()=> self.start() return error.then( listener , listener ) }
Fiber simply subscribes to resolve promises and restarts. But manually throwing and catching promises is not necessary, because the kit includes several useful wrappers ..
$ mol_fiber: functions
To turn any synchronous function into an idempotent fayber, simply wrap it in $mol_fiber_func ..
import { $mol_fiber_func as fiberize } from 'mol_fiber/web' const log = fiberize( console.log ) export const main = fiberize( ()=> { log( getData( 'goo.gl' ).data ) } )
Here we made console.log idempotent, and main taught to interrupt while waiting for the download.
$ mol_fiber: error handling
But how to respond to exceptions if we don’t want to use try-catch ? Then we can register an error handler with $mol_fiber_catch ...
import { $mol_fiber_func as fiberize , $mol_fiber_catch as onError } from 'mol_fiber' const getConfig = fiberize( ()=> { onError( error => ({ user : 'Anonymous' }) ) return getData( '/config' ).data } )
If we return something different from the error in it, it will be the result of the current fayber. In this example, if it is impossible to download the config from the server, the getConfig function will return the config by default.
$ mol_fiber: methods
Of course, you can wrap up not only the functions, but also the methods, through the decorator ..
import { $mol_fiber_method as action } from 'mol_fiber/web' export class Mover { @action move() { sendData( 'ya.ru' , getData( 'goo.gl' ) ) } }
Here, for example, we downloaded the data from Google and uploaded it to Yandex.
$ mol_fiber: promises
To load data from the server, it is enough to take, for example, the asynchronous function fetch and turn it into a synchronous one with a slight movement of the hand ..
import { $mol_fiber_sync as sync } from 'mol_fiber/web' export const getData = sync( fetch )
This implementation is good for everyone, but it doesn’t support canceling a request when a faber tree is destroyed, so we need to use a more confused API ..
$ mol_fiber: cancel request
import { $mol_fiber_async as async } from 'mol_fiber/web' function getData( uri : string ) : Response { return async( back => { var controller = new AbortController(); fetch( uri , { signal : controller.signal } ).then( back( res => res ) , back( error => { throw error } ) , ) return ()=> controller.abort() } ) }
The function passed to the async wrapper is called only once and the back wrapper is passed to it in which the callbacks are wrapped. Accordingly, in these callbacks, you must either return the value or throw an exception. Whatever the result of the callback’s work, it will be the result of the fieber. Note that at the end we return a function that will be called in the event of premature destruction of the fiber.
$ mol_fiber: cancel response
From the server side, it may also be useful to cancel the calculations when the client has fallen off. Let's implement a wrap over midleware , which will create a fayber, in which the original midleware will be launched. , , , .
import { $mol_fiber_make as Fiber } from 'mol_fiber' const middle_fiber = middleware => ( req , res ) => { const fiber = Fiber( ()=> middleware( req , res ) ) req.on( 'close' , ()=> fiber.destructor() ) fiber.start() } app.get( '/foo' , middle_fiber( ( req , res ) => { // do something } ) )
$mol_fiber: concurrency
, . , 3 : , , - ..

: , . . , , .
$mol_fiber: properties
, ..
Pros:
- Runtime support isn't required
- Can be cancelled at any time
- High FPS
- Concurrent execution
- Debug friendly
- ~ 3KB gzipped
Cons:
- Instrumentation is required
- All code should be idempotent
- Longer total execution
$mol_fiber — , . — , . , , . , , , , . , . .
Links
Call back

: , , )
: , .
: . , .
: . , . , .
: , . , )
: , .
: - . , , .
: . , , .
: , . 16ms, ? 16 8 , 8, . , . , «».
: — . Thank!
: . , . Loved it!
: , . .
: , , , , , / , .
: , .
: .
: , . mol.
: , , . , , , .
: .
: , . , $mol, , .
: , , . — . .
: - , .
: $mol , . (pdf, ) , .
: , . , .
: , ) .
: . .
: In some places I missed what the reporter was saying. The conversation was about how to use the "Mola" library and "why?". But how it works remains a mystery for me.To smoke an source code is for the overhead.
: , .
: . , . . .
: : . - (, ). , : 16?
: . . , mol_fiber … , 30fps 60fps — . — .