How many sites do you use daily? A couple of social networks, a search engine, several favorite publishers, about 5 working services. Perhaps, it is unlikely that there will be more than 20 sites.

And have you ever thought how many sites on the Internet and what happens to them?
Periodically come across articles with research, built on a sample of different top 1M sites. But I was always wondering whether it is possible to run through all the domains of the Internet without building analytics on a very small sample.
I first asked this question more than a year ago. We started developing a crawler for websites and needed to be tested on large volumes. Having taken the core of the crawler, I first ran through the domains of the RuNet - these are 5.5 million domains, and after that for all 213 million domains (autumn 2017).
Since then, a lot of manpower and resources have been invested in the development, the algorithms have become better, I decided to return to the analysis of the Internet and collect even more data.
The purpose of this collection of information is to obtain a reliable sample, first of all, by working hosts, redirects, server headers and x-powered-by.
Collection method
The application itself is written in Go, using its own implementations for working with dns and http client. As queue redis, bd - mysql.
Initially, there is only a bare domain, such as example.com. The analysis consists of several stages:
- check availability
http://example.com, http://www.example.com, https://example.com, https://www.example.com - if at least it was possible to connect to some variant, then:
- analyze / robots.txt
- check availability /sitemap.xml
Every day about
100 thousand domains appear and are deleted. Obviously, it is almost impossible to make a one-step snapshot of the network status, but you need to do this as quickly as possible.
We deployed an additional cluster of crawler servers, which allowed us to achieve an average speed of
2 thousand domains per second . Thus, verification of
252 million domains took about a day and a half .
Lyrical digressionIn parallel with crawling, the skill “1001 ways to respond to abuses” is being developed. This is just the scourge of any more or less large analysis. It was worth a lot of effort to modify the algorithm so that it did not fall into the same ip in a short period or did not knock on https several times.
Data
The most important figure in network analysis is the number of “live” domains. We call the domain “live” for which IP is resolved and at least one of the versions of www / without_www http / https gives any response code.
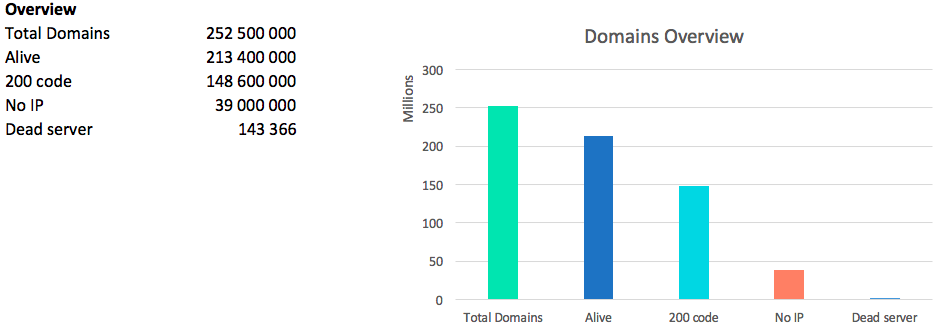
Of course we can not forget about the code 418 - kettles: 2227 pieces.
A total of
13.2 million ip addresses were found. It is worth noting that in some domains several ip addresses are given at once, for others only one, but each time is different.
Thus, the
average temperature in the hospital , on average, there are 16 sites on one IP.
The picture on the status of the codes is as follows:
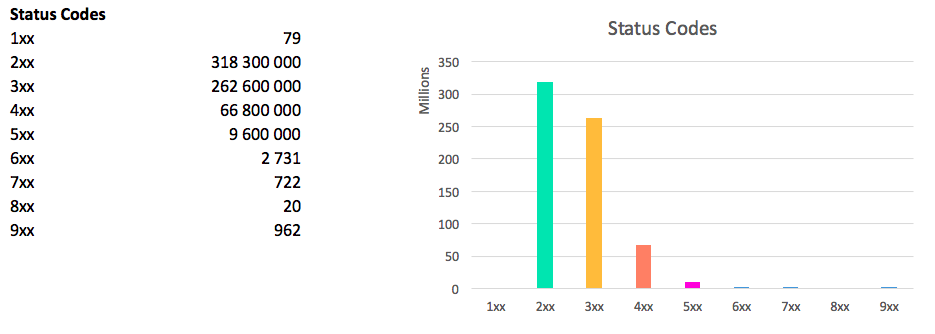
the amount is greater than the total number of domains, because each host can give 4 different status codes (combinations www / non www, http / https)
Https
The transition to https is a trend of recent years. Search engines are actively promoting the introduction of a secure protocol, and Google Chrome will soon begin to mark http sites as unprotected.
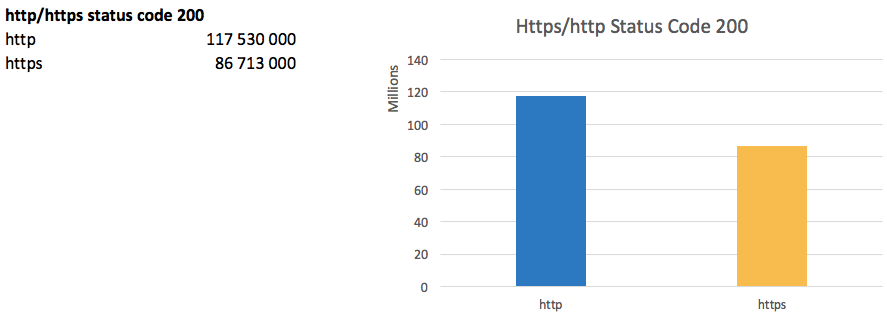
Thus, the share of working sites on https has reached
73% of the number of sites working on http.
The biggest problem of the transition is almost imminent drawdown of traffic, since for http / https search engines even on the same domain are technically different sites. New projects usually start immediately on https.
www or without www?
The www subdomain arose approximately along with the Internet itself, but even now some people do not perceive the address without www.
At the same time, 200 response code for the version
without www gives 118.6 million . domains, and
from www - 119.1 million domains .
At 4.3 million domains, ip is not tied to a version without www, i.e. You will not be logged on to
example.com . At 3 million domains are not tied ip on the www subdomain.
An important point is the presence of redirects between versions. Since if in both cases 200 codes are given, then for a search engine these are two different sites with duplicate content. I want to remind, do not forget to set up the correct redirects.
Redirects from
www-> without www 32 million ,
without www-> www 38 millionLooking at these numbers it is difficult for me to say who won - www or without www.
Redirects
In seo circles, there is a perception that the most effective method of website promotion is putting redirects on it from near-thematic websites.
35.8 million domains redirect to other hosts and if we group them by purpose, we see leaders:

Traditionally, domain registrars and parking lots are in the top.
If you look at the top by the number of less than 10,000 incoming redirects, you can see many familiar sites like booking.com.
And in the top 1000 there are casinos and other entertainment sites.
Server header
Finally we got to the most interesting!
186 million domains give not an empty Header header . This is 87% of all living domains, quite a reliable sample.
If we group just by value, we get:

The leaders are 20 servers, which together have 96%:
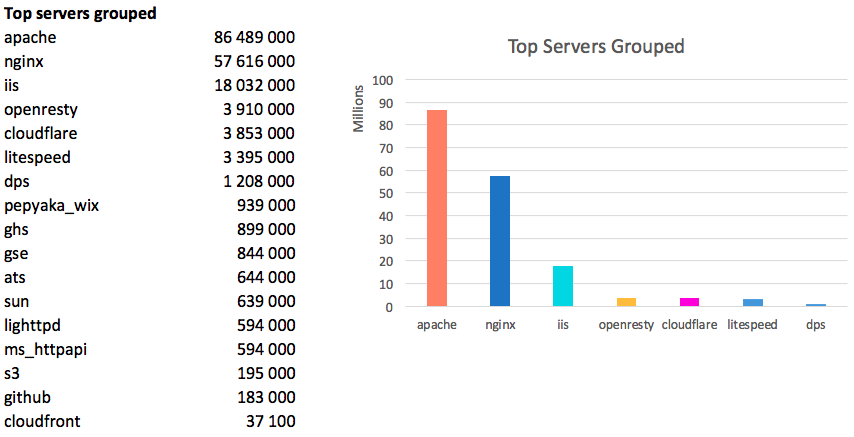
The world leader is Apache, Nginx has silver and closes the IIS trinity. In total, these three servers host
87% of the global Internet.
Conservative countries:

It is noteworthy that in RuNet the picture is different:
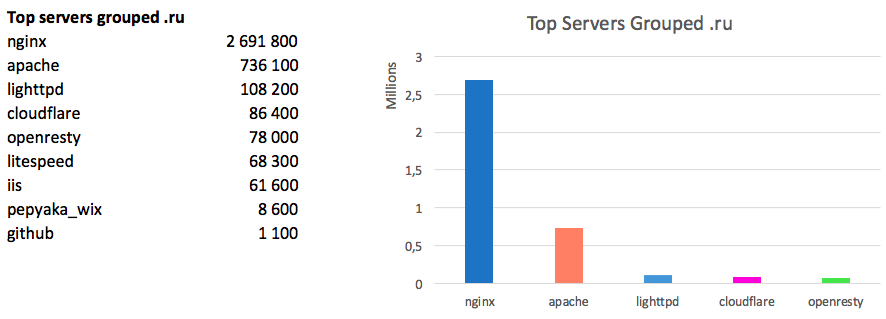
Here the absolute leader is Nginx, apache has a share of three times less.
Where else love Nginx:
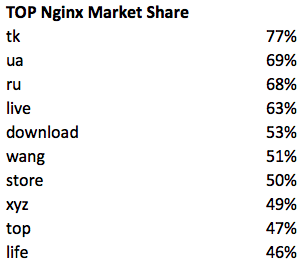
The remaining servers are distributed as follows:

X-Powered-By
Only 57.3 million hosts have the X-Powered-By header, which is approximately 27% of the live domains.
Raw Leaders:
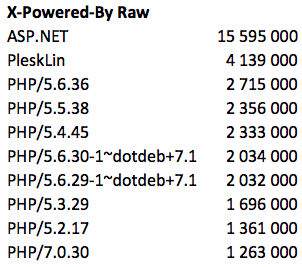
if you process the data and discard the garbage - then php wins:
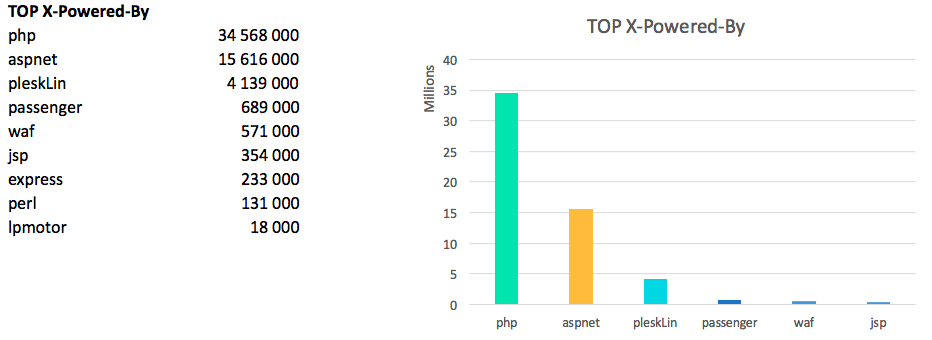
PHP versions:

Personally, I am somewhat surprised by such popularity of 5.6 and at the same time I am glad that the total share of sevens is growing.
There is also one site in Runet that says it works on php / 1.0, but the veracity of this figure is questionable.
Cookies

Conclusion
I showed only a very small part of the information that was found. Digging into this data is like digging in a pile of rubbish to find interesting artifacts.
The topics with the blocking of bots of search engines and analytics services (ahrefs, majestic and others) have not been disclosed. On such a sample, there are quite a few different sattelite grids, no matter how you try to hide footprints, but you can see patterns on thousands of domains.
In the near future, we plan to collect even more data, in particular, by links, words, advertising systems, analyst codes, and much more.
I will be glad to hear your comments and comments.