All with the end of the holidays! ... Some will say that this greeting - so-so. But, for sure, many soon leave, so press some more. Well, we do not give in momentum and on this warm day we share the experience of our partners. It will be about optimizing work with the database. More under the cut!
 I give the word to the author.
I give the word to the author.Greetings to you, readers of Habr! We are the
WaveAccess team, in this article we will share with you the experience of using the Azure Cosmos DB database service (DB) in a commercial project. We will tell you what the database is for, and the nuances that we had to deal with during development.
What is Azure Cosmos DB
Azure Cosmos DB is a commercial globally distributed service database with a multi-model paradigm, provided as a PaaS solution. It is the next generation of Azure DocumentDB.
The database was developed in 2017 at Microsoft with the participation of Dr. Computer Leslie Lamport (winner of the Turing Award 2013 for a fundamental contribution to the theory of distributed systems, the developer of LaTex, the creator of the TLA + specification).
The main characteristics of Azure Cosmos DB are:
- Non-relational database;
- Documents in it are stored as JSON;
- Horizontal scaling with a choice of geographic regions;
- Multi-model data paradigm: key value, document, graph, column family;
- Low latency for 99% of requests: less than 10 ms for read operations and less than 15 ms for (indexed) write operations;
- Designed for high throughput;
- Ensures availability, data consistency, delay at the SLA level of 99.999%;
- Tunable bandwidth;
- Automatic replication (master-slave);
- Automatic data indexing;
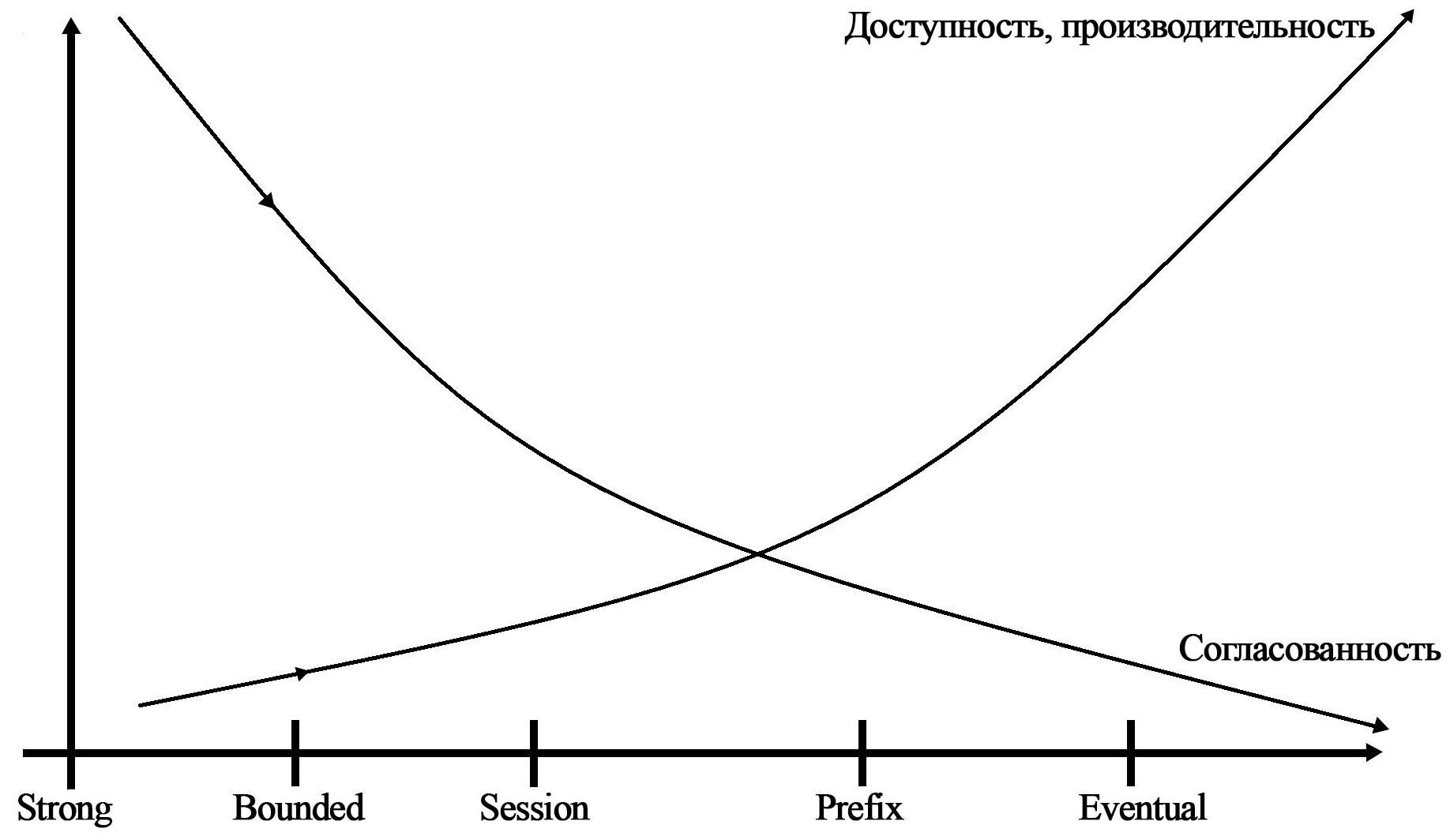
- Customizable levels of data consistency. 5 different levels (Strong, Bounded Staleness, Session, Consistent Prefix, Eventual);
On the graph you can see the dependence of different levels of consistency on the availability, performance and consistency of the data.
- For convenient transition to Cosmos DB from its database, there are many APIs for accessing data: SQL, JavaScript, Gremlin, MongoDB, Cassandra, Azure Blob;
- Customizable firewall;
- Customizable database size.
The task that we solved
Thousands of sensors located throughout the world transmit information (hereinafter, notifications) every few N-seconds. These notifications should be saved in the database, and then they will be searched for and displayed in the system operator’s UI.
Customer requirements:
- Using a stack of Microsoft technologies, including the Azure cloud;
- Bandwidth 100 requests per second;
- Notifications do not have a clear structure and could be further expanded;
- For critical notifications, processing speed is important;
- High system resiliency.
Based on the requirements of the customer, a non-relational, globally distributed, reliable commercial database ideally suited us.

If we look at Cosmos DB-like databases, then we can recall Amazon DynamoDB, Google Cloud Spanner. But Amazon DynamoDB is not globally distributed, and Google Cloud Spanner has less levels of consistency and types of data models (just a table view, relational).
For these reasons, we stopped at the Azure Cosmos DB.
Azure Cosmos DB SDK for .NET was used to interact with the database, since the backend was written on .NET.
The nuances we are facing
1. Database managementIn order to start using the database, first of all you need to choose a tool to manage it. We used Azure Cosmos DB Data Explorer in the Azure portal and
DocumentDbExplorer . There is also an Azure Storage Explorer utility.
 2. Configure DB Collections
2. Configure DB CollectionsIn Cosmos DB, each database consists of collections and documents.
Customizable collection features that you should pay attention to:
- Collection size: fixed or unlimited;
- Bandwidth in units of requests per second RU / s (from 400 RU / s);

- Indexing policy (inclusion or exclusion of documents and paths to and from an index, setting up various types of index, setting up index update modes).
Typical index example
{ "id": "datas", "indexingPolicy": { "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/*", "indexes": [ { "kind": "Range", "dataType": "Number", "precision": -1 }, { "kind": "Hash", "dataType": "String" }, { "kind": "Spatial", "dataType": "Point" } ] } ], "excludedPaths": [] } }
For the search by substring to work, for string fields you need to use a Hash index ("kind": "Hash").
3. Database transactionsTransactions are implemented in the database at the stored procedure level (the execution of the stored procedure is an atomic operation). Stored procedures are written in JavaScript
var helloWorldStoredProc = { id: "helloWorld", body: function () { var context = getContext(); var response = context.getResponse(); response.setBody("Hello, World"); } }
4. DB change channelChange Feed listens to changes in the collection. When changes are made to the collection documents, the database “throws out” the change event to all subscribers of this channel.
We used Change Feed to track collection changes. When creating a channel, you must first create an auxiliary
AUX collection that coordinates the processing of a change channel for several working roles.
5. Database limitations:- Lack of bulk operations (used stored procedures for mass deletion , updating documents);
- No partial update of the document;
- No SKIP operation (pagination complexity). To implement pagination in requests for receiving notifications, we used the RequestContinuation parameters (reference to the last item as a result of the issue) and MaxItemCount (the number of items returned from the database). By default, results are returned in batches (no more than 100 items and no more than 1 MB in each packet). The number of items returned can be increased to 1000 using the MaxItemCount parameter.
6. Processing 429th database errorWhen the collection bandwidth reaches its maximum, the database starts to generate the error “429 Too Many Request”. To process it, you can use the
RetryOptions setting in the SDK, where MaxRetryAttemptsOnThrottledRequests is the number of request attempts and MaxRetryWaitTimeInSeconds is the total time for connection attempts.
7. Forecast of the cost of using the databaseTo predict the cost of using the database, we used the
online calculator RU / s. In the basic plan, one request unit for an item of 1 KB in size corresponds to a simple GET command referring to itself or to the identifier of this element.
findings
Azure Cosmos DB is easy to use, easily and flexibly configured through the Azure portal. Many APIs for accessing data allow you to quickly make the transition to Cosmos DB. No need to involve a database administrator to maintain the database. Financial guarantees SLA, global horizontal scaling make this database very attractive in the market. It is suitable for use in enterprise and global applications that place high demands on resiliency and throughput. We at WaveAccess continue to use Cosmos DB in our projects.
about the author
The
WaveAccess team creates technically sophisticated high-load fault-tolerant software for companies all over the world.
Alexander Azarov , senior vice president of software development at WaveAccess, comments on:
Complex at first glance, the problem can be solved relatively simple methods. It is important not only to learn new tools, but also to perfect the knowledge of familiar technologies.
Company blog