Or how I ended up in the winning team of the Machines Can See 2018 adversarial competition.
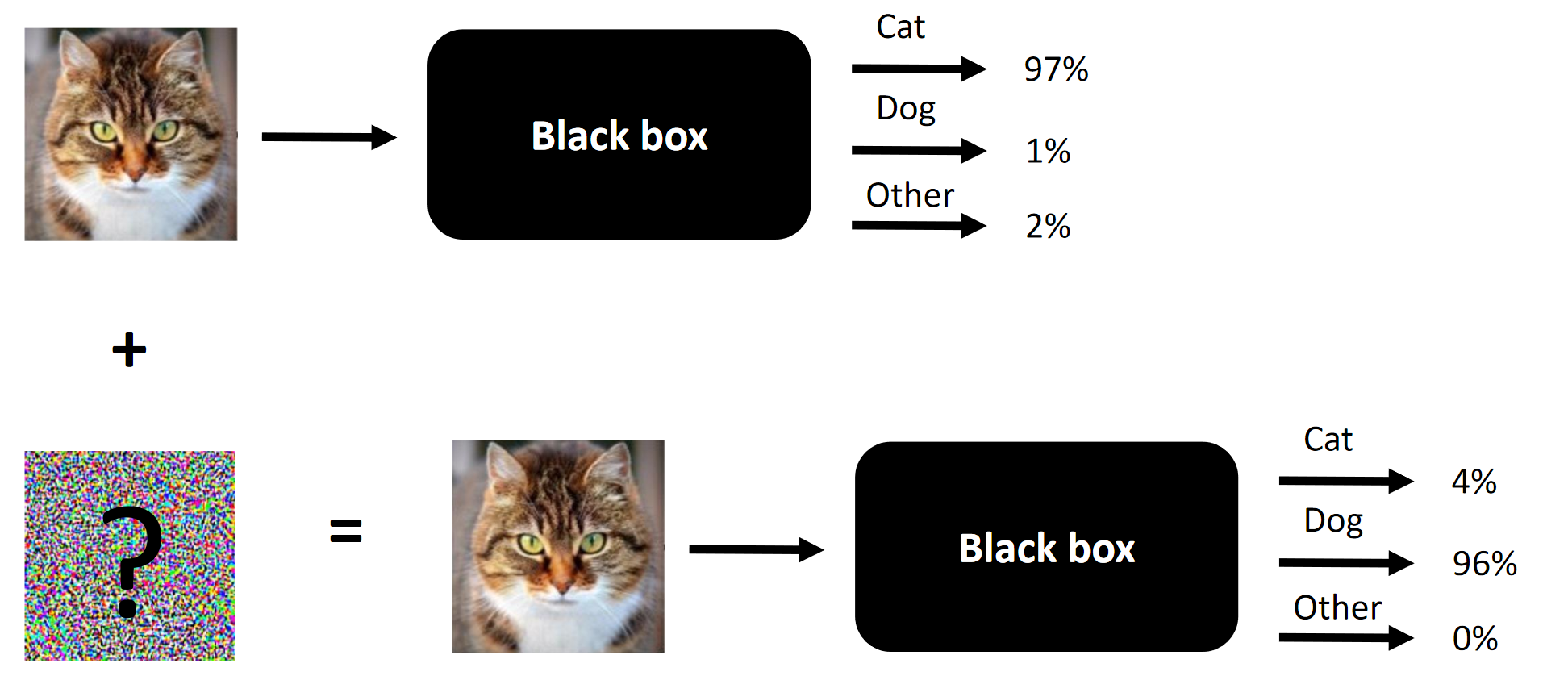 The essence of any competitive attacks in the example.
The essence of any competitive attacks in the example.It so happened that I happened to take part in the Machines Can See 2018 competition. I joined the competition quite late (about a week before the end), but eventually ended up in a team of 4 people, where the contribution of three of us (including me) was necessary to win (remove one component - and we would be an outsider).
The goal of the competition is to change people's faces so that the convolutional neural network provided as a black box by the organizers could not distinguish the source person from the target person. The allowable number of changes was limited to
SSIM .
The original article is posted
here .
Note The clumsy translation of terminology or its absence is dictated by the lack of established terminology in the Russian language. You can offer your options in the comments. The essence of the competition is to change the face at the entrance so that the black box would not be able to distinguish between two faces (at least from the point of view of the L2 / Euclidean distance)
The essence of the competition is to change the face at the entrance so that the black box would not be able to distinguish between two faces (at least from the point of view of the L2 / Euclidean distance)What works in competitive attacks and what worked in our case:
- Fast Gradient Sign Method (FGSM). Adding heuristics made it a LITTLE better;
- Fast Gradient Value Method (FGVM). Adding heuristics made it STRONGLY better;
- Genetic differential evolution (great article about this method) + pixel-by-pixel attacks;
- Ensembles of models (top solution ... 6 "nastenannyh" ResNet34);
- Clever traversal of image-target combinations;
- In fact, early stopping during an FGVM attack;
What did not work in our case:
- Adding the “moment of inertia” to FGVM (although this worked for the team that ranked lower, so is it possible that the ensembles + heuristics worked better than adding a moment?);
- C & W attack (essentially an end-to-end attack aimed at the logites of the white-box model) - works for the white-box (BL), does not work for the black box (PC);
- End-to-end based Siamese LinkNet (architecture similar to UNet, but based on ResNet). Also worked only for the BL;
What we did not try (did not have time, did not have enough effort or were too lazy):
- Sensible testing of augmentations for student learning (it would be necessary to recalculate descriptors too - this is easy, but such a simple idea did not come immediately);
- Augmentation during an attack - for example, “flashing” the pictures from left to right;
About the competition in general:
- Dataset was “too small” (1000 5 + 5 combinations);
- Dataset for learning Student net was relatively large (1 million + images);
- It was presented in the form of a set of precompiled models for Caffe (naturally, at first they gave out bugs on our environments). This also introduced some complexity, since the CS did not accept images by the batches;
- The competition had a great baseline (basic solution), without which, in my opinion, very few people would directly become seriously involved;
Resources:
1. Overview of the competition Machines Can See 2018 and how I got into it
Competition and Approaches
Honestly, I was attracted by a new interesting area, GTX 1080Ti Founders' Edition in prizes, and relatively low competition (which would not compare with 4,000 people in any competition at Kaggle against the whole ODS with 20 GPU per team).
As mentioned above, the purpose of the competition was to deceive the ChY models, so that the latter could not distinguish between two different people (in the sense of the L2-norm / Euclidean distance). Well, since it was a black box, we had to distill the Student-network on the provided data and hope that the gradients of the BL and the BL will be quite similar to the attack.
If you read reviews of articles (for example,
here and
now , although such articles do not really say that they work in practice) and compile what the top teams have achieved, then we can briefly describe these best practices:
- The simplest in the implementation of the attacks suggest a BS or knowledge of the internal structure of the convolutional neural network (or simply the architecture), on which the attack is made;
- Someone in the chat offered to follow the time inference on the CID and try to guess its architecture;
- With access to a fair amount of data, you can emulate a NW well-trained BS
- Presumably, the most advanced methods:
- End-to-end C & W attack (did not work in this case);
- FGSM smart extensions (i.e., moment of inertia + tricky ensembles);
Honestly, we were still confused by the fact that two completely different end-to-end approaches, implemented independently by two different people from the team, stupidly did not work for ChI. In fact, this could mean that in our interpretation of the problem statement somewhere in the data leak was hidden, which we did not notice (or that the hands are crooked). In many modern computer vision tasks, end-to-end solutions (for example, style transfer, deep watershed, image generation, cleaning of noise and artifacts, etc.) are either much better than before, or do not work at all. Meh.
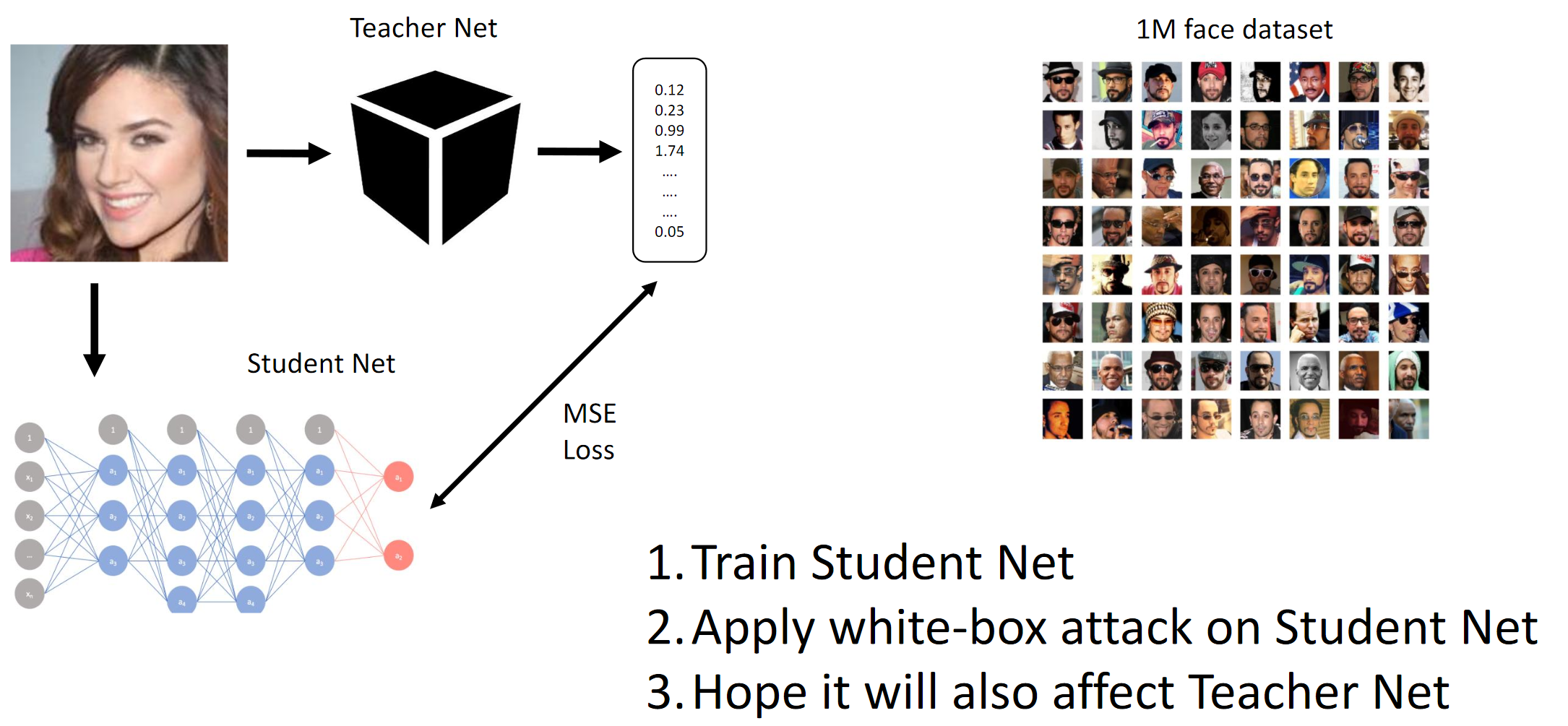 1. Train Student Net. 2. Apply the BJ attack on Student Net. 3. Hope that the attack on Teacher Net will spread tooHow the gradient method works
1. Train Student Net. 2. Apply the BJ attack on Student Net. 3. Hope that the attack on Teacher Net will spread tooHow the gradient method works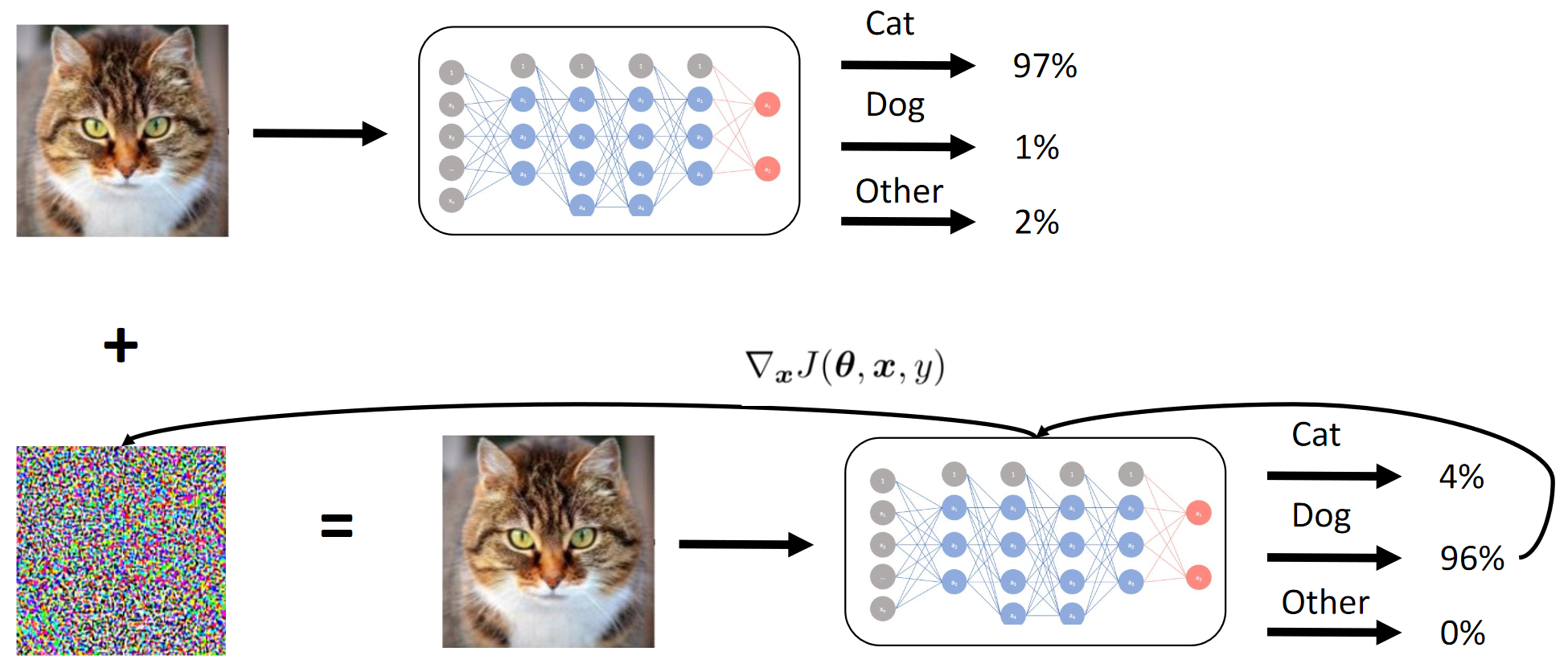
In essence, we seek by distillation that the BJ emulates the cn. Then the gradients of the input images are calculated relative to the model output. The secret, as usual, lies in heuristics.
Target metric
The target metric was the average L2 norm (Euclidean distance) between all 25 combinations of images of sources and targets (5 * 5 = 25).
Due to platform restrictions (CodaLab), it is likely that private scoring was calculated (and the commands were merged) manually, as if this were a story.

Team
I joined the team, after I trained the Student grids, better than everyone else on the leaderboard (as far as I know), and after a bit of discussion with
Atmyre (she helped with a correctly compiled TCH, since she faced the same thing). Then we shared our local speeds with no sharing of approaches and code, and actually 2-3 days before the finish line the following happened:
- My continuous models zafeilis (yes, in this case too);
- I had the best Student models;
- They (teams) had the best heuristic variations for FGVM (their code was based on baseline);
- I just tried out the models with gradients and reached a local score of around 1.1 - initially I was not eager to use baseline from personal preferences (I challenged myself);
- They lacked computing power at the time;
- In the end, we tried our luck and joined forces - I invested my computational capabilities / convolutional neural networks / set of ablation tests. The team has invested their code base, which they polished for a couple of weeks;
Once again, I would like to thank her for her invaluable advice and organizational skills.
Line-up:
github.com/atmyre - based on the actions, was the captain of the team initially. Added a genetic differential evolution attack in the final submission;
github.com/mortido - the best implementation of FGVM attacks with superb heuristics + trained 2 models using baseline code;
github.com/snakers4 - in addition to any tests to reduce the number of options in finding a solution, I trained 3 Student models with the best metrics + provided computing power + helped in the final submission phase and the presentation of results;
github.com/stalkermustang;As a result, we all learned many new things thanks to each other, and I am glad that we have tried our luck in this competition. The absence of at least one contribution of the three would lead to defeat.
2. Distillation Student CNN
I managed to get better speed when training Student models, since I used my own code instead of baseline code.
Key points / what worked:- Selection of a training mode for each architecture individually;
- First practice with Adam + LR decay;
- Careful observation of under- and over-fitting and model capacity;
- Manual setup of training modes. Do not completely trust the automatic schemes: they can work, but if you set the settings well, the time for training can be reduced by 2-3 times. This is especially important in the case of heavy models like DenseNet;
- Heavy architectures showed better results than light ones, not counting VGG;
- Training with L2 Loss instead of MSE also works, but a little worse;
What did not work:- Inception-based architectures (not suitable due to high down-sampling and higher input resolution). Although the team in third place was able to somehow use Inception-v1 and full-rez images (~ 250x250);
- VGG-based architectures (over-fitting);
- "Light" architecture (SqueezeNet / MobileNet - underfitting);
- Image augmentation (without modification of descriptors - although the team from third place somehow pulled it out);
- Working with full-size images;
- Also at the end of the neural networks provided by the competition organizers was the batch-norm layer. This did not help my colleagues, and I used my code, since I didn’t quite understand why this layer was there;
- Using saliency maps with pixel-by-pixel attacks. I guess this is more applicable to full-size images (just compare the 112x112x search_space and 299x299x search_space);
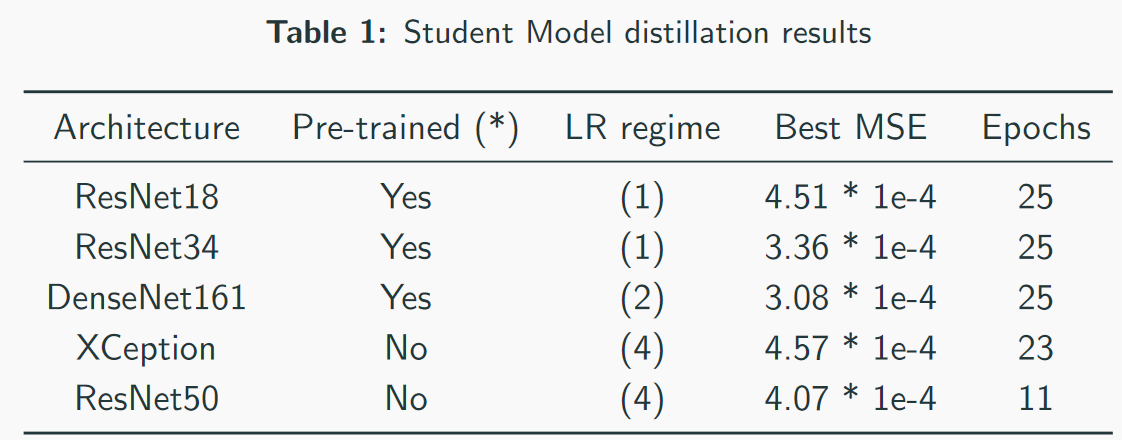 Our best models - note that the best speed is 3 * 1e-4. Judging by the complexity of the models, you can roughly imagine that the PN is ResNet34. In my tests, ResNet50 + proved to be worse than ResNet34.
Our best models - note that the best speed is 3 * 1e-4. Judging by the complexity of the models, you can roughly imagine that the PN is ResNet34. In my tests, ResNet50 + proved to be worse than ResNet34.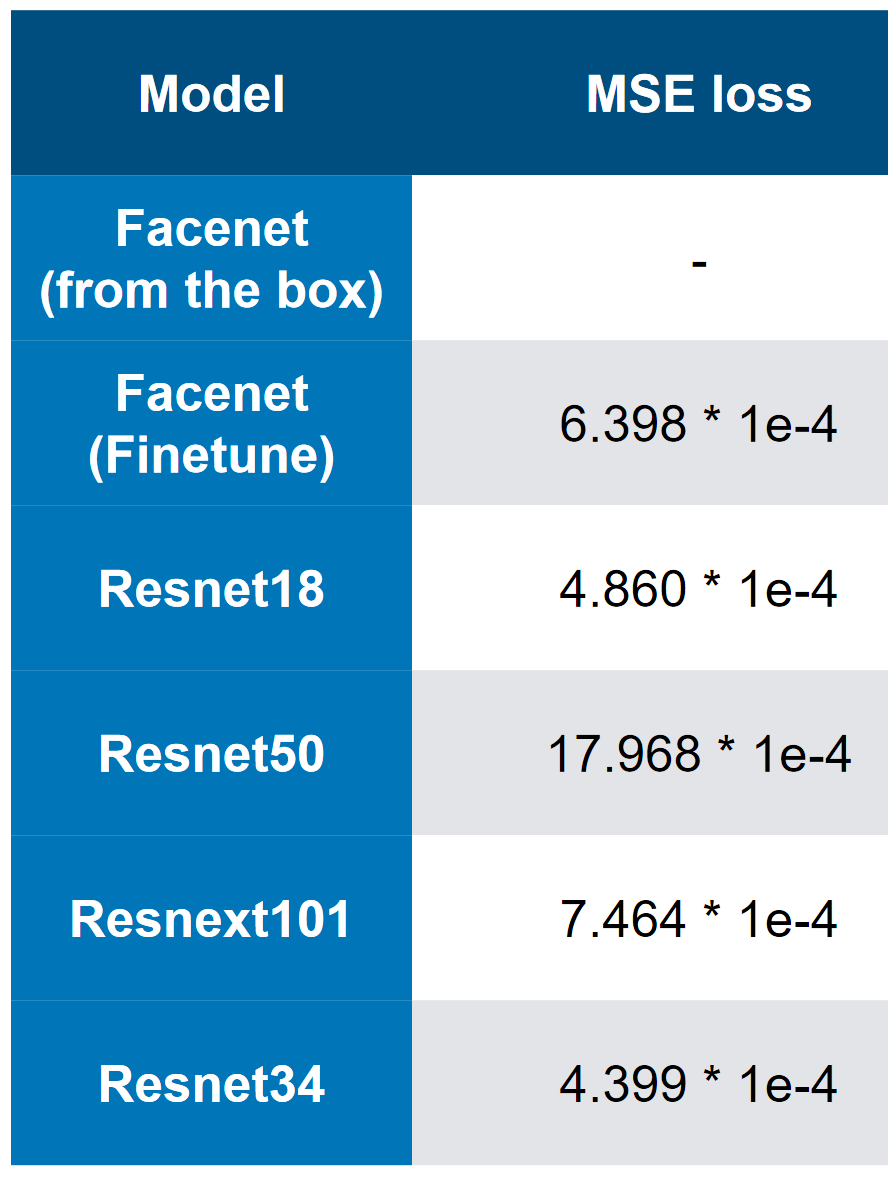 MSE first place loss
MSE first place loss3. Final fast and “ablation” analysis
We collected our fast like this:
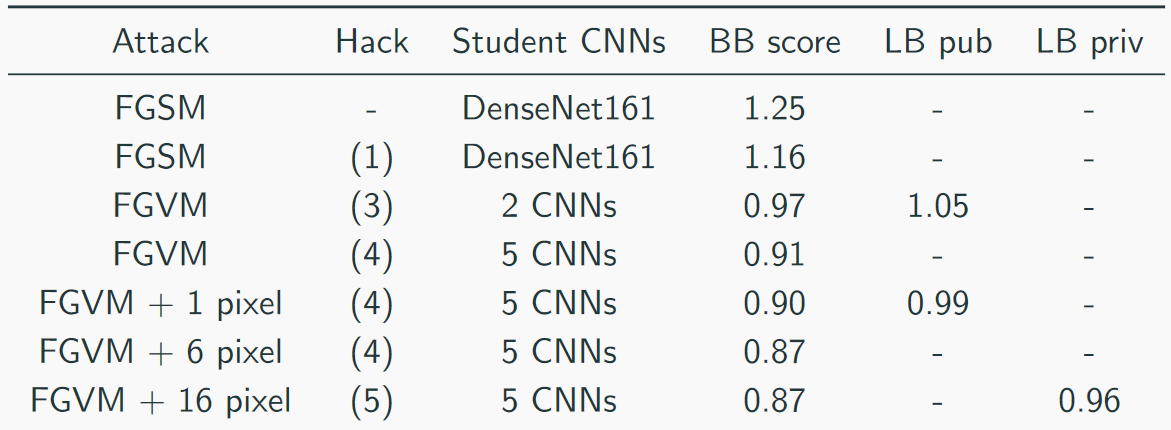
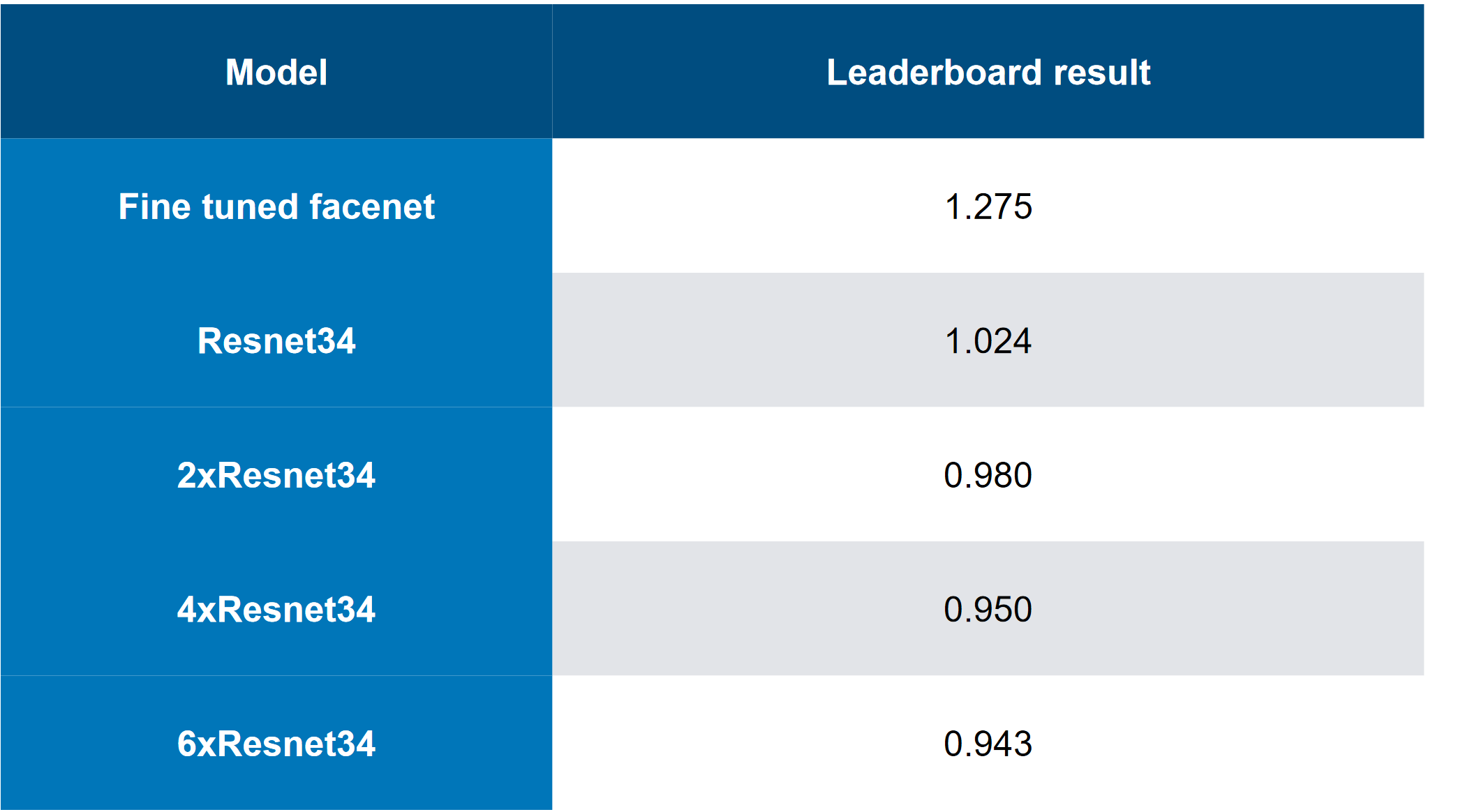
The top solution looked like this (yes, there were jokes on the topic of what just stakes would be, you can guess that the cn is a reznet):
Other useful approaches from other teams:
- Adaptive parameter epsilon;
- Data augmentation;
- Moment of inertia;
- Moment Nesterov ;
- Mirror images;
- To “hack” the data a bit - there were only 1000 unique images and 5000 image combinations => it was possible to generate more data (do not make 5 targets, but 10, because the pictures were repeated);
Useful heuristics for FGVM:
- Noise generation according to the rule: Noise = eps * clamp (grad / grad.std (), -2, 2);
- The ensemble of several CNNs through the weighting of their gradients;
- Save changes only if they reduce the average loss;
- Use a combination of targeting for more sustainable targeting;
- Use only gradients that are higher than mean + std (for FGSM);
Short sammari:
- In the first place was a more "clumsy" solution.
- We had the most “diversified” solution;
- In the third place was the most "elegant" solution;
End-to-end solutions
Even if they failed, they should be tried again in the future on new tasks. See the details in the repository, and in fact we tried the following:
- C & W attack;
- Siamese LinkNet;
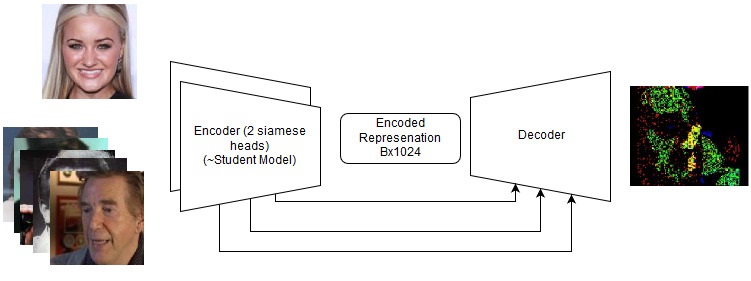 Continuous (end-to-end) model
Continuous (end-to-end) model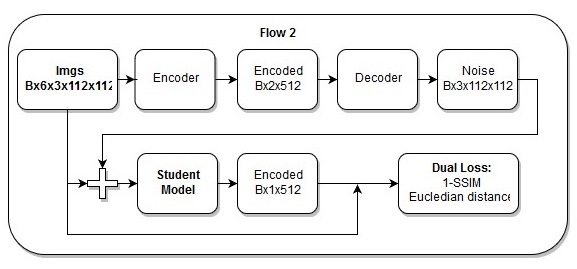 The sequence of actions in the end-to-end model
The sequence of actions in the end-to-end modelI also think my
loss is just perfect.
5. Links and additional reading materials