The NoSQL trend is almost 10 years old, and you can safely draw some conclusions and generalizations. And let's do this, let's talk about the development of NoSQL.
Recall how NoSQL was born. Let's see what is good and what is bad in it, and what has stood the test of time. Let us examine the features that already exist in SQL, and which now appear in the NoSQL DBMS. Highlight the unique values of NoSQL, and look a little bit ahead in what will be on the market tomorrow.
And Konstantin Osipov (
@kostja ) - the developer and architect of the Tarantool DBMS, who in his report on RIT ++ 2017 spoke about the trends of NewSQL, will help us in this, because the architect is supposed to understand what is happening in the database world so that at least to invent a bicycle.
About the speaker : Now Konstantin Osipov is working on Tarantool, but he previously participated in the development of MySQL, and when Konstantin began work on a new database, he was very embarrassed about why it should be done at all, why we need another database. In particular, the attitude towards NoSQL was very skeptical, like the “non-SQL”.
However, development continues, some of the original principles die off, and, at the same time, NoSQL bases take over features from classic SQL. Based on the results of these several years of rapid transformation, it is possible to sum up the intermediate results and allow yourself to make several predictions for the future.
Plan
NoSQL tenets
By the term NoSQL, many are now trying to cling, but initially it became widespread in 2009, when the hashtag
#nosql appeared. A developer from Last.FM has invented this tag for the mitsup about distributed databases.
After that, the tag began to gain popularity on Twitter, and NoSQL became a cistern or funnel for frustration, as I call it - frustration, which has accumulated over many years of working with traditional databases.
NoSQL is a way out for frustration, a tag that everyone who lacked SQL capabilities lacked is a tag.
This frustration needs to be somehow structured and defined, which most often people did not like in traditional DBMS. There are 3 large blocks of tasks, for the solution of which NoSQL was created:
- horizontal scaling;
- new data models;
- new patterns of consistency.
Let's see what these blocks are. Take, for example, Key-value databases. The basic idea of the Key-value data model is that the database is simple, but it is scalable. A huge number of problems falls on the shoulders of the developer, but he has a strict guarantee that his database will be
infinitely scaled . But endless scalability is not magic. Scalability guarantees are achieved due to the
extremely simple semantics of supported operations: in a key-value database, any operation affects exactly one cluster node.
Initially, it was very difficult for the community to separate data models from scaling models. If you look at the same Cassandra, in earlier versions its data model was called Wide Column Store - a wide column database. If the DBMS index is one in the key-value, by key, then in the wide column column column index is always automatically created: by key and by Column Family.
Moreover, the index is keyed on the key, and the index on the Column Family is local to a specific data node. Due to this, we have achieved horizontal scaling, but at the same time were able to perform local queries on the column family. Old-timers remember that a similar feature was implemented in Oracle, with the preservation of the relational model, and was called the joined table. This feature allowed the two tables to specify the physical placement in the joined form. Wide column store in Cassandra - implements the joined table with automatic distribution across the cluster.
Merging the data model and the scaling model is exactly the problem that was solved with the help of the relational model. Welcome to the 70s.
In addition to new data models in NoSQL, new consistency models were implemented. Yes, yes, again this famous
CAP-theorem . I am amused all the time by talking about the CAP theorem - to whom did it come in handy at all? As there is no second freshness sturgeon, so there are no other answers to the question about the consistency of data except one:
the database must guarantee this consistency . Therefore, new models of consistency are also, in my opinion, a dying trend.
NoSQL today
The thesis that I want to make in the first place is that of the whole NoSQL movement survived:
- horizontal scaling;
new data models document and graph data models;new patterns of consistency.
Of the theses about the new data models, the one and a half survived and the thesis about the consistency models completely died.
Death cap
Why some models of consistency did not survive?
●
Eventual consistency: term inflationWho uses the database, which has a working vector clock, and the business logic of the application is designed for this? - no one. Who uses databases with CRDT (conflict-free replicated data types)? Who uses Riak? - no one. What do people use? More often PostgreSQL, less often by other databases, for example, MongoDB.
●
MongoDB: atomic changes to isolated, transactions are added in 3.xxThis database has asynchronous replication. This is a very simple thing to understand, although, in fact,
there are 4 types of asynchronous replication . Transactional data replication can occur after the transaction has committed itself locally; before the transaction is committed locally.
That is, the commit point to the main base can be correlated with the commit point in the replica also in different ways.
An entry to the local log has already been made, but it has not flown to the cue yet. Suppose you want to wait for her to at least fly away for a cue. Flew away - does not mean flew. Arrived - it does not mean that it is recorded in the local log on the replica.
Initially, MongoDB had a mode: the request arrives at the server, the database responded OK - it has not even got to the disk, nor to the log - anywhere at all, and flew further. Due to this, everything works very quickly, but then MongoDB was criticized for it, and by default in later releases of 3+, it still began to write a transaction in the log, and only after that send a confirmation to the client.
That is, even asynchronous replication is the abyss of semantic models. Therefore,
consistency models are too complicated to be understood by a wide range of developers, and transactions and synchronous replication replace the assortment of exotic models .
Against the background of the death of the consistency model, there is still an interesting trend in the development of actually more strict consistency. There are transactions in Redis, although I would not call it a transaction, but at the expense of what a real transaction is, and without that, there are disputes.
Let's look at the history of the emergence of transactions in NoSQL. At first, document level atomicity was implemented in MongoDB. Then, isolated execution mode was added to allow developers, if they really want to update several documents atomically.
●
Redis transactionsAt the dawn of NoSQL, the developer is offered to put the entire business case in one basket document. An integer flow appears, called domain-driven design, which elevates this perversion to the rank of a design pattern. Indeed, if everything is stored in one document, atomicity is achieved simply: you have done one transaction, one business process and you have one atomic change of one document.
But it turns out it does not work. Data needs to be normalized to avoid redundant storage. They need to be normalized for analytical queries. In the end, the data model is evolving - and the document that yesterday could save all the information necessary for a business scenario today needs to be expanded and supplemented.
Atomicity problems demonstrate? how closely the data models are related to the consistency models — the emergence of transactions and synchronous replication makes most models in NoSQL unnecessary.
Data models
Now let's talk about the following story - a story with data models.
Data model groups that are invented after SQL:
- Key Value;
- Documentary;
- Wide Column store;
- Data structure server (Redis);
- Graph database.
Cool! We have so many data models! And how well do they scale?
This is a kind of thesis, related primarily to the so-called hyperconvergence, when all modern projects use cheap single-unit servers, and businesses stop buying vertically scalable machines.
Hyper-convergence has come into our lives so thoroughly that today even inside vertically scalable machines, if they exist, horizontally scalable software already sits - see how PureStorage works or, if you don’t remember, remember Nutanix. People are sold, of course, cabinets, but these cabinets inside are arranged like ordinary racks at the hosting provider.
That is, horizontal scaling is a trend that puts pressure on everyone, including the inventors of new data models. So which data models are good for horizontal scaling, and which are bad?
SQL - is it good or bad for scaling out? The answer is, in fact, quite controversial, we will return to it later.
Redis
When Redis added the Redis cluster, it turned out that not all data model operations normally horizontally scale.

This is a quote from the documentation, where they write that they have something working on a particular shard, but something really works like in a real cluster.
The fundamental problem of this approach is the same as in MySQL, which we took and shook hands. That is, the developer has two data models:
- In one, he thinks in relational algebra.
- Then, when he thinks about independent sharding, he thinks in the data model of shardirovannaya relational algebra.
A good data model should be universal . What is beautiful is relational algebra - the result of the projection is a relation, the result of any operator is a relation. And as soon as we manually start sharding MySQL on a cluster, we lose it.
However, Redis adds a Redis cluster, because
everyone wants to scale horizontally .
Graph database
Graph databases are a good example that helps to
separate the concepts of horizontal scaling of calculations and storage . Information can always be divided by any number of nodes. But if the database is by its nature designed to process the data it stores, and these calculations do not scale horizontally, then there is the problem of efficient horizontal storage, allowing the calculations to work.
Let's look at the problem of scaling graph DBMS - SQL DBMS encounter very similar obstacles when scaling.
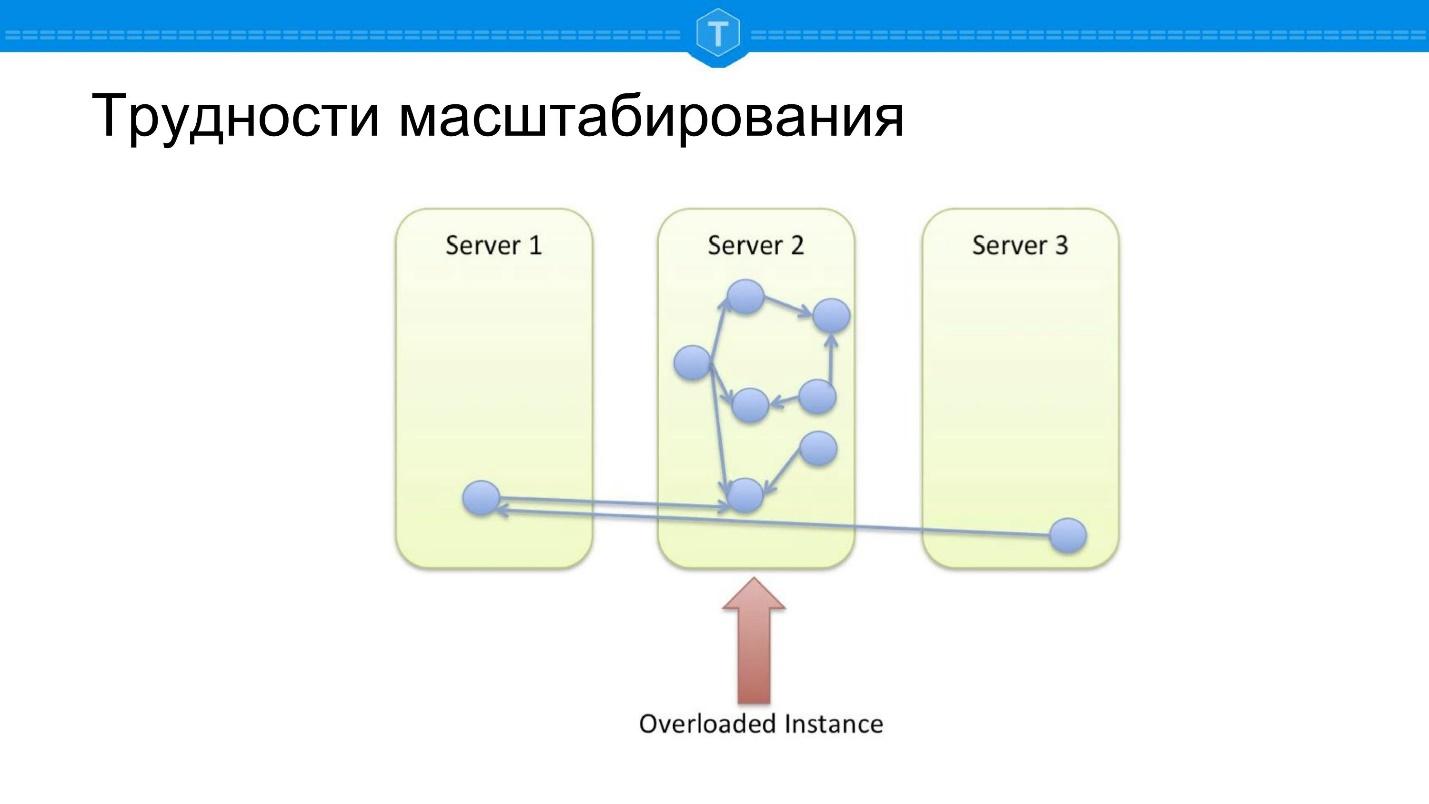
Take the local database in which the graph is stored. Sooner or later, one node is filled, and we begin to use other nodes. As soon as we use more than one node, the central node becomes overloaded, as the locality of requests is lost. Some queries on the graph are forced to go on several physical nodes, that is, there are network delays.
Suppose we did a little differently - we took and broke everything up with a good sharding function. We compute a hash that randomly smears all the data across our cluster, and we get another problem.

If in the previous scheme at least some queries worked normally, then
100% of queries are stupid , because most database queries are connected with graph
traversal . Any detour from a node must go somewhere, and most often, in order to compute a query, you need to go to another node.

The idea arises of sharding approximately, as shown in the diagram above: to find clusters and place them on their nodes: tightly coupled subsets are placed together, loosely coupled subsets are posted.
This is a kind of ideal option, but the
ideal option exists only in theory . Live data is not amenable to static partitioning. To implement this approach, we must automatically detect clusters on a dynamically changing set, constantly moving nodes depending on appearing and disappearing links.
Therefore, Neo4j is by and large scaled now as classic SQL databases. They have been working on sharding for quite some time, trying to solve the problems described.
The thesis that I put forward is that
horizontal scaling puts
pressure on everyone , and all data models will sooner or later be forced to implement it. But some models will remain with us, but some will not.
So, for example, if we consider the Key-Value and Document base in its pure form, then my statement is that they will not be. If you look at graph databases, they already occupy a significant segment, but are under pressure from horizontal scaling.
Will the graph databases disappear? More likely,
graphs, like documents, will be included in all products . This trend is called multi-model databases, and later in the report I will give an example of how this can work in practice. But for now, as another illustration of the trend of multi-model databases, let's look at JSON.
Json
Below is an example of how a trend works, which becomes all-encompassing.
I argue that any database that is at least somehow capable of supporting JSON will support JSON.
It is possible that some databases for matrix calculations will not support JSON. But most likely, and there it is useful. And all the rest will be.
| Mysql
| PostgreSQL
| Redis
| Couchbase
| Cassandra
| Neo4J
|
JSON storage
| Yes
| Yes
| Yes
| Yes
| Yes
| Yes!
|
JSON field ops
| Yes
| Yes
| Yes
| Yes
| No
| No
|
Json query
| Yes
| Yes
| No
| Yes
| Yes
| No
|
JSON secondary index
| Yes
| Yes
| No
| Yes
| No
| No
|
This table allows you to visually see what is happening with data models. Relational bases in their support for JSON are even ahead of non-relational, the same Cassandra. It does not have secondary keys for JSON fields. And even graph databases also begin to incorporate JSON, because
everyone needs JSON .
Thus, multi-model databases, and in particular JSON as a data type, which is present in almost all products, is what will remain of NoSQL seriously and for a long time.
But if all databases support JSON, why do we need NoSQL databases at all?Only one story remains - horizontal scaling. We want to scale horizontally, and only therefore use something other than MySQL or PostgreSQL.

This is Thomas Olin's keynote, VP MySQL Engineering in Oracle, which tells about the future of MySQL. The same happens in the Postgres community and other relational products. Horizontal scaling pressure affects 100% of products due to the transition to hyperconvergence and cloud computing.
Thomas says their vision is one product with high availability and scaling out of the box. This is about high availability, first of all it is InnoDB Cluster, this is group replication + InnoDB. Such a database never dies, even with a hammer.
Further Thomas writes “
scaling features baked in ” - “we baked all these possibilities”. The point is that through x releases (I think that x = 2, 3) they will receive MySQL Cluster in its pure form, which will support SQL on the cluster, JSON storage in the cluster.
Already today
MySQL has X protocol, which is very similar to MongoDB and is designed to work with JSON.
SQL to NoSQL
Now let's look at the movement from the other side. In order to ascertain death, one must look not only at how SQL adopts the principles of NoSQL, but also vice versa.
| MongoDB
| Couchbase
| Cassandra
| Redis
|
Data schema
| Yes *
| No
| Yes
| No
|
NULLs / Absent values
| Yes *
| Yes
| Yes
| No
|
JOINs
| Yes
| Yes
| No
| No
|
Secondary keys
| Yes *
| Yes
| Yes, but ...
| No
|
GROUP BY
| Yes *
| Yes
| No
| No
|
JDBC / ODBC
| No
| Yes
| No
| No
|
There are actually interesting insights here too. I took, in my opinion, the leaders. I agree that there is not everything here, for example, Elastic is also the leader of NoSQL. But Elastic is still primarily a solution for full-text search, so I did not include it in the table.
Times Series Databases as a trend, I do not touch at all. There is a thesis among the times series of the movement that it is a separate niche, similarly to graph bases, but if you dig deeper, Postgres sits under the hood.
Couchbase
Most, in my opinion, Couchbase has a wide range of possibilities from the SQL world. Everyone knows that
Couchbase is Memcached . Dormando (
Alan Kasindorf ), one of Memcached's developers, had a completely different product vision that did not imply horizontal scaling. Therefore Memcache was forked so that it could scale horizontally. It went well and started doing business around it, then merged with CouchDB and so on and so forth.
Couchbase initially says to themselves that they are a
schemaless database . Memcache initially is a very simple Key-value. And now let's see how this self-identification changes over time.
For example, in Couchbase there are Secondary keys, and
Secondary keys - this is actually the beginning of the scheme . If you say that you have any fields on which you build an index, it means that you already say something about the scheme of these documents that you keep.
Moreover, as Couchbase gradually gradually cuts the past out of the documentation about Memcache, the story about eventual consistency will also be cut tomorrow, although today there are still a lot of stories about the lack of read consistency - the secondary keys are eventually consistent.
But the joke is that Couchbase has JDBC / ODBC. These are the drivers with which you can theoretically connect Tableau or ClickView - theoretically, because the CQL syntax is not compatible with SQL. But these
drivers themselves are part of the SQL standard.Looking ahead, let's look at the syntax.

With the syntax, they screwed up big, because for some reason they decided that since they have stored documents, but there is no schema, they need some special operators - and they invented complete analogs of what is already in SQL.
For example, they have IS MISSING - why is it necessary if the standard is IS NULL?
Why is the presence of JDBC, ODBC, and a special syntax for standard SQL capabilities already the death of the patient? Because 30-40 years ago, when the SQL standard was not dominant in the SQL database world, as it is today, everyone behaved exactly the same way: everyone tried to make the look-in vendor, everyone thought that the invention would be sufficient for customers own jargon, etc.
We know how it ended.
One leader, relatively speaking, holds the industry in his fist.Therefore, the fact that Couchbase adds JDBC / ODBC is basically Frankenstein. But I want to talk more about the other, namely about the secondary keys.
Secondary keys
I said that the main NoSQL covenant is horizontal scalability, the only exception is the graph base, which has a separate niche. But again, there is OrientDB, which, as we found out, scales horizontally well.
SQL databases do not fundamentally differ, apart from working with a schema (more strict typing, more strict data schemas), from NoSQL, except for horizontal scaling.
Now secondary keys appear in the NoSQL databases. How are secondary keys horizontally scaled?
There are two major ways of implementing secondary keys in a cluster (all the rest are options or an esoteric):
- Or, for each subset that is on a particular node, a local secondary key is built . But then this local secondary key can only be used for queries on this subset, primarily range queries, and SQL is basically just such queries. With this approach, a range request for which it is not possible to determine a specific cluster node to execute is forced to launch map / reduce for the entire cluster.
- Or secondary keys are carried out to the outside . That is, there is a separate index notes, which stores secondary keys. Then everything works much better from the point of view of analytics, namely, range-requests, etc., but the locality of updates is immediately lost.
That is, any change should potentially go to the data node, put a new value there, see what data has changed, go to nodes with indexes, update them. If there are many secondary keys, then there are many updates to index nodes.
Betrayal happens before our eyes . On the one hand, NoSQL-databases give us dialects instead of SQL, on the other hand, they betray the goal of infinite horizontal scaling, because they add secondary keys.
In this regard, I have a question: have you looked at CockroachDB with interest? The idea is this:
if we are still going to reinvent the wheel, let's invent it at least from scratch . It's clear why MySQL is crawling so slowly and confidently to the sharding cluster - because it has a lot of legacy. These are millions of lines of code, millions of applications, a complex development process, etc.
As a result, we get that the NoSQL movement is now burdened with the same legacy over the 10 years of its existence. Yes, it is less there, but it is still a lot. It is easier to take and write a SQL database from scratch than to finish PostgreSQL, relatively speaking, from MySQL or from Couchbase so that it is True NewSQL.
There is another interesting story besides secondary keys. MongoDB has no SQL, they have their own query language. By the way, in fact they have JOINs, there is an error in the nameplate, or an attentiveness check.
Redis has No everywhere, because he is a hostage of his data model. If Redis implements all this functionality, it will lose its main value - it will no longer be easy. We see products that have become hostages of their original simplicity, and they will fall off, quietly go into oblivion.
I'm not saying that Redis will go into oblivion - it is possible that there guys will come up with something. Now they have come up with modules, and there are already Redis modules that implement SQL. But as far as I understand, it just fastens to Redis SQLite, but this is not cool - storage is different there - not Redis, not in memory.
If NoSQL as a whole is dead, then what good did it bring to the history of the development of the DBMS, what will stay with us for a long time?
Data schemas
Let's take a look at how NoSQL solutions support data schema management. In my opinion, this is very important, and this is exactly why else SQL databases scale horizontally badly. This is a very big piece of problem with a SQL database.
The principle of schemaless generally appeared because there was frustration associated with the fact that we left waterfall in software design: we have a constant agile, we constantly make changes to the requirements and because of this the data scheme is constantly changing. It is simply impossible to do when your database is designed for what you did CREATE TABLE, and this is for centuries.
There is even a feature called online alter table. And in Oracle there is a versioning of the data schema, when each application can work with its version of the data schema.
But in general, the SQL approach to versioning the data schema is rather harsh, in my opinion.
In this sense, the MongoDB document model and approach is a trend approach, and this will remain with us .
MongoDB was initially also declared as schemaless. But then they had the opportunity to validate the data. You can define a validator, the main feature of which is that it does not have to be strict. Configure the validation level and validation action. Validation level allows you to decide what to do with existing documents and what to do with new documents.
You can configure the validator so that it does not reject these existing documents, and operations with them still take place. But new documents are already required to pass and comply with this validation, this data scheme, which you are submitting. Accordingly, validation action can also be either reject or warn: you get a warning that the data does not pass a validation action.
Thus,
you can develop your data scheme in parallel with the development of applications . Unfortunately, besides MongoDB (we also have it in Tarantool), nobody has that.
Cassandra has support for the data schema and can accommodate JSON, but there is no versioning and configuration. They went the other way - if the data scheme is defined, it must be strict. This, in my opinion, is also a trend from NoSQL, which will remain with us.
Consistency
Let's see all the same, why NoSQL databases generally add SQL in one form or another.

The eventually eventually analysts model is such that you get a report that does not correspond to any point in time, because it is a
running report . While he is scanning the data, he is not holding any locks - the data mutates parallel to the scan. This is a rough analytics.
Why, however, does such a need arise?
Because there is a world of analytics, which is now very overheated, solutions cost millions of dollars. If you exclude BigQuery and look at analytics solutions like Vertica, for example, they cost millions of dollars.
For NoSQL, this is a real opportunity to make some extra money. But it turns out that the results of any SELECT query cannot be used in LTP, that is, the LTP still has to have a Key-value.
That is why I argue that in the future NoSQL-systems will tighten the nuts and implement strict consistency for their queries.
Now SELECT and JOIN queries are implemented exclusively for analytics, but then they will understand that they need to move on, and
will implement a strict consistency model — implement transactions, etc.
NoSQL: looking for values
So, I have already mentioned the
documents that will be included in all products, we talked about alternatives to managing the scheme. I would also like to mention
domain-specific languages .
NoSQL movement spawned a whole galaxy of DSL. The most remarkable of them is
RethinkDB ReQL . He was the most advanced, his developers said - let's embed the language for working with data in each domen specific language. It is natively embedded in Python, in JavaScript, etc. - do not have to work with two languages. This is very different from SQL in general, when there is relational algebra and you can work only with its results.
But we have not only ReQL, as such. ReQL demonstrates that this is not enough to organize your niche - this is not enough value in and of itself. RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
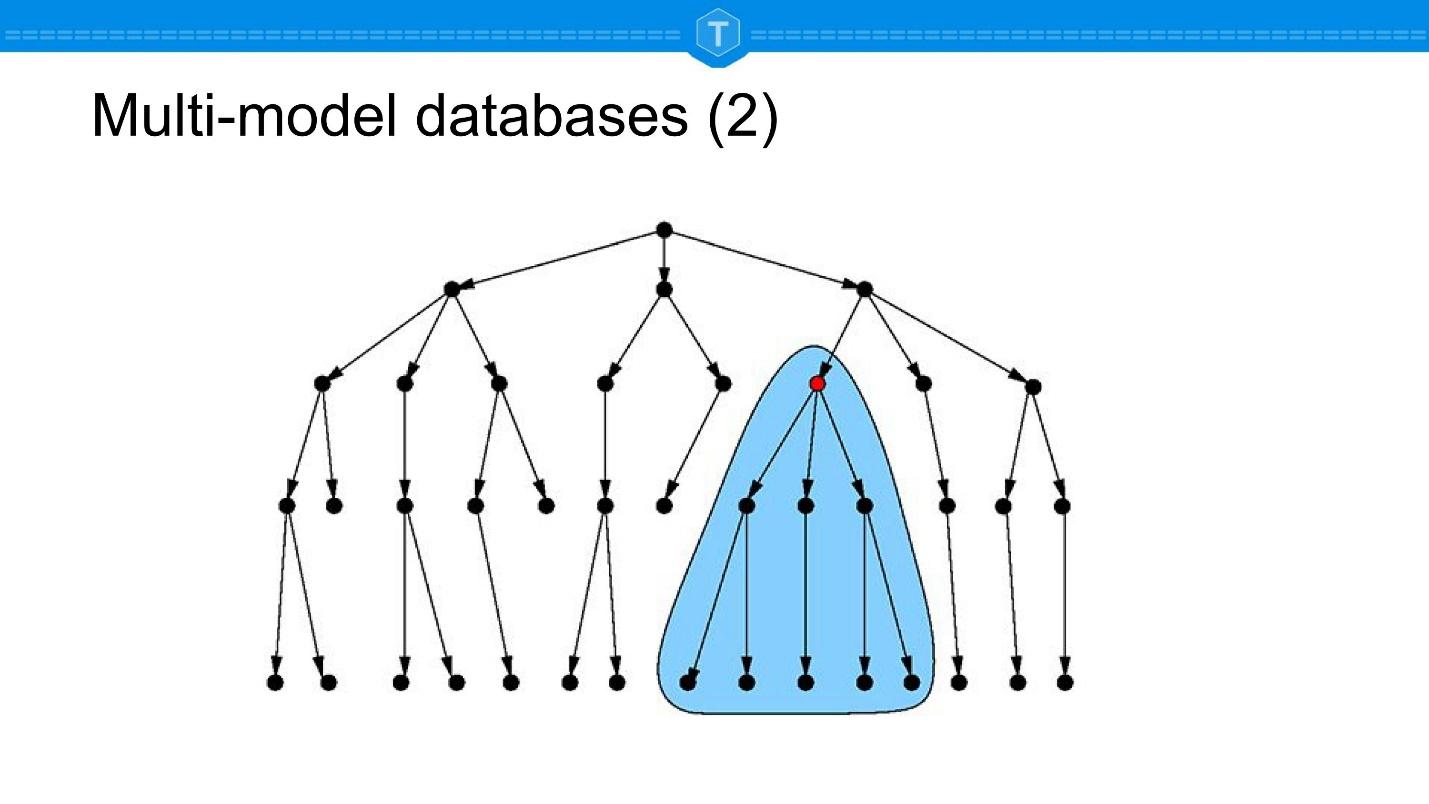
, , . , , , , . .
. , , relations. , relation , , relations ..
UPSERT:
NoSQL, , —
write optimized storage — , , , .
SQL, NoSQL , write only . absert, MongoDB, . Insert , , ID , , ID .
— , .
, . — , , . , . , , - .
, .
, , write optimized , , . write optimized storage LSM (RocksDB, LevelDB )
2 , . Instead of 10 thousand requests per second, there may be a million on one node.That is why now the Time Series Database wins, because they lack this semantic gap. The incoming data stream in them is clearly defined as a time series and is recorded very quickly and compactly into the database, in particular. because you don’t need to verify uniqueness. This is an order of magnitude faster simply because in traditional databases there is no such semantic operation that would be write only.I think it will appear. Where does all this go next? If you look very far, innovation does not stop at NoSQL and NewSQL. Our understanding of information is constantly evolving.
Where does all this go next? If you look very far, innovation does not stop at NoSQL and NewSQL. Our understanding of information is constantly evolving.One of the most important trends of the future, in my opinion, is that we will delete information less and less.
, .
NewSQL: temporal database
Microsoft SQL Server. , : SELECT , SELECT - .

. -, - . -, , . — : — .
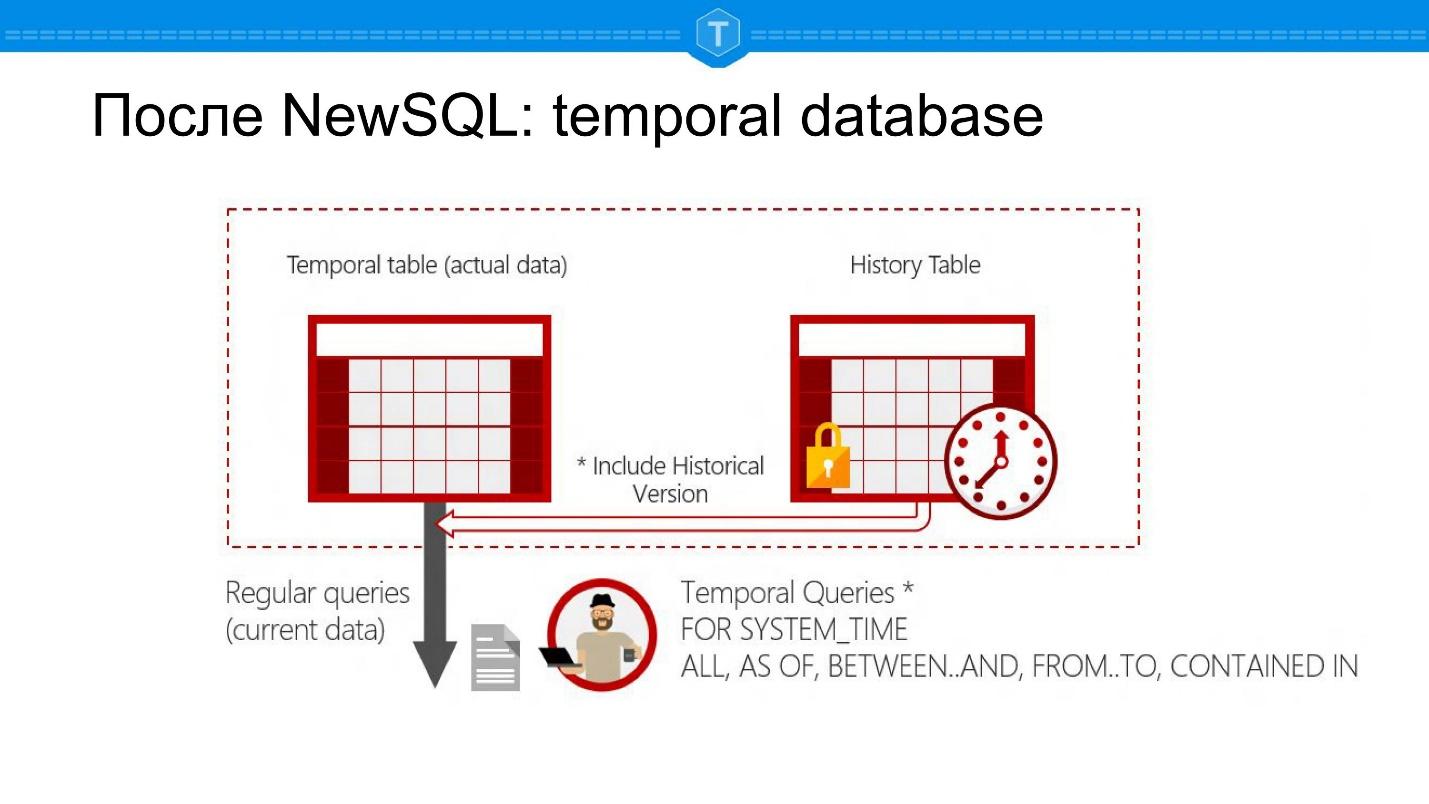
, . , . , , , :
- ,
- .
, .
, 17 , 20 — .
, . Why do I think so? Eventual consistency, .
, — !
useful links
Questions and Answers— , MySQL, PostgreSQL, MongoDB ..?
-, : databases, ? , . , , , CockroachDB , .
. , — . - . , , , .
— , : SQL , SQL , . — . , , , ?
, — ! , , ! — , .
— , Elastic ? , — time series , . , .
Elastic , Elastic . - — , .
, , Elastic . , Elastic time series, . Elastic , ..
— , . , , . .
, Elastic . , Couchbase, , — , - .
news
, 21 Tarantool Conference — T+ Conf — Tarantool, in-memory computing.
- , Vinyl, , , , .
- , , Tarantool — , , .
- — , , IoT .