The first live broadcasts from the scene appeared in Russia almost 70 years ago and led them from a mobile television station (PTS), which externally resembled a “trolleybus” and allowed to broadcast not from the studio. And only three years ago, Periscope allowed to use a mobile phone instead of a “trolleybus”.
But this application had a number of problems associated, for example, with delays on the air, with the inability to watch broadcasts in high quality, etc.
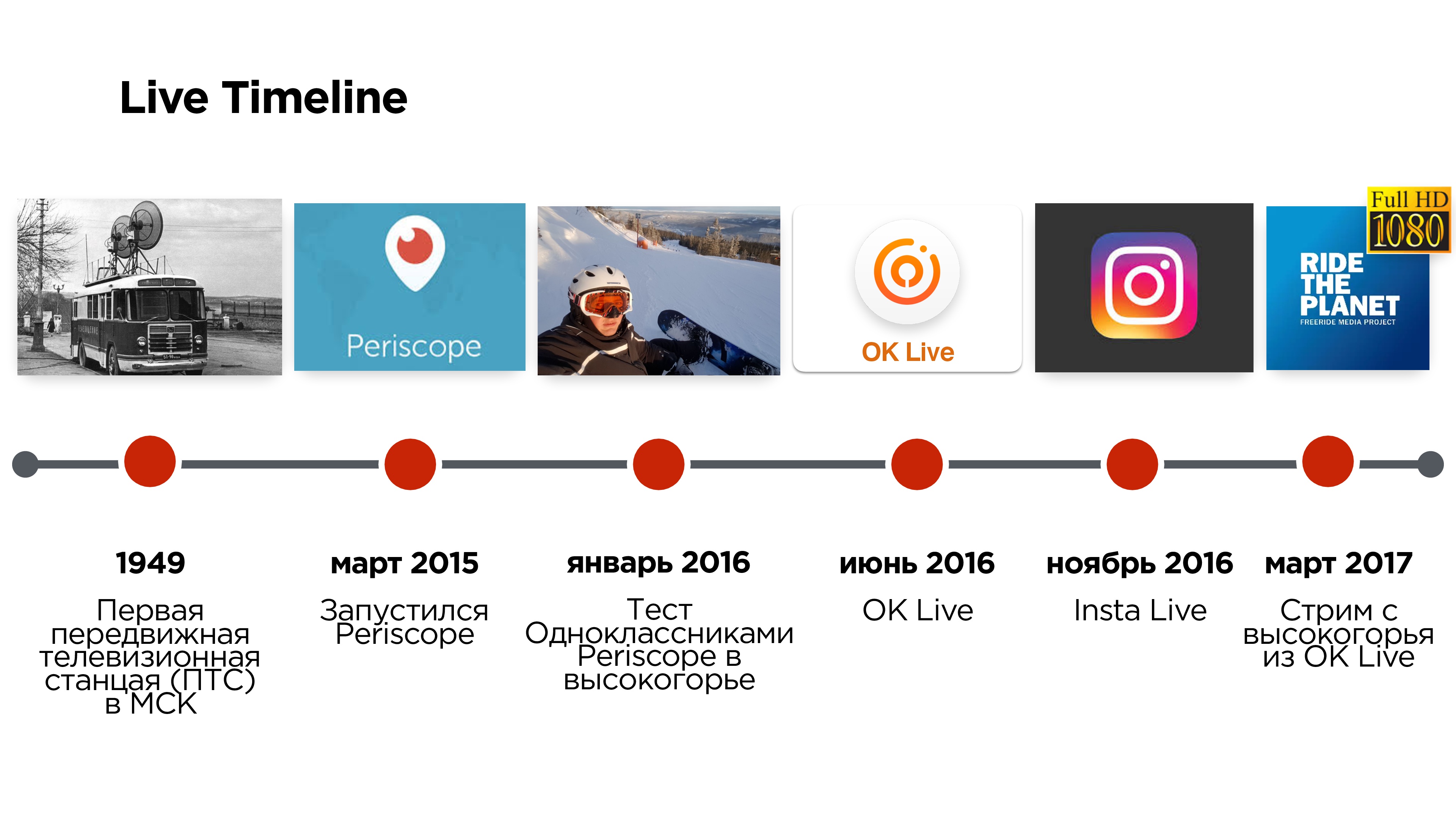
Six months later, in the summer of 2016, Odnoklassniki launched their OK Live mobile streaming app, in which they tried to solve these problems.
Alexander Tobol is responsible for the technical part of the video in Odnoklassniki and on Highload ++ 2017 talked about how to write your UDP protocol, and why this may be required.
From decoding his report, you will learn everything about other video streaming protocols, what are the nuances, and what tricks are sometimes required.
They say that we should always start with architecture and TK - supposedly it is impossible without it! So do.
Architecture and TK
On the slide below, there is an architecture diagram of any streaming service: the
video is input, converted and transmitted to output . To this architecture, we have added a few more requirements: the video should be fed from desktops and mobile phones, and the output - to get on the same desktops, mobile phones, smartTV, Chromcast, AppleTV and other devices - everything you can play video on.
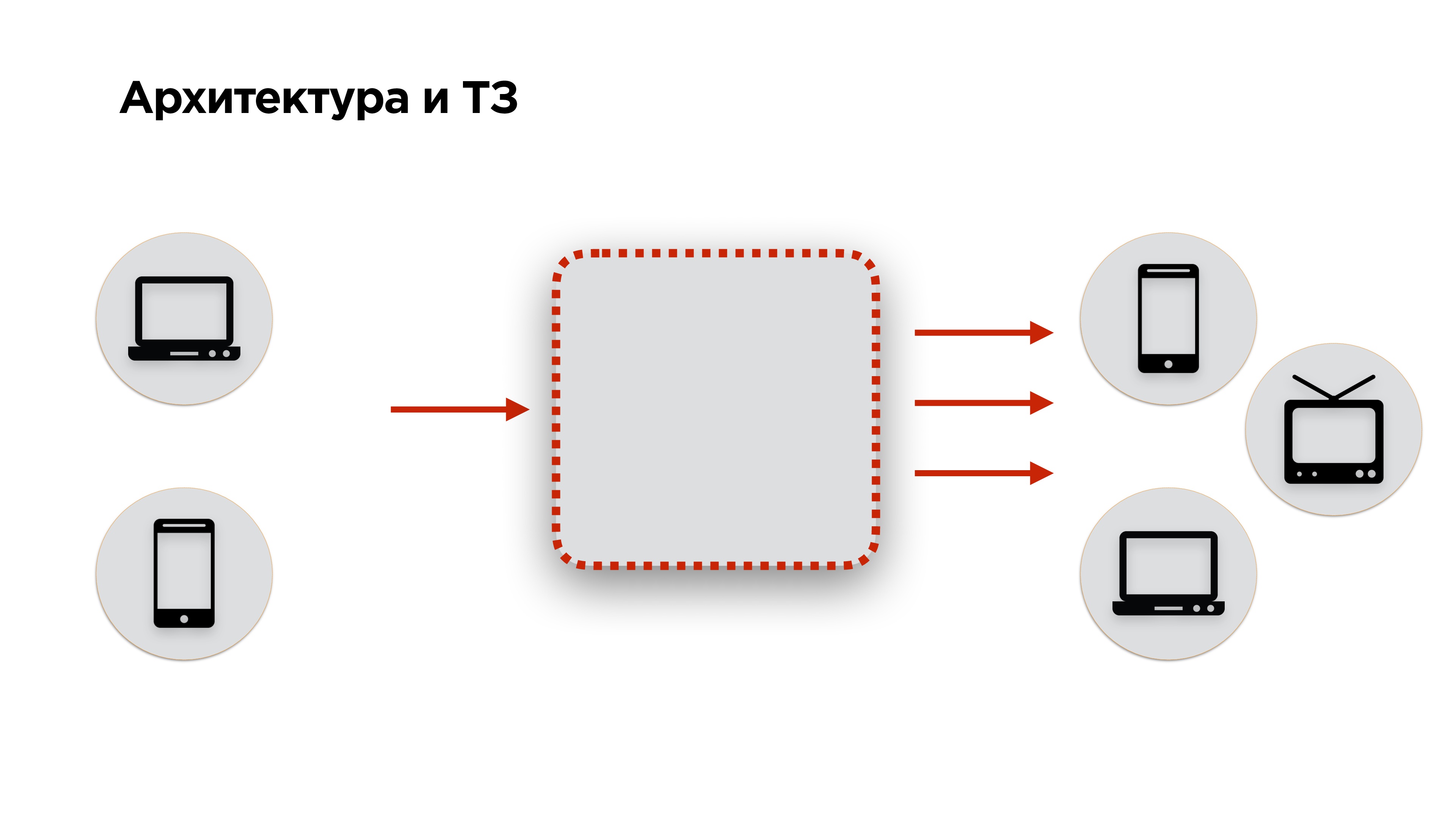
Then go to the technical task. If you have a customer, you have a TK. If you are a social network, you do not have TZ. How to make it?
You can certainly poll users and find out everything they want. But it will be a whole bunch of desires that do not correlate with the fact that people really need.
We decided to use the opposite method and looked at what users did NOT want to see from the broadcast service.
- The first thing that the user does not want is to see the delay at the start of the broadcast .
- The user does not want to see low-quality image stream .
- If there is an interactive broadcast, when the user communicates with his audience (counter live broadcasts, calls, etc.), then he does not want to see a delay between the streamer and the viewer .
It looks like the usual streaming service. Let's see what can be done to make cool streaming service instead of the usual one.

You could start by looking at all the streaming protocols, select the most interesting ones and compare them. But we did differently.
What are the competitors?
We began by studying the services of competitors.
Open Periscope - what do they have?As always, the main thing is architecture.
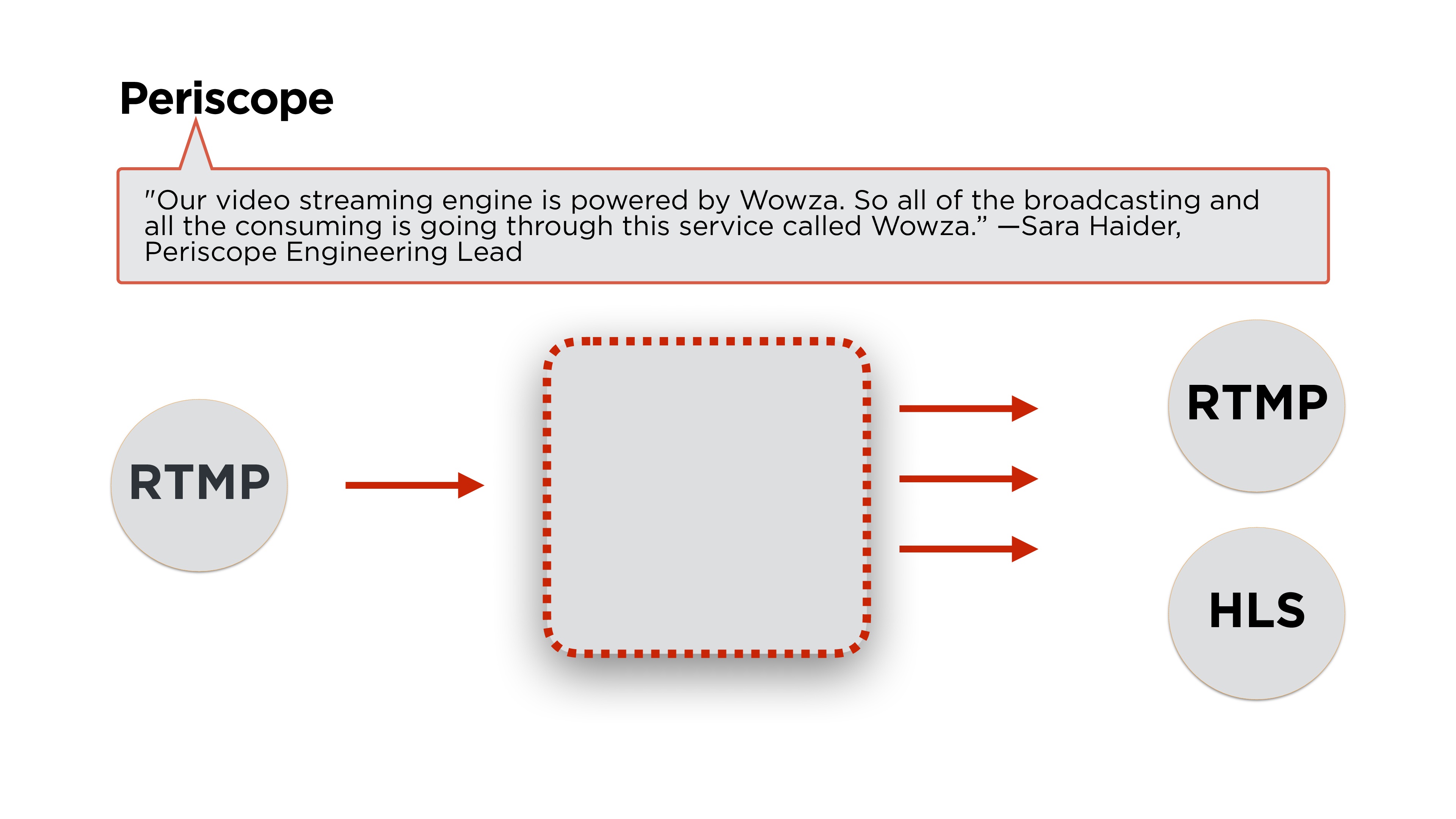
Sarah Haider, Periscope's lead engineer, writes that they use Wowza for the backend. If you read the articles a little more, we will see that they make a stream using the
RTMP protocol, and distribute it either in RTMP or in HLS. Let's see what these protocols are and how they work.
Test Periscope on our three main requirements.
 Starting speed
Starting speed is acceptable (less than a second on good networks), constant
quality is about 600 px (not HD) and at the same time
delays can be up to 12 seconds .
By the way, how to measure the delay in the broadcast?
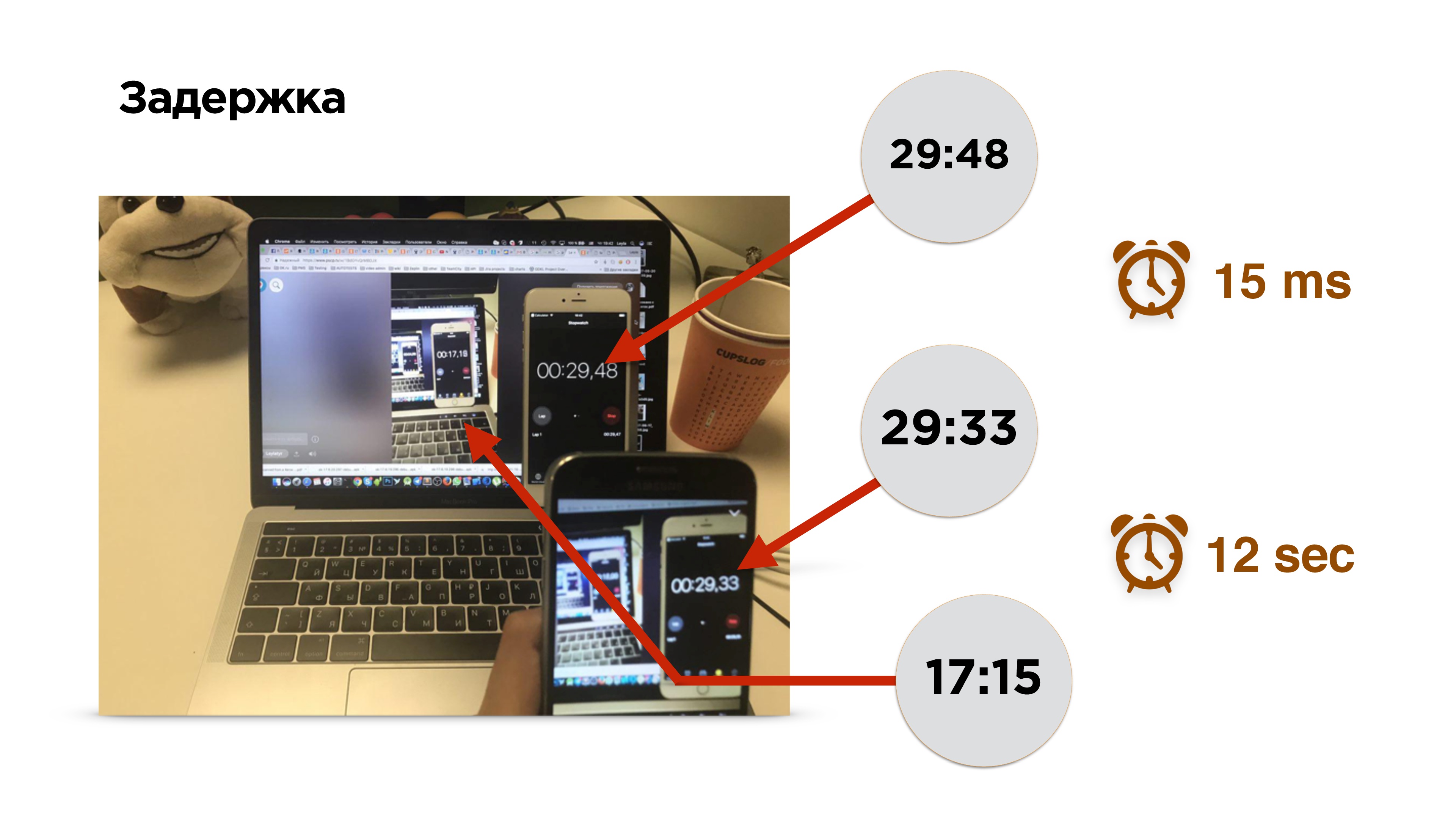
This is a photo of the measurement of the delay. There is a mobile phone with a timer. We turn on the broadcast and see the image of this phone on the screen. For 0.15 milliseconds, the image fell on the sensor of the camera and was derived from the video memory on the phone screen. After that we turn on the browser and watch the broadcast.
Oh! She is a little behind - about 12 seconds.
To find the reasons for the delay, let's stream profile the video.
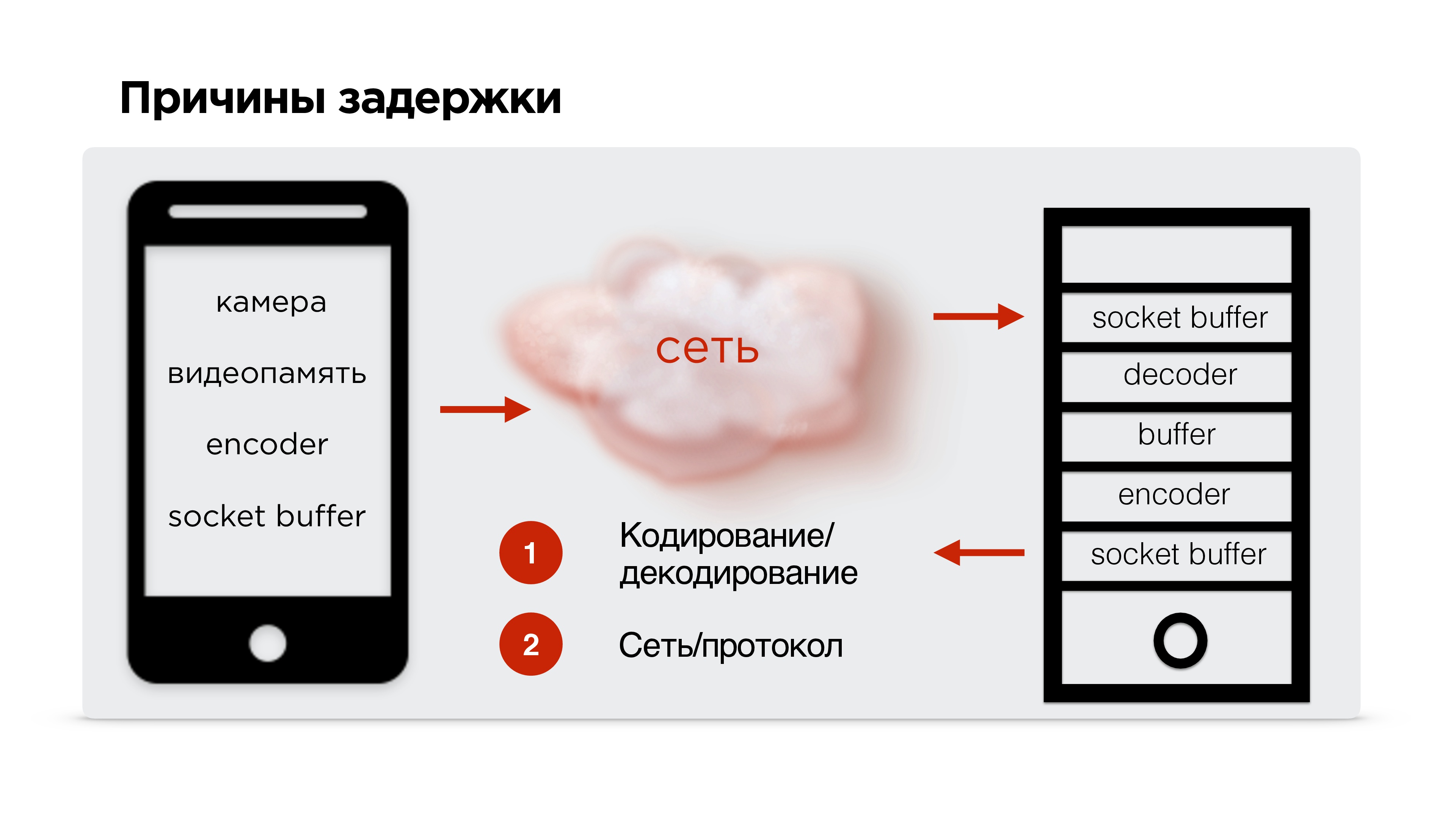
So, there is a mobile phone, the video comes from the camera and enters the video buffer. Here the delays are minimal (≈0.15 ms). Then the encoder encodes the signal, packages it and sends it to the socket buffer. This all flies to the net. Further, the same thing happens on the receiving device.
Basically, there are two main difficult points to consider:
- video encoding / decoding;
- network protocols .
Video encoding / decoding
I will tell a little about coding. You still come across it if you do Low Latency Live Streaming.
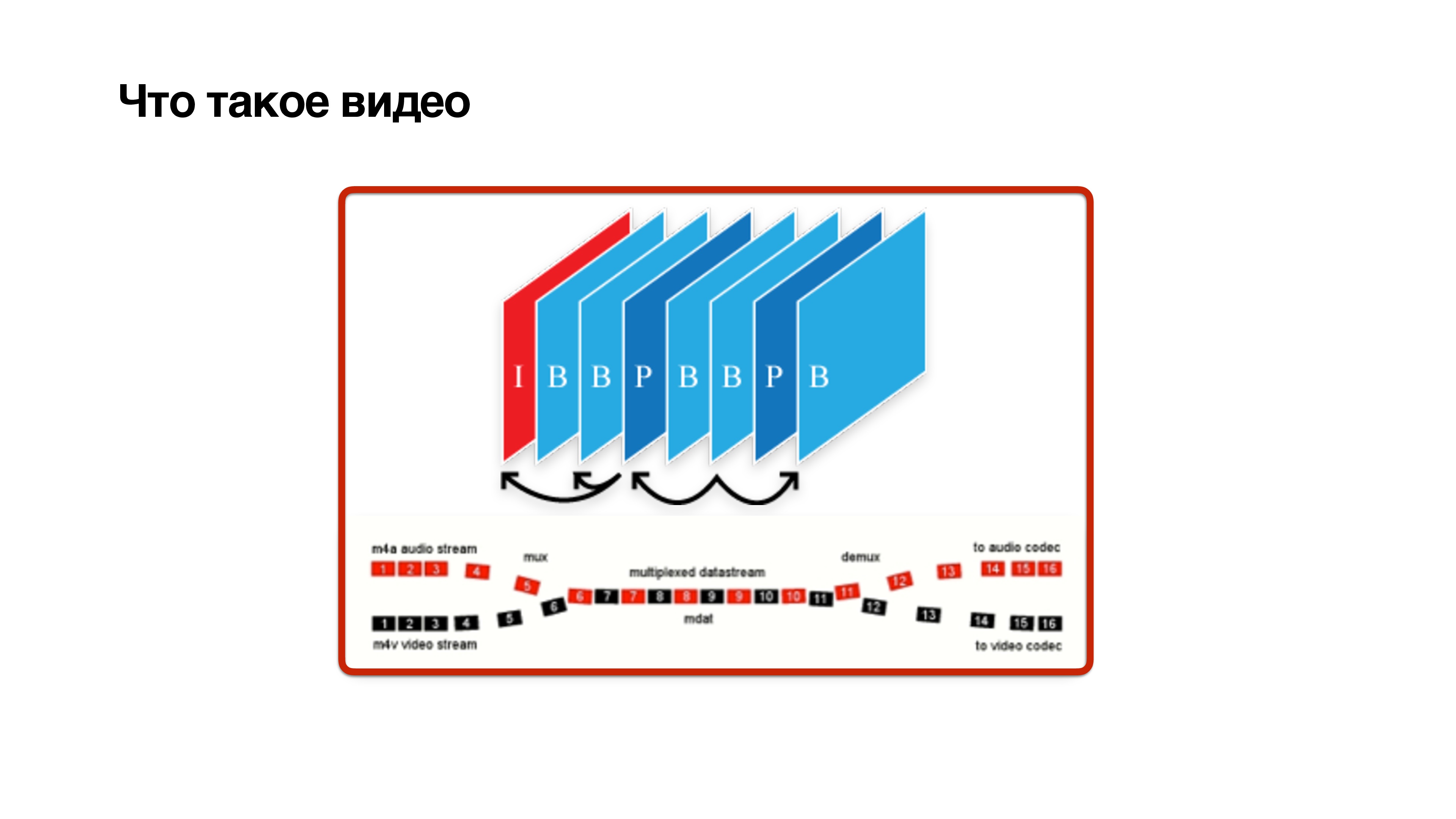
What is a video? This is a set of frames, but not quite simple. Frames are of three types: I, P and B-frame:
- I-frame is just jpg. In fact, this is a reference frame, it does not depend on anyone and contains a clear picture.
- P-frame depends solely on previous frames.
- Sly B- frames may depend on the future. This means that in order to calculate the b-frame, it is necessary that future frames also come from the camera. Only then can b-frame be decoded with some delay.
This shows that
B- frames are harmful . Let's try to remove them.
- If you are streaming from a mobile device, you can try to enable the baseline profile . He will disable the b-frame.
- You can try to adjust the codec and reduce the delay for future frames so that the frames arrive faster.
- Another important thing in codec tuning is the inclusion of CBR (constant bitrate).
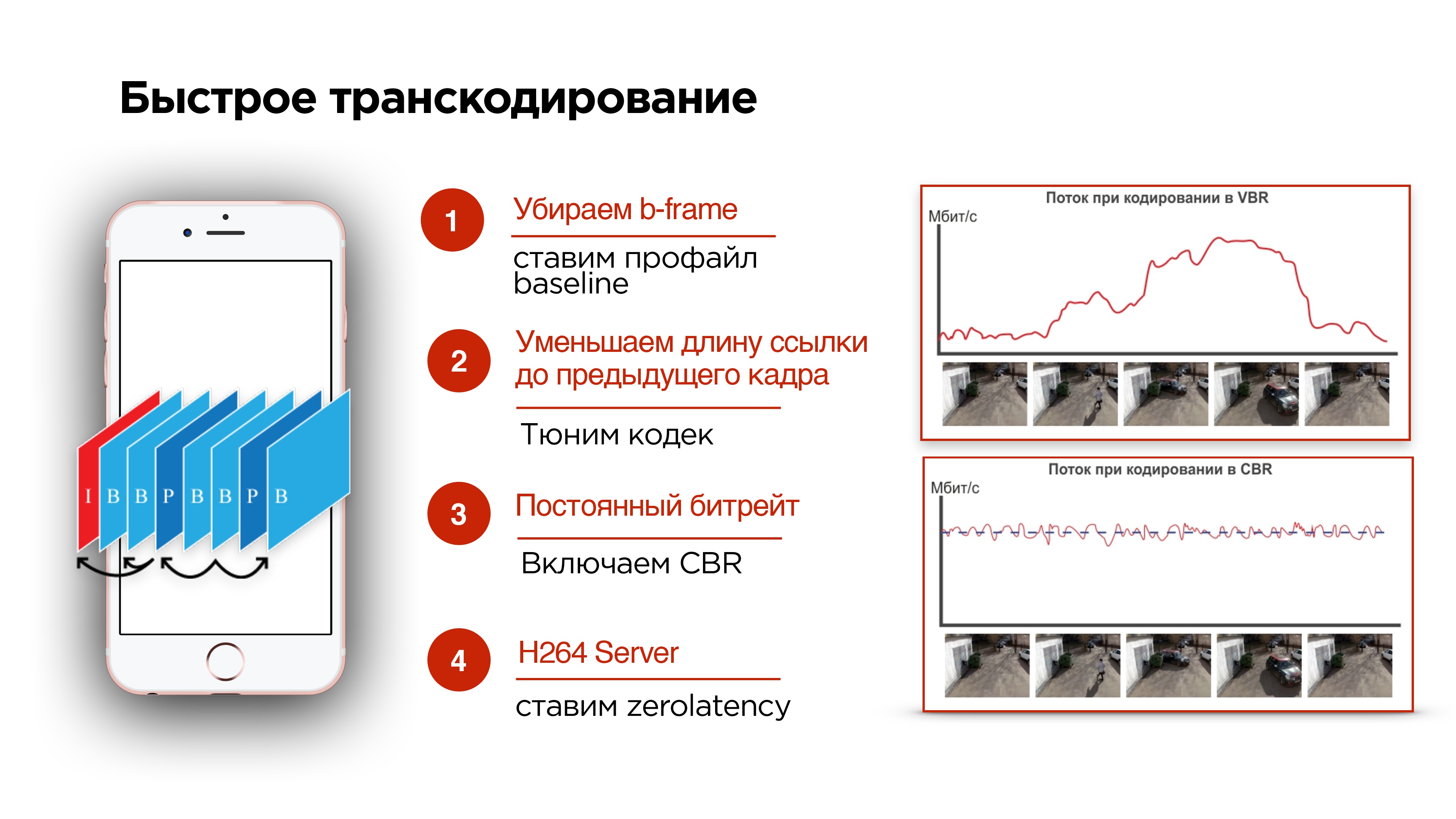
How codecs work is illustrated in the slide above. In this example, the video is a static picture, its encoding saves disk space, since almost nothing changes there, and the video bitrate is low. Changes occur - entropy grows, video bitrate grows - for storage on a disk it is great.
But at the moment when the active changes began, and the bit rate increased, most likely all the data in the network will not get through. This is exactly what happens when you make a video call and start turning, and your subscriber is slowed down by a picture. This is due to the fact that the network does not have time to adapt to the change in bitrate.
You need to include CBR . Not all codecs on Android will support it correctly, but they will strive for it. That is, you need to understand that with the CBR you do not get an ideal picture of the world, as in the bottom picture, but you still need to turn it on.
4. And on the backend, you need to add zerolatency to the H264 codec - this will allow you not to make dependencies in frames for the future.
Video transmission protocols
Consider what protocols streaming offers industry. I conditionally broke them into two types:
- streaming protocols;
- segment protocols.
 Streaming protocols
Streaming protocols are protocols from the world of p2p calls:
RTMP, webRTC, RTSP / RTP . They differ in that users agree on what channel they have, select the codec bitrate according to the channel. And they have additional commands of this kind, like “give me a supporting frame”. If you have lost a frame, you can re-request it in these protocols.
The difference between the
segment protocols is that no one agrees with anyone. They cut video into segments, store each segment in different qualities, and the client can choose which segment to watch. Each segment starts with a reference frame.
Consider the protocols in more detail. Let's start with streaming protocols and see what problems we can face if we use streaming protocols for broadcast streaming.
Streaming protocols
Periscope uses RTMP. This protocol appeared in 2009, and at first Adobe did not fully specify it. Then he had some sort of difficulty with the fact that Adobe wanted to sell only its own server. That is, RTMP developed quite difficult. Its main problem is that
it uses TCP , but for some reason it was Periscope that chose it.

If you read in detail, it turns out that Periscope uses RTMP for broadcasting with a small number of viewers. Just such a broadcast, if you have an insufficient channel, most likely you will not be able to watch.
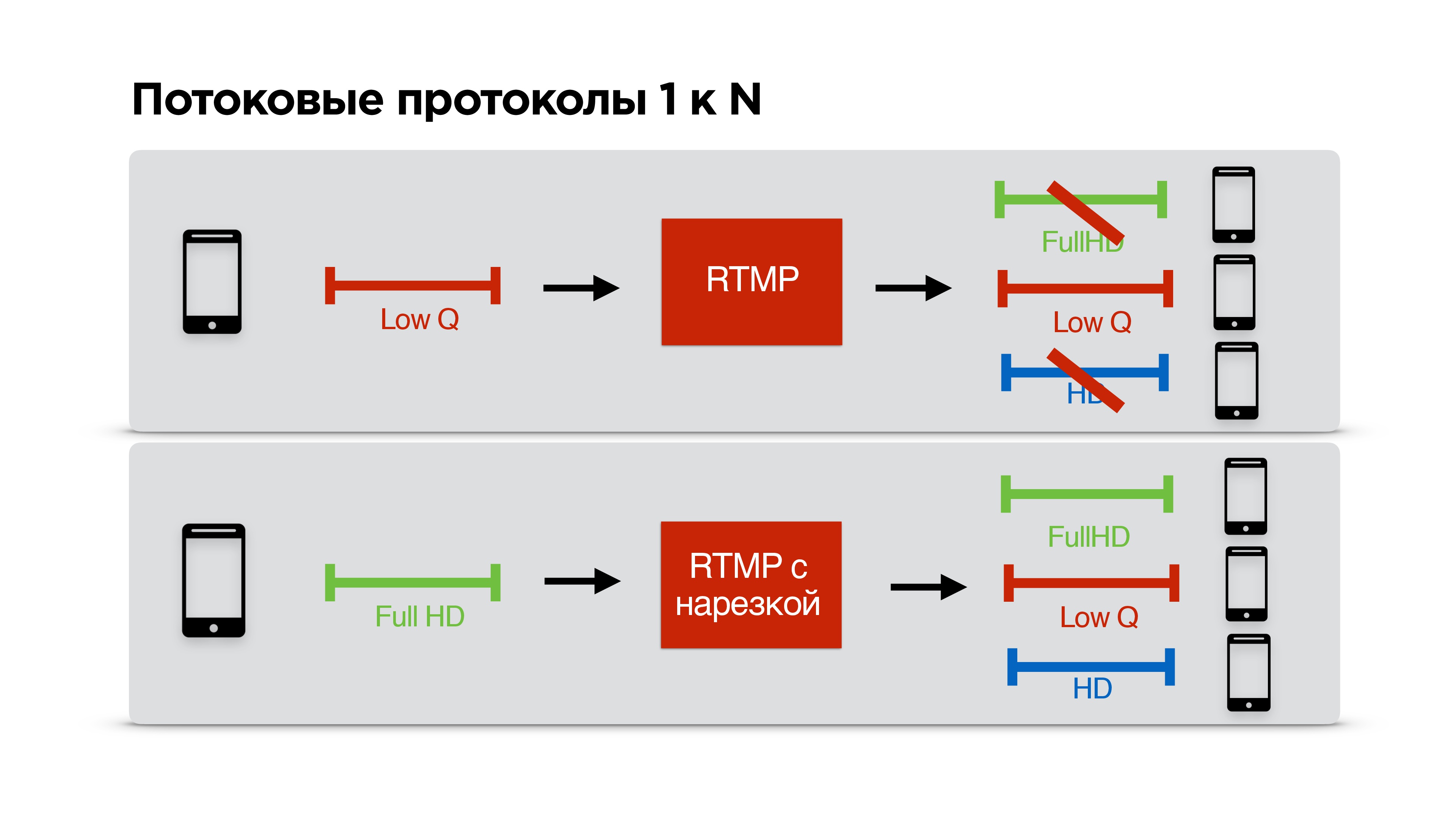
Consider a specific example. There is a user with a narrow communication channel who watches your broadcast. You negotiate a low bitrate with RTMP and start streaming for him personally.
Another user comes to you with a cool Internet, you also have a cool Internet, but you have already agreed with someone about low quality, and it turns out that this third one with a cool Internet looks at the stream in poor quality, despite the fact that look good
This problem we decided to eliminate. We have done so that RTMP can be cut for each client personally, that is, the streaming people agree with the server, stream at the highest possible quality, and each client receives the quality that the network allows him.
Great!
But still RTMP is on top of TCP, and no one has insured us from blocking the beginning of the queue.
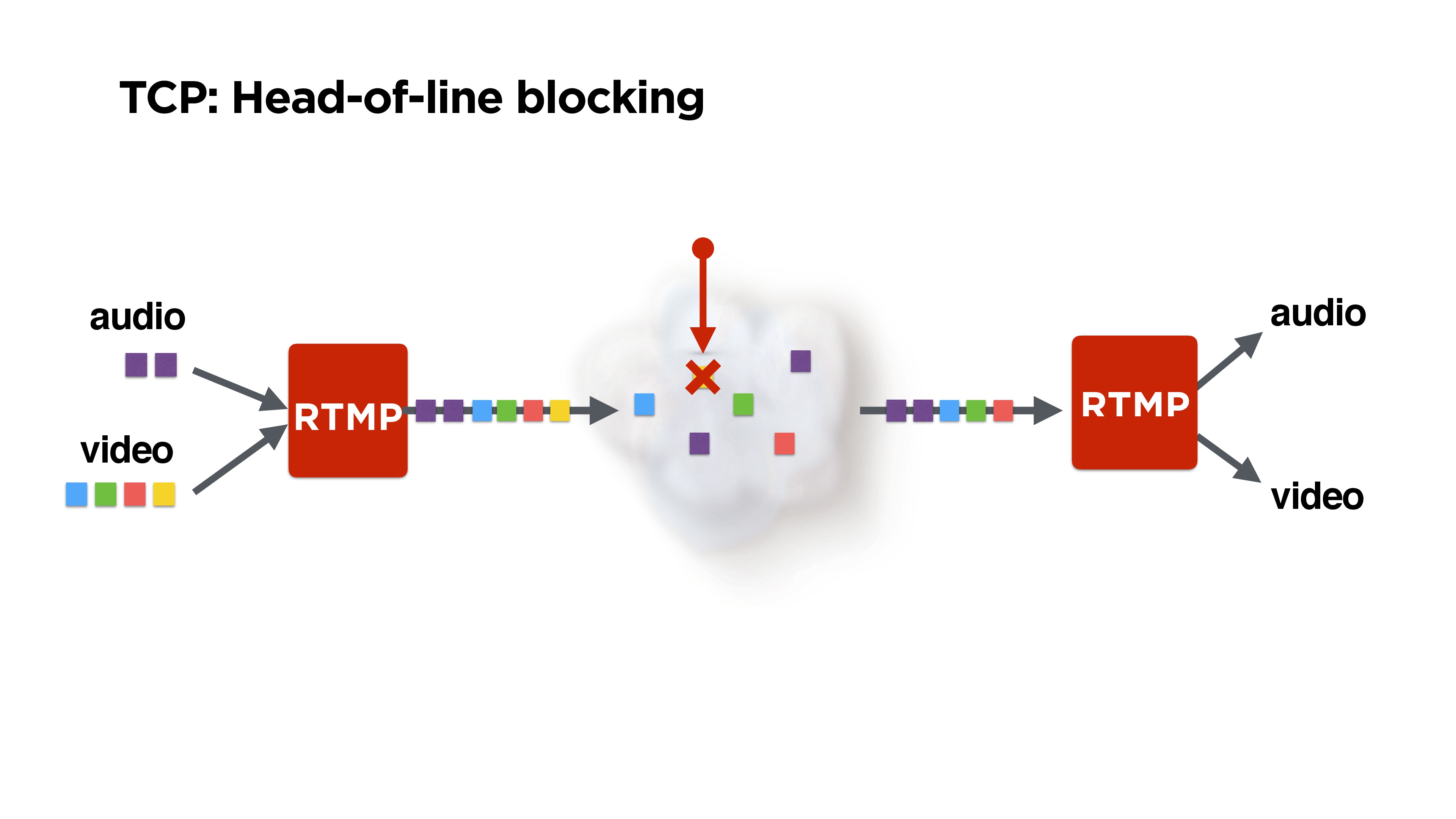
This is illustrated in the figure: we receive audio and video frames, RTMP packs them, maybe somehow mixes them up, and they fly off into the network.
But let's say we lose one packet. It is possible that the same yellow lost packet is generally a P-frame from some previous one - it could be dropped. Perhaps at a minimum, one could play audio. But TCP will not give us the rest of the packets, since it
guarantees delivery and consistency of packets . With this we must somehow fight.
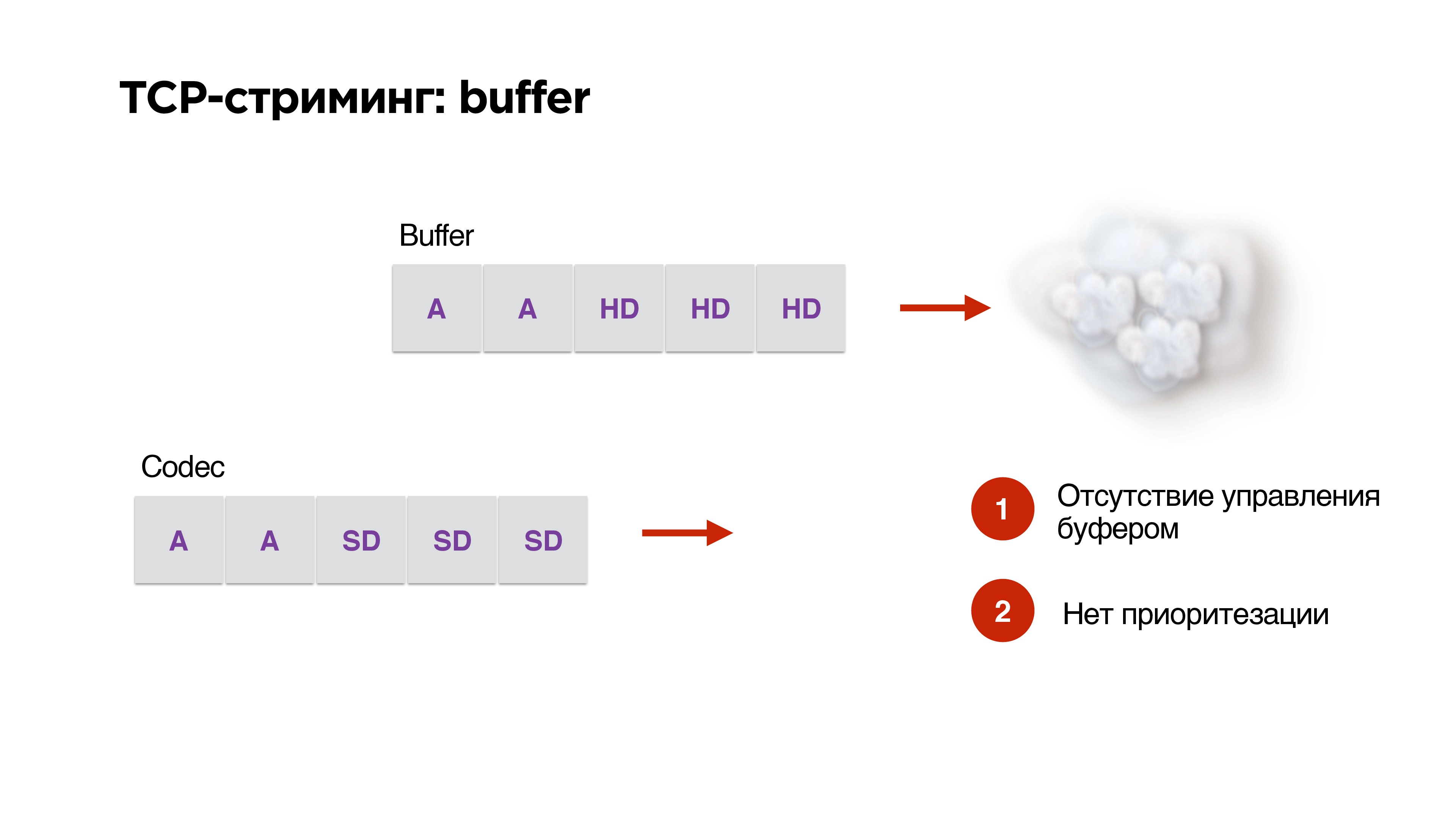
There is another problem with using TCP in streaming.
Suppose we have a buffer and high bandwidth network. We generate high resolution packages from our codec there. Then - op! - the network began to work worse. We have already indicated on the codec that the bitrate should be lowered, but the finished packages are already in the queue and cannot be
removed from them in any way. TCP is desperately trying to shove HD packets through our 3G.
We have no buffer management, no prioritization, so
TCP is extremely inappropriate for streaming .

Let's take a look at mobile networks now. It may be surprising for residents of capitals, but our average mobile network looks like this:
- 1.1 Mbit / s traffic;
- 0.1% packet loss;
- 300 ms average RTT.
And if you look at some regions and specific operators, then they have an
average daily percentage of packet loss of more than 3% , and RTT from 600 ms is normal.
TCP is, on the one hand, a cool protocol - it is very difficult to teach a car to drive immediately and on the highway and off-road. But then it became very difficult to teach her to fly over wireless networks.

Loss of even 0.001% of packets leads to a 30% reduction in throughput. That is, our user does not utilize the channel by 30% due to the ineffectiveness of the TCP protocol in networks with random packet loss.
In certain regions, packet loss reaches 1%, then the user has about 10% of the bandwidth.
Therefore,
we will not do it on TCP .
Let's see what else is in the world of streaming from UDP.
The WebRTC protocol has proven itself very well for p2p calls. On very popular sites they write that it’s very cool to use for calls, but for delivery of videos and music it’s not good.
His main problem is that he
neglects losses . With all the incomprehensible situations, he just drops.
There is still some problem in his attachment to calls, the fact is that he encrypts everything. Therefore, if you broadcast to broadcast, and there is no need to encrypt the entire audio / video stream, launching WebRTC, you are still straining your processor. Perhaps you do not need it.
 RTP streaming
RTP streaming is a basic protocol for transmitting data over UDP. Below on the slide to the right is a set of extensions and RFCs that had to be implemented in WebRTC in order to adapt this protocol for calls. In principle, you can try to do something like this - dial a set of extensions to RTP and get UDP streaming.
But it is very difficult .
The second problem is that if any of your clients do not support any extension, then the protocol will not work.

Segment Protocols
A good example of a segmented video protocol is
MPEG-Dash . It consists of a manifest file that you post on your portal. It contains links to files in different qualities, at the beginning of the file there is a certain index that says in which place of the file which segment begins.
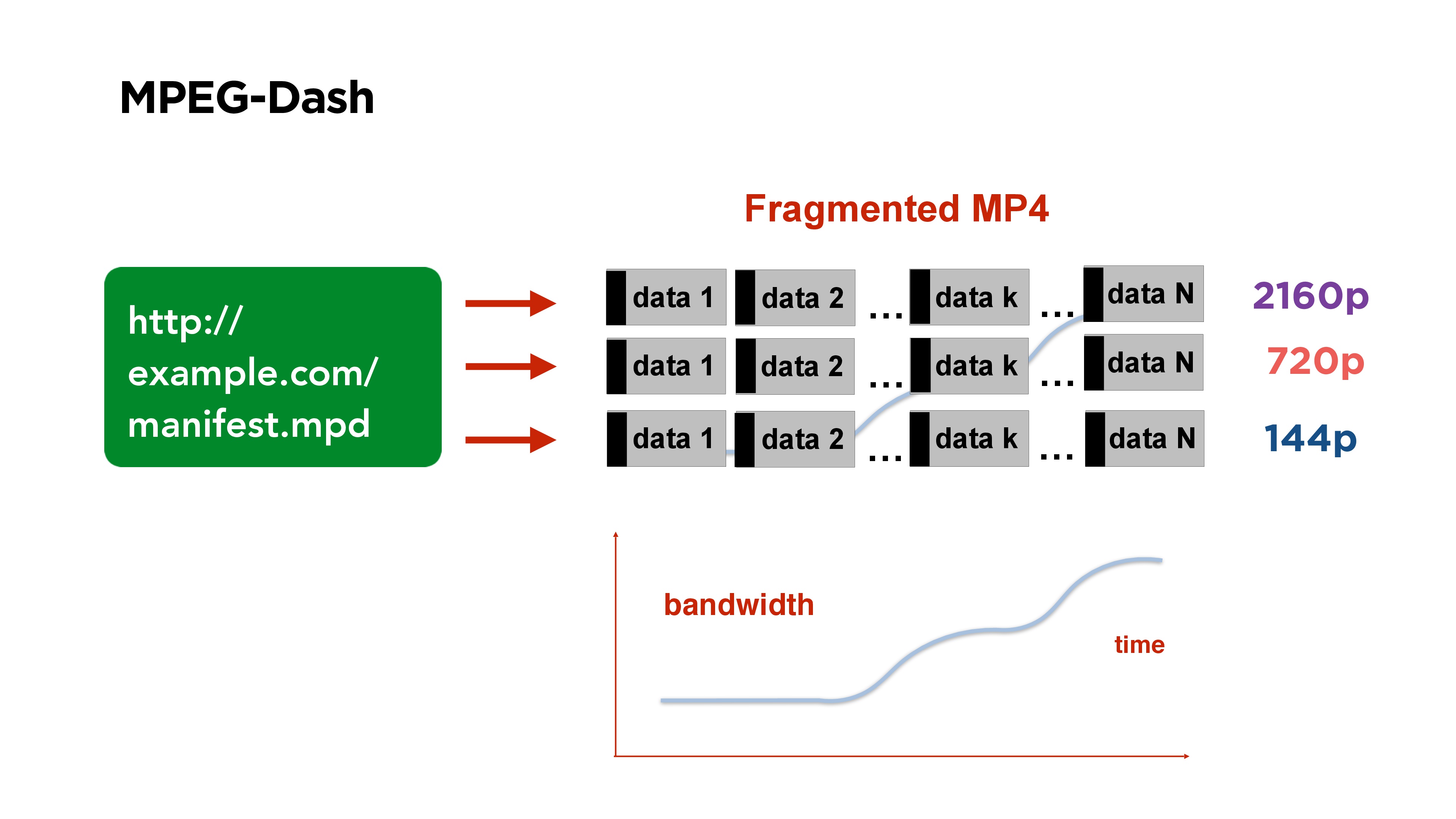
All videos are divided into segments, for example, for 3 seconds, each segment begins with a reference frame. If you watch such a video and the bitrate changes, you simply start to take a segment of the quality you need on the client side.
Another example of segmental streaming is
HLS .
MPEG-Dash is a solution from Google, it works well in Android, and Apple is an older solution, it has a number of certain disadvantages.

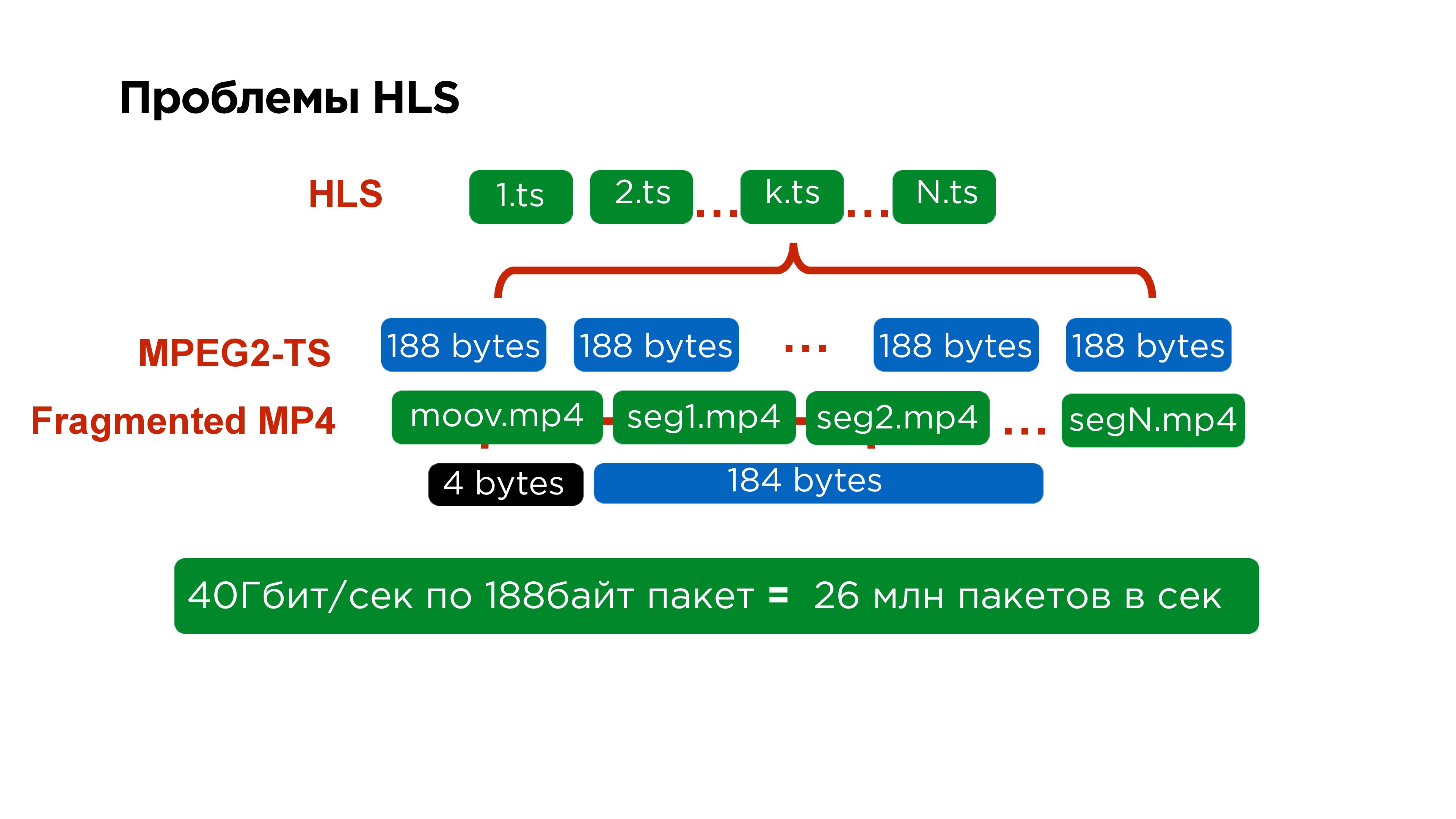
The first of these is that the main manifest contains references to secondary manifests, the secondary manifests for each specific quality contain references to each individual segment, and each individual segment is represented by a separate file.
If you look in more detail, within each segment is MPEG2-TS. This protocol was also made for the satellite; its packet size is
188 bytes . It is very inconvenient to pack video in this size, especially because you always supply it with a small header.
In fact, it is not only difficult for servers, which need to collect
26 million packets in order to process 40 GB of traffic, but it is also difficult on the client. Therefore, when we rewrote the iOS player to MPEG-Dash, we even saw some performance gain.
But Apple does not stand still. In 2016, they finally announced that they had the opportunity to push a fragment from MPEG4 into HLS. Then they promised to add it only for developers, but it seems that support on macOS and iOS should now appear.
That is, it would seem, fragmentary streaming is convenient - come, take the necessary fragment, start from the reference frame - it works.
Minus: it is clear that the supporting frame from which you started is not the same frame as the one who is streaming. Therefore,
there is always a delay .
In general, it is possible to finish HLS before delays of about 5 seconds, someone says that he managed to get 4, but in principle the
decision to use fragment streaming for broadcasting is not very good .

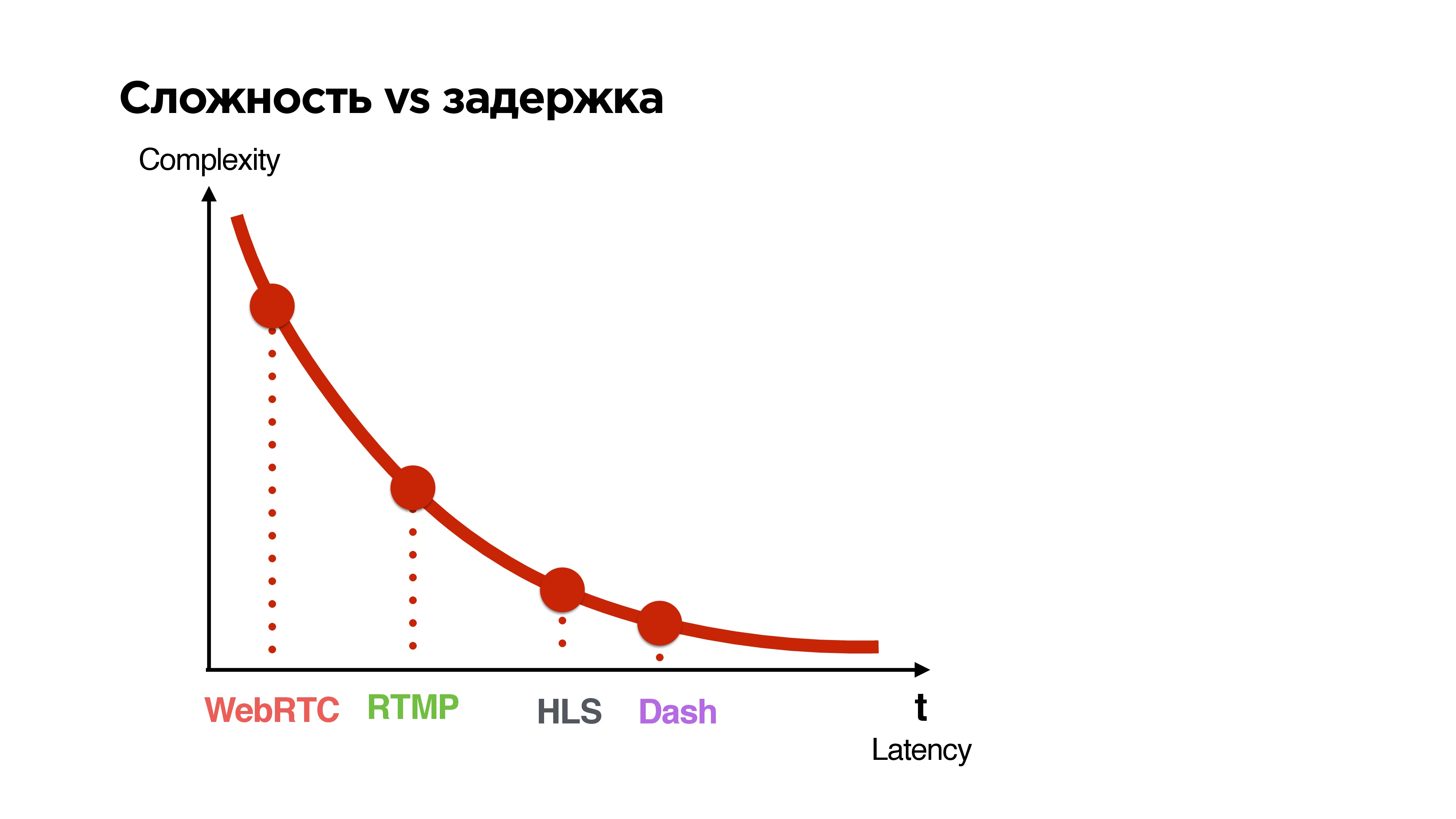
Complexity vs delay
Let's look at all the available protocols and sort them by two parameters:
- the latency they give between the broadcast and the viewer;
- complexity (complexity).
The smaller the delay is guaranteed by the protocol, the more complicated it is.
What do we want?
We want to make a UDP protocol for streaming from 1 to N with a delay comparable to p2p communication, with the option of optional encryption of packets depending on whether it is private or public.
What other options are there? You can wait, for example, when Google releases its QUIC.
I'll tell you a little what it is. Google is positioning Google QUIC as a replacement for TCP - some TCP 2.0. It has been developed since 2013, now it has no specifications, but it is fully accessible in Google Chrome, and it seems to me that they sometimes include it to some users in order to see how it works. In principle, you can go to the settings, enable QUIC, go to any Google site and get this resource via UDP.
We decided not to wait until they all specify, and file their decision.
Protocol requirements:
- Multithreading , that is, we have several streams - control, video, audio.
- Optional delivery guarantee - the control flow has a 100% guarantee, we need the video least of all - we can drop a frame there, we would still like audio.
- Prioritization of streams - so that audio goes ahead, and the manager is flying at all.
- Optional encryption : either all data, or just headers and sensitive data.
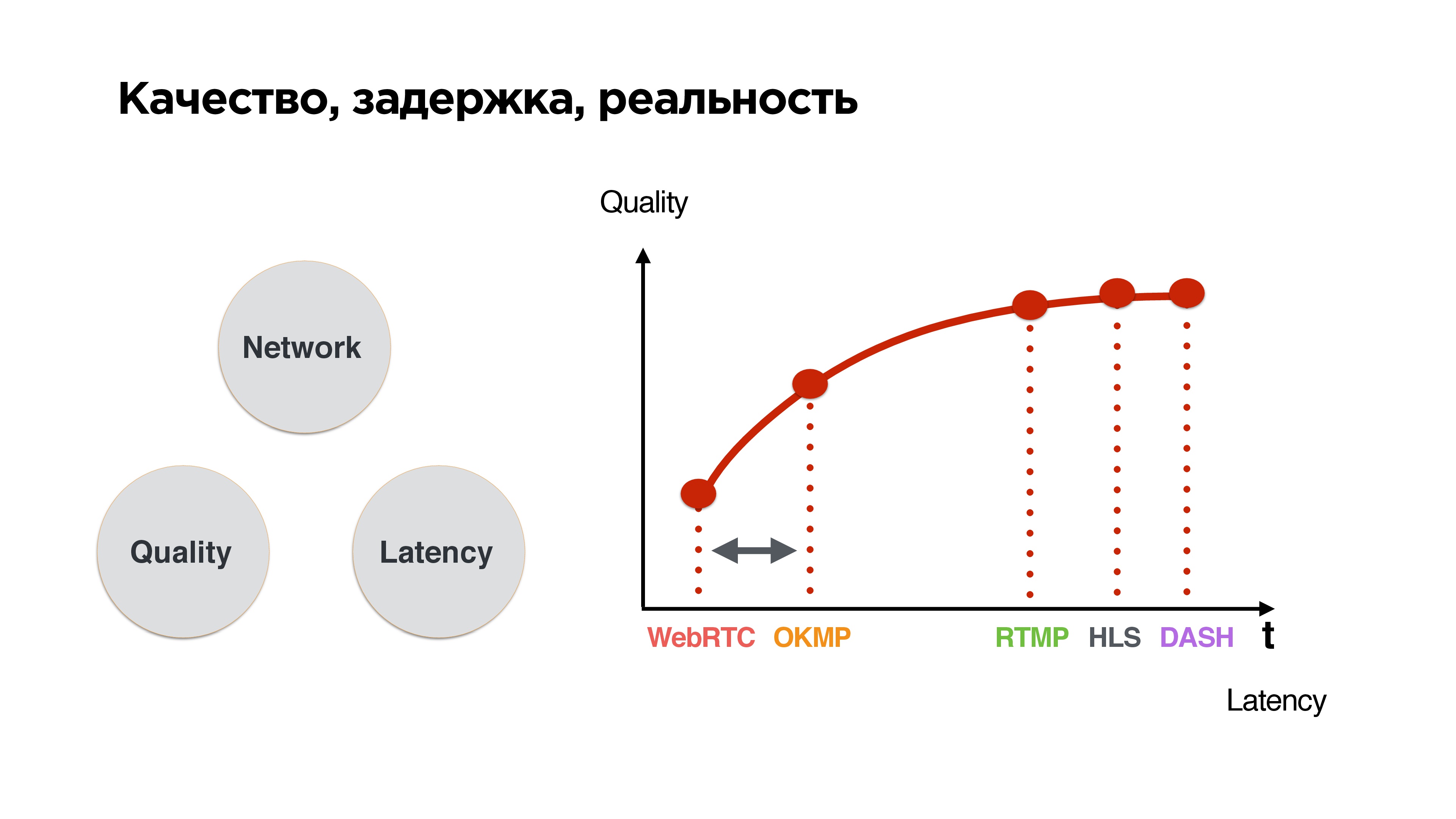
This is a standard triangle: if a good network, then high quality and low latency. As soon as an unstable network appears, packets begin to disappear, we balance between quality and delay. We have a choice: either wait until the network is adjusted and send everything that has accumulated, or drop it and somehow live with it.
If you sort the protocols according to this principle, it is clear that
the lower the waiting time, the worse the quality - a fairly simple conclusion.
We want to wedge our protocol into the zone where the delays are close to WebRTC, but at the same time be able to push it a little bit, because, after all, we do not have calls, but broadcasts. The user wants to ultimately receive high-quality stream.
Development
Let's start writing a UDP protocol, but first look at the statistics.
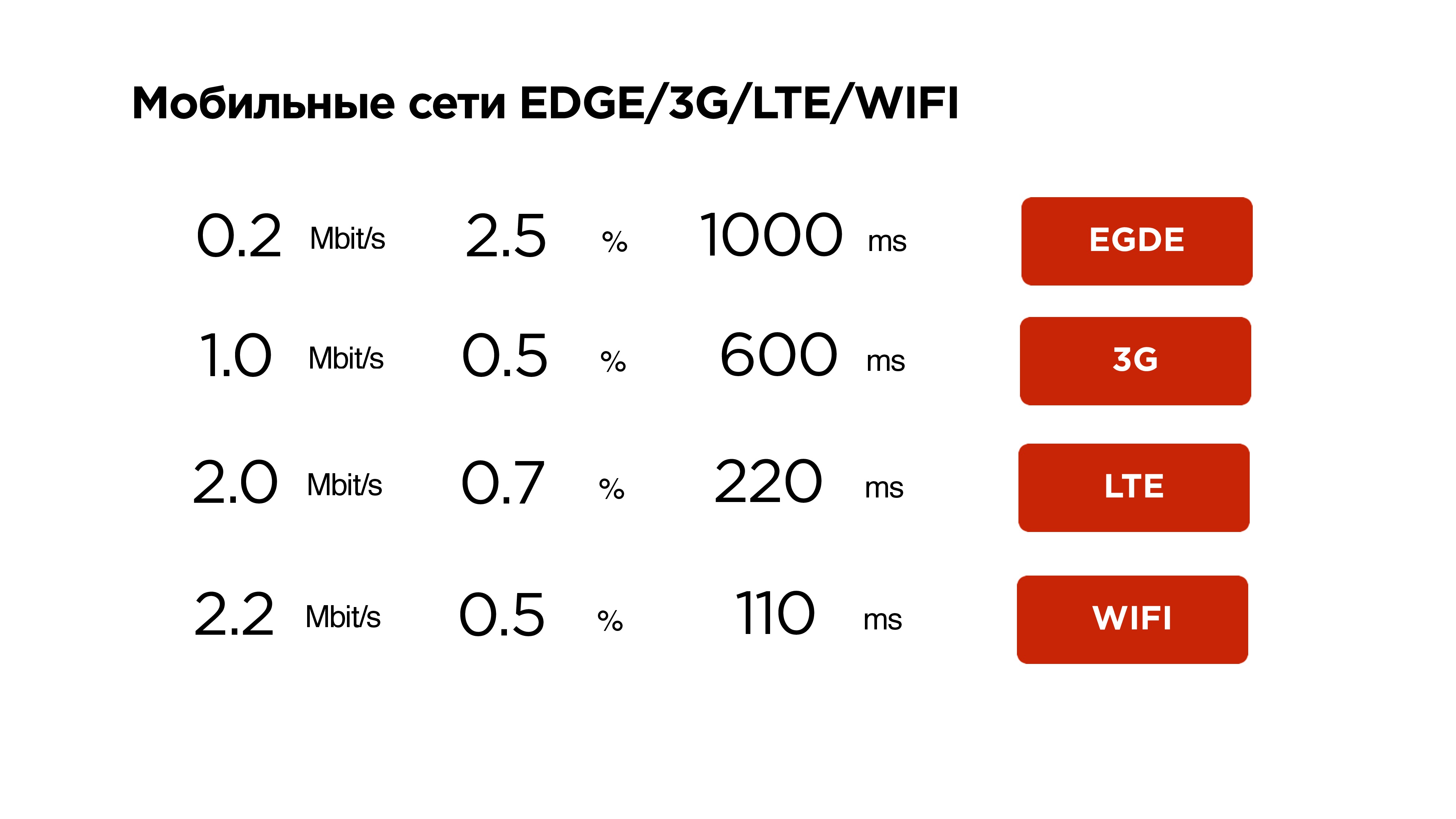
This is our mobile network statistics. Here you can see that the average Internet is a little more than megabit, packet loss is about 1% - this is normal, and RTT is around 600 ms - on 3G these are just average values.
We will be guided by this when writing the protocol - let's go!
UDP protocol
We open socket UDP, we take away the data, we pack, we send. We take the second pack from the codec, still send. It seems to be all great!

But we get the following picture: if we start randomly sending UDP packets to the socket, then according to the statistics for the 21st packet, the probability that it will reach will be only 85%. That is, packet loss will already be 15%, which is no good. It needs to be fixed.

This is fixed as standard. The figure illustrates life without Pacer and life with
Pacer .
Pacer is such a thing that pushes packages in time and controls their loss; Looks at what packet loss is now, depending on this adapts to the speed of the channel.
As we remember, for mobile networks, 1-3% packet loss is the norm. Accordingly, it is necessary to work with this somehow. What if we lose packages?
Retransmit
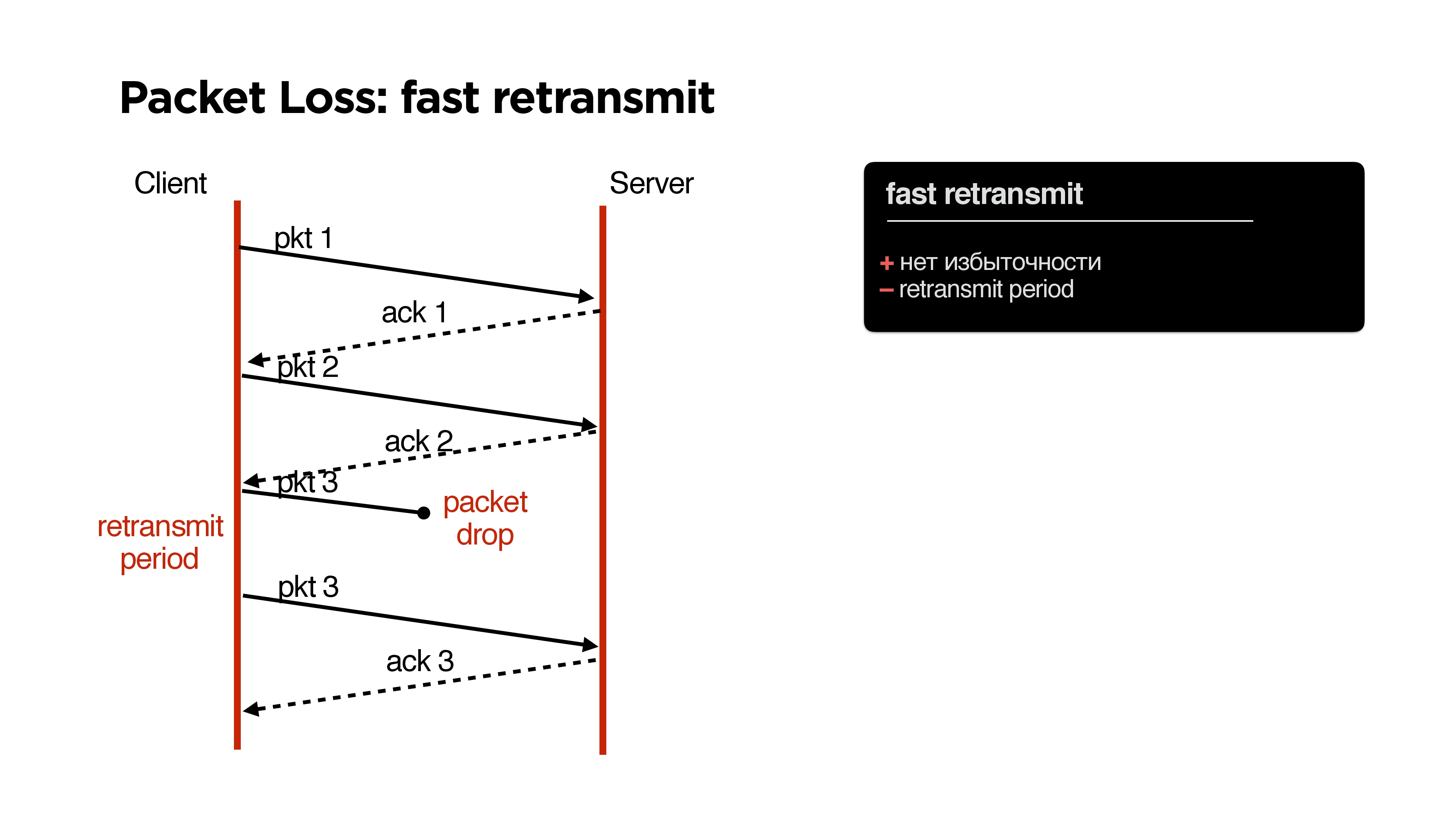
In TCP, as you know, there is a fast retransmit algorithm: we send one packet, the second, if the packet is lost, then after a while (retransmit period) we send the same packet.
What are the advantages here? No problems, no redundancy, but there is a minus - some
retransmit period .
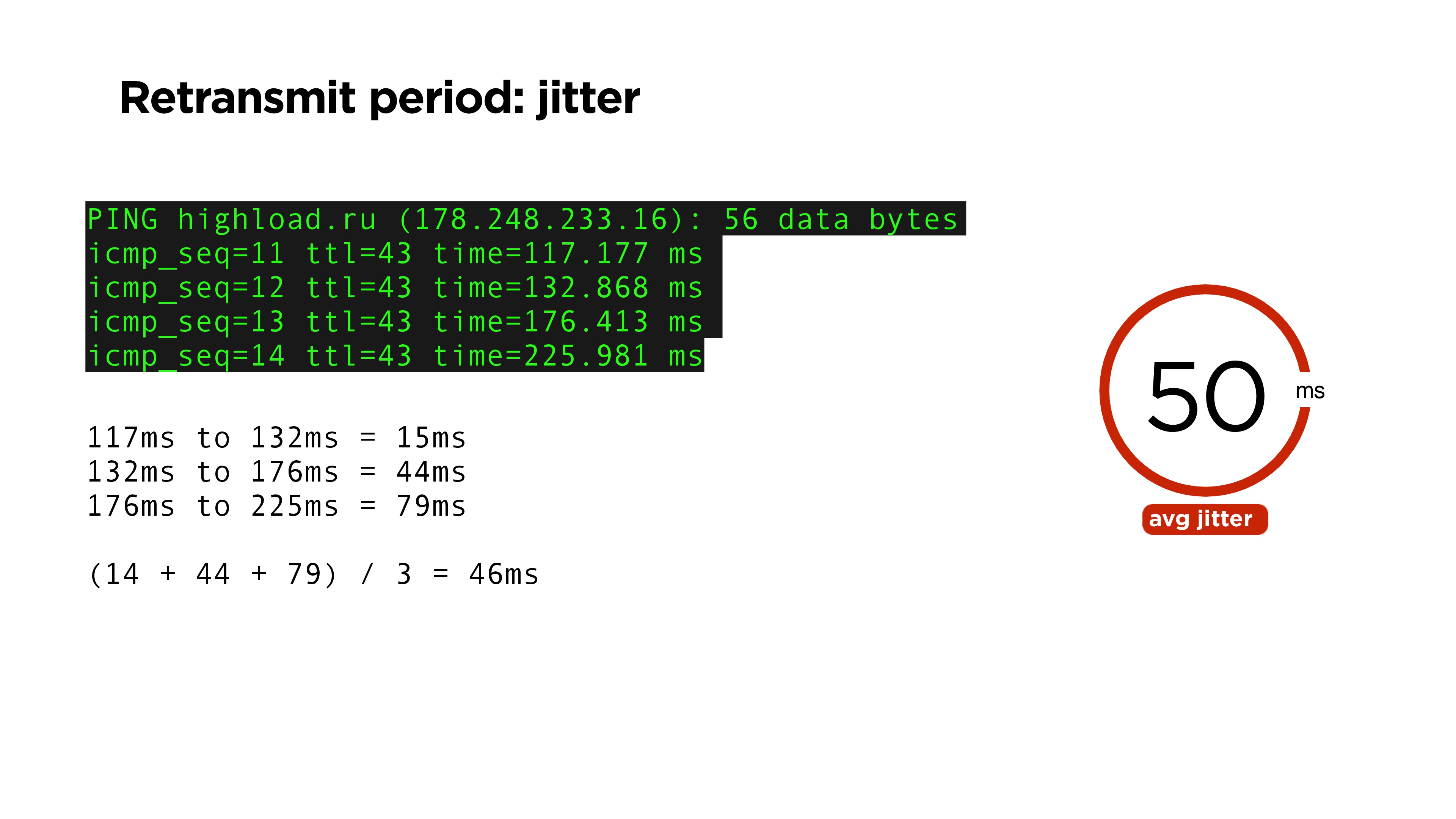
It seems that it is very simple: after some time you need to repeat the package, if you have not received confirmation of it. It is logical that this may be a time equal to ping time. But ping is not a stable value, and therefore we can’t determine if the packet is lost through the average RTT time.
In order to evaluate this, you can, for example, use a value such as jitter: we consider the difference between all our ping packages. For example, in the example above, the average is 46 ms. On our portal the average jitter is 50.

Let's look at the probability distribution of arrivals of packages by time. There is some RTT and some value, after which we can really understand that acknowledge did not come and resubmit the packet. Basically, there is RFC6298, which in TCP says how sly it can be counted.
We do this through jitter. On the portal we have jitter by ping about 15%. It is clear that the retransmit period should be at least 20% more than RTT.
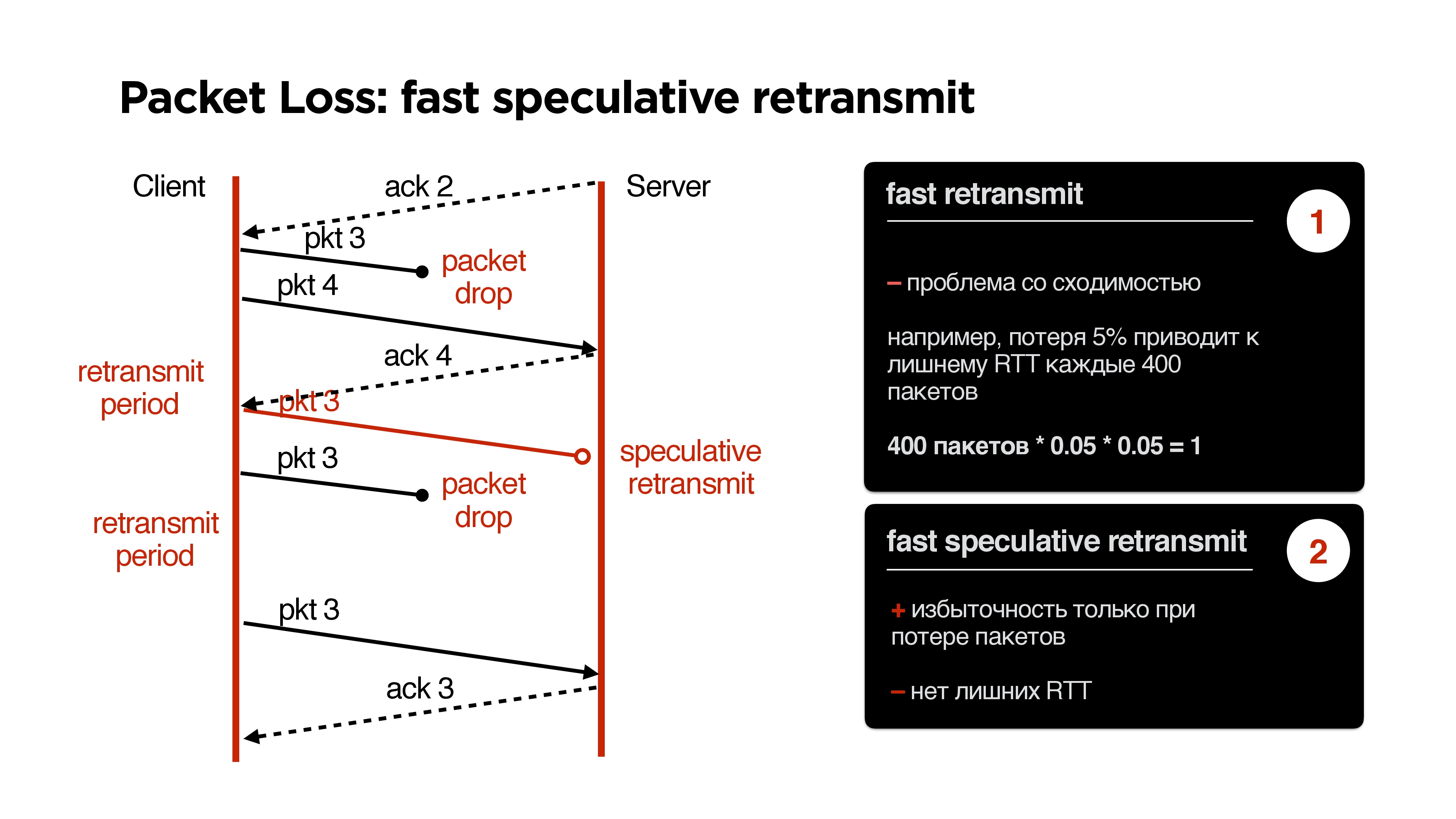
Another case with retransmit. Since last time, we had acknowledge to the second package. We send the third packet, which is lost, while other packets are being sent. After this comes the retransmit period, and we send the third packet again. He dropped again, and we send him again.
If we have a double packet loss, then a new problem appears on retransmit. If we have, for example, packet loss 5%, and we send 400 packets, then for 400 packets we will have a double packet-drop situation exactly once, that is, when we sent a packet through the retransmit period, and it did not reach again .
This situation can be corrected by adding some redundancy. You can start sending a packet, for example, if we received acknowledge from another packet. We believe that the advance is a rare situation; we can start sending the third packet at the time indicated by speculative retransmit on the slide above.
You can still poshamanit with a speculative retransmit, and everything will work well.
But here we are talking about redundancy. And what if to add
Forward Error Correction ? Let's just provide all of our packages, for example, XOR. If we know for sure that everything is so sad on mobile networks, then let's just add another sachet.
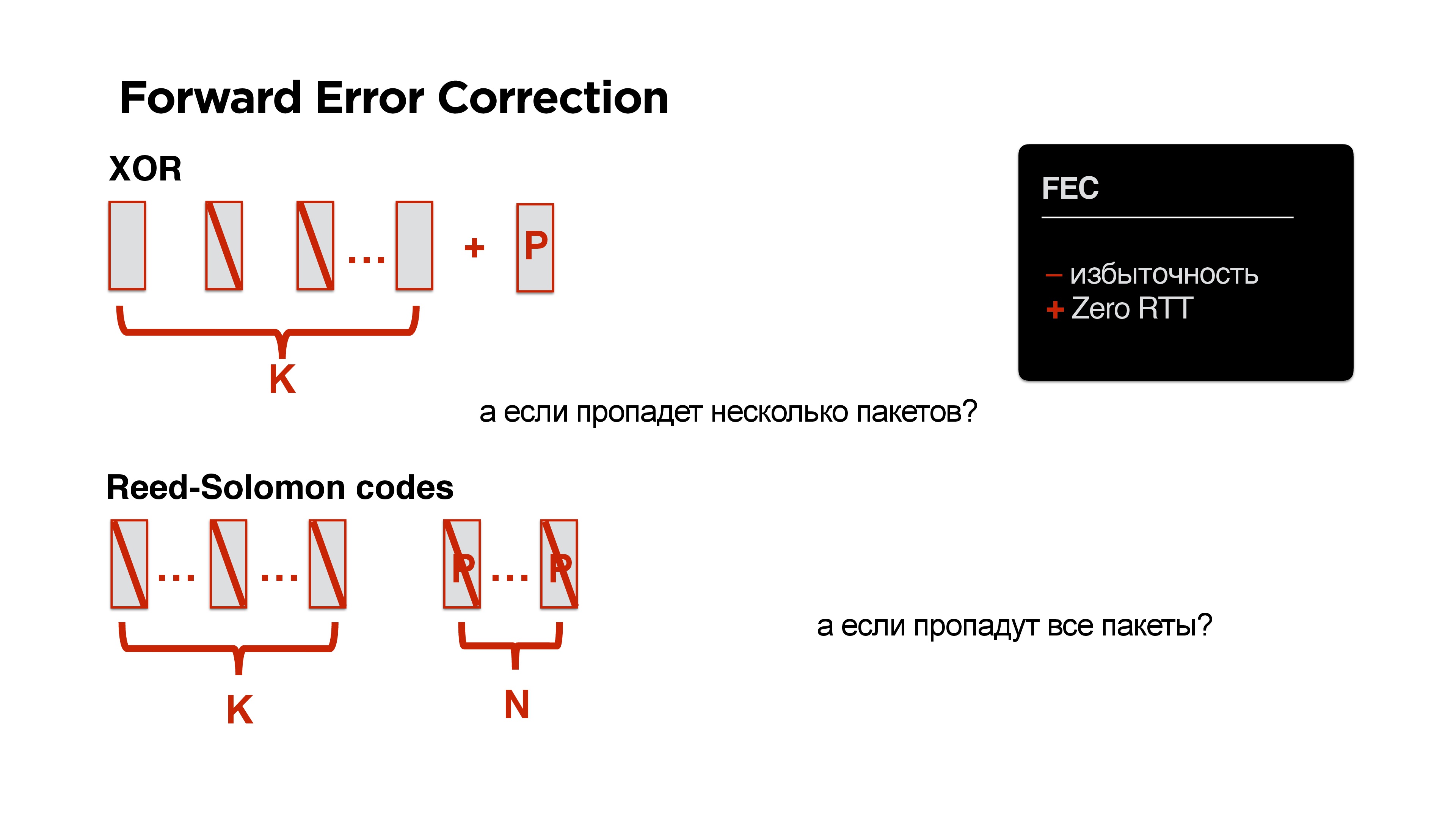
Great! We do not need any round trip, but we already have redundancy.
And what if not one package disappears, but two at once? Let's take another solution instead of XOR - for example, there is a code Reed-Solomon, Fountain codes, etc. The idea is this: if there are K packets, you can add N packets to them so that any N could be lost.
It seems to be cool!
Well, if we have such a bad network that just all the packages have disappeared, then a negative acknowledgment is very conveniently added to our Forward Error Correction.
NACK
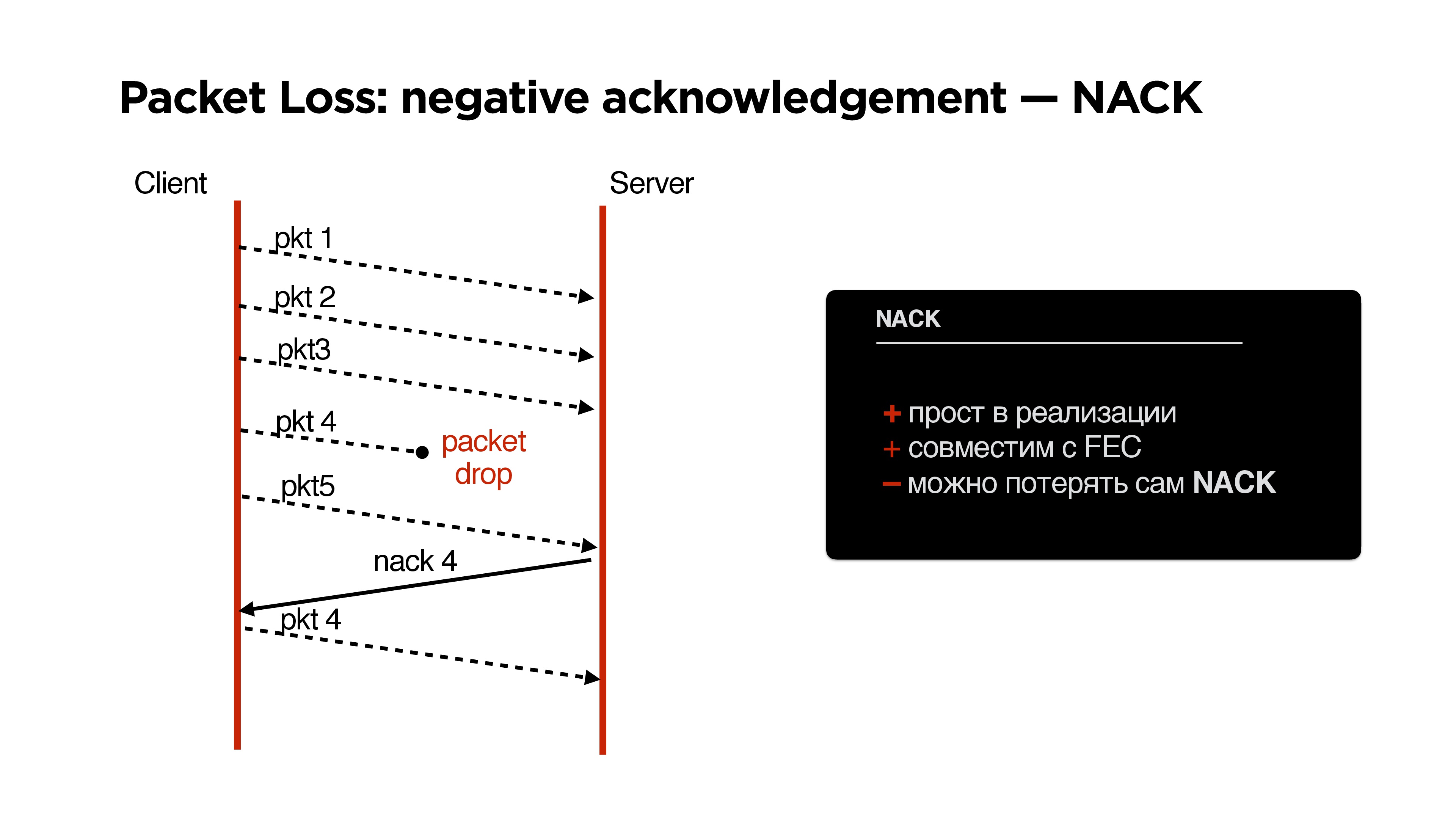
If we have lost so many packages that our parity protection (let's call it that) does not save us, we request this package additionally.
Pros NACK:
- Simple to implement, though you can lose yourself a negative acknowledgment, but this is a minor problem.
- Well compatible with FEC.
So there are two interesting solutions:
- On the one hand, FEC + NACK;
- Fast retransmit, on the other hand.
Let's see how packet loss is distributed.

It turns out that the packets are not lost evenly by one thing, but by packs (above the distribution graph). And there are interesting peaks, for example, on 11 packets, there are still peaks on 60-80 packets. They repeat, and we learn where they come from.
On average, 6 packages are lost on our portal.

Detailed consideration of the networks shows that the worse the network, the greater the number. The table shows the time that the network was unavailable. For example, Wi-Fi is unavailable for 22 ms and loses 5 packets, 3G can lose 8 packets in 34 ms.

The question is: if we know that we have 90% packet loss on the portal, it fits into 10 packets, and the average gap is 25 ms, which will work better - FEC + NACK or Fast retransmit?
Here, probably, it is necessary to tell that Google, when it made its QUIC protocol in 2013, put Forward Error Correction at the head, thinking that it would solve all the problems. But in 2015 they turned it off.
We tested both options and we did not manage to start FEC + NACK, but we are still trying and do not despair.
Consider how it works.
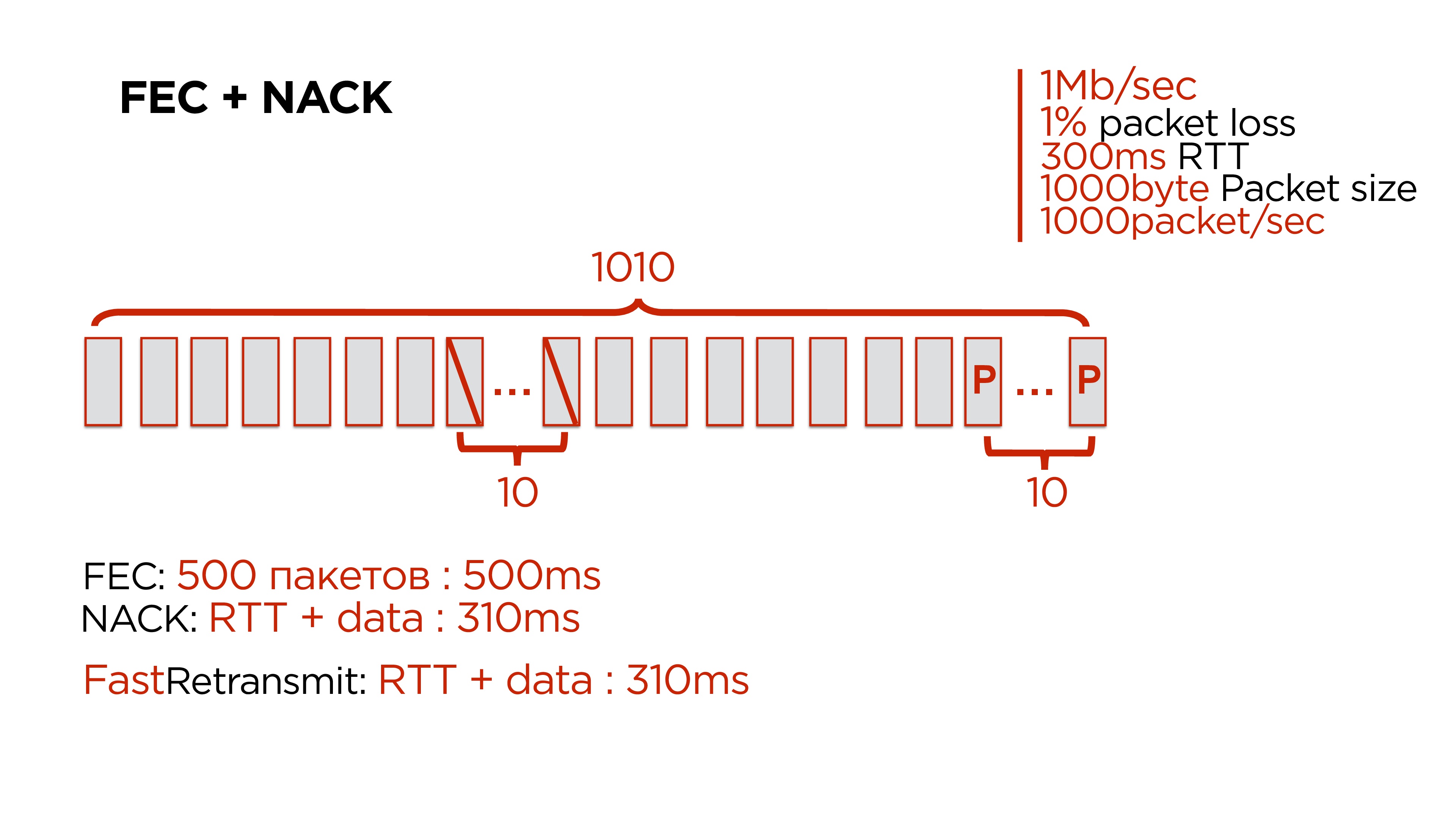
These are numbers close to the average network, so that it is convenient to read:
- 1 Mb / s network;
- 1% packet loss;
- 300 ms RTT;
- 1,000 bytes - size of packets forwarded;
- 1,000 packets per second goes away.
We want to cope with the loss of up to 10 packets at once. Accordingly, with packet loss of 1%, we need to add 10 to 1,000 packets. It is logical - why it is impossible to add 1 to 100 packets - because if we have lost an interval of at least 2 packets, we will not recover.
We are starting to make such additives, and everything seems to be great. And here on the 500th package, we lose that very pack of 10 pieces.We have options:- Wait for the remaining 500 packets and recover data through Forward Error Correction. But we will spend about half a second on this, and the user is waiting for this data.
- You can use NACK, and it is cheaper than waiting for the correction codes.
- And, you can simply take Fast Retransmit, add no correction codes and get the same result.
Therefore, Forward Error Correction really works, but it works on a very narrow range - when the gap is small and this redundant coding can be inserted once every 200-300 packets.Fast retransmit
It works like this: after we have lost a pack of 10 packets, while sending other packets, we understand that we have a retransmit period, and we send these packets again. The most interesting thing is that the retransmit period on such a network will be 350 ms, and the average duration of this packet gap is 25-30 ms, even 100. This means that by the time retransmit starts processing packets, in most cases the network has already recovered and they will leave.It turned out that this thing works better and faster.
The most interesting thing is that the retransmit period on such a network will be 350 ms, and the average duration of this packet gap is 25-30 ms, even 100. This means that by the time retransmit starts processing packets, in most cases the network has already recovered and they will leave.It turned out that this thing works better and faster.Additional options
When you write your protocol over UDP and you have the ability to send packets, you get additional buns.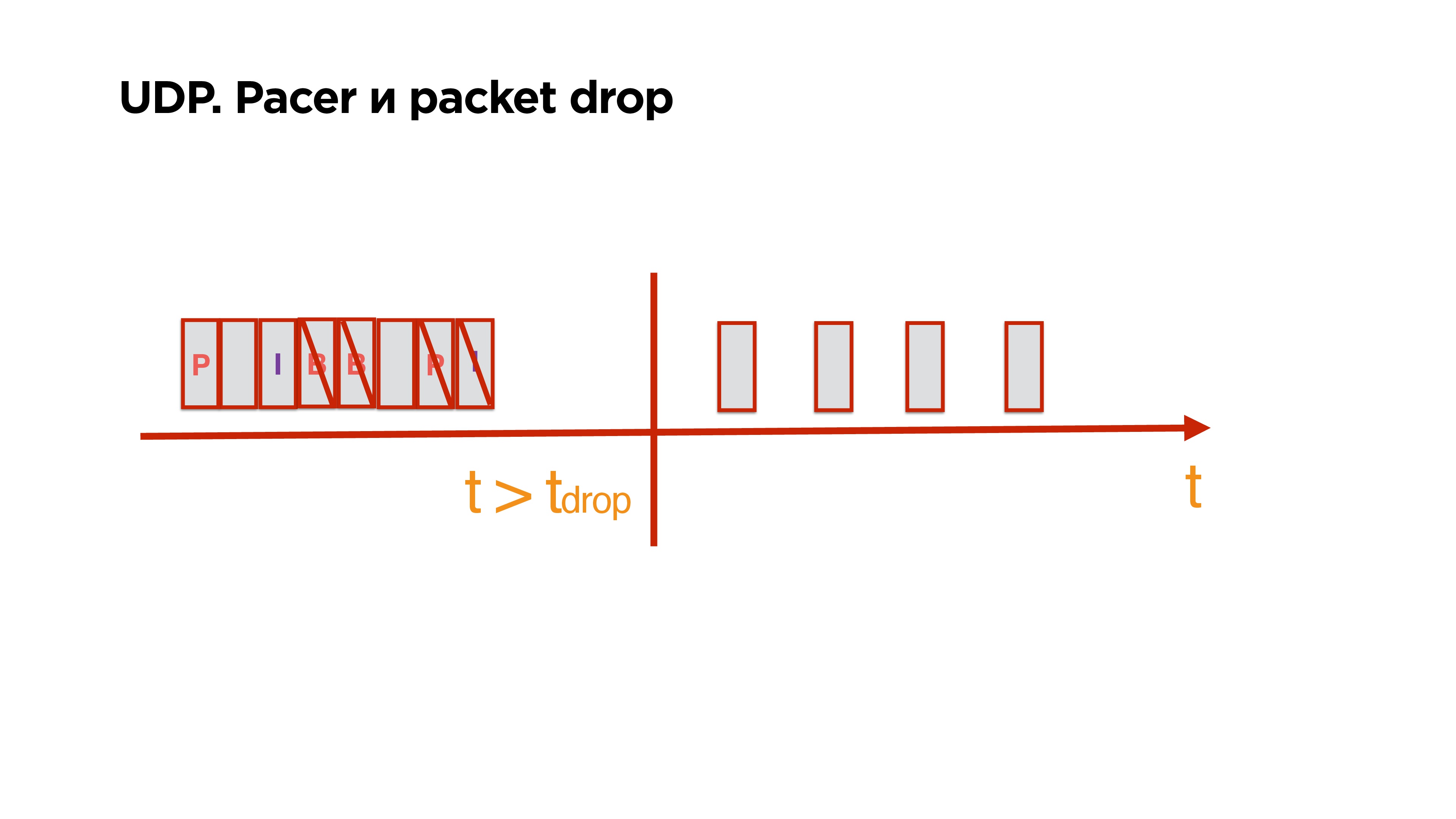 There is a send buffer, there is a reference frame in it, p / b frames to it. They evenly go to the network. Then they stopped going online, and more packages arrived in the queue.You understand that in fact all the packets that lie in the queue are no longer interesting for the client, because, for example, more than 0.5s have passed and you just need to glue the gap on the client and live on.Having the information that you have stored in these packages, you can clean up not only the reference frame, but all the p / b that depend on it, and leave only the necessary and complete data that the client may need later.
There is a send buffer, there is a reference frame in it, p / b frames to it. They evenly go to the network. Then they stopped going online, and more packages arrived in the queue.You understand that in fact all the packets that lie in the queue are no longer interesting for the client, because, for example, more than 0.5s have passed and you just need to glue the gap on the client and live on.Having the information that you have stored in these packages, you can clean up not only the reference frame, but all the p / b that depend on it, and leave only the necessary and complete data that the client may need later.MTU
Since we write the protocol ourselves, we will have to face IP fragmentation. I think many people know about it, but just in case I will tell you briefly.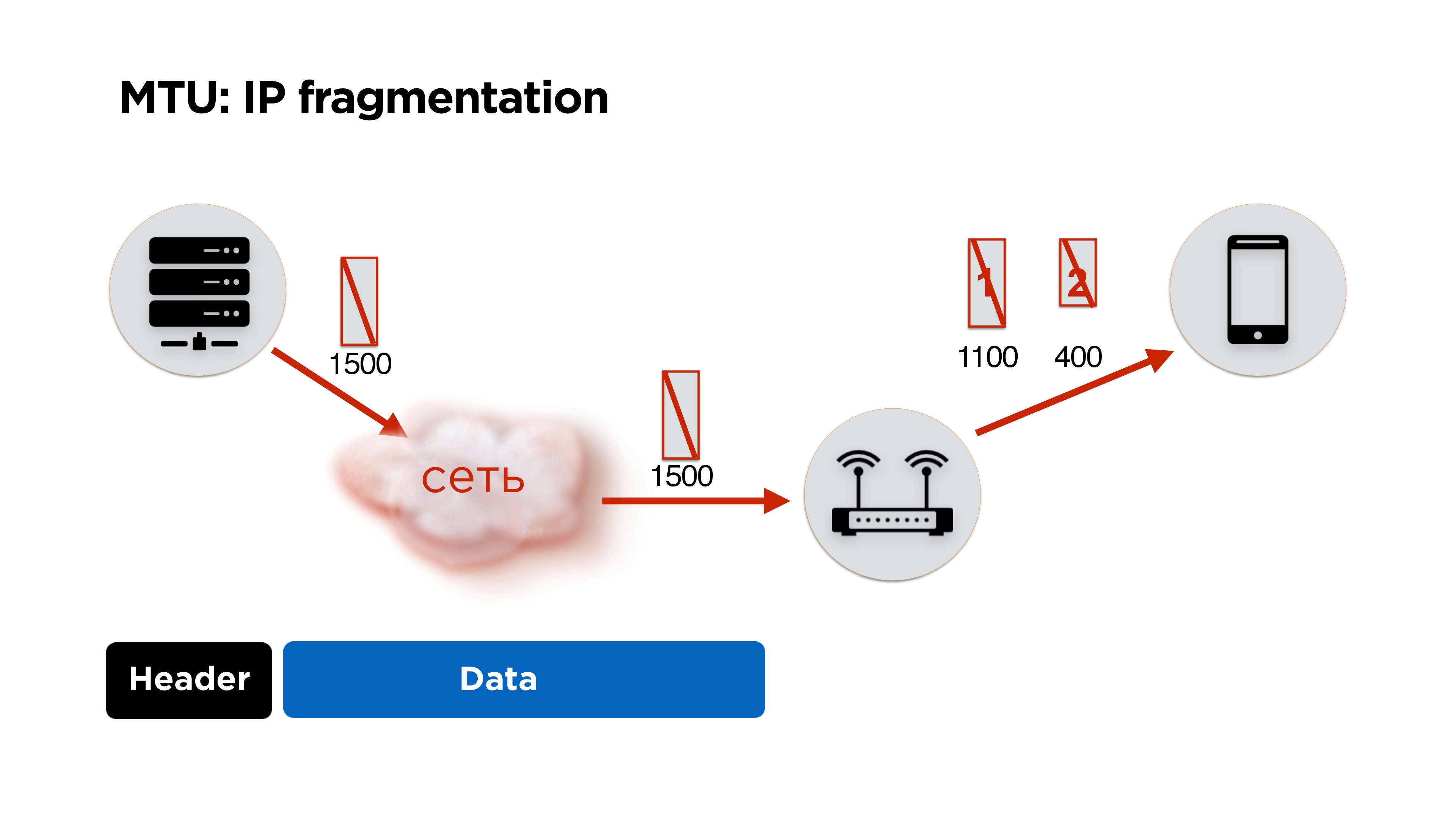 We have a server, it sends some packets to the network, they come to the router and at its level the MTU (maximum transmission unit) becomes lower than the size of the packet that came. It splits the packet into large and small (1100 and 400 bytes here) and sends.In principle, there is no problem, it will all be collected on the client and will work. But if we lose 1 package, we drop all the packages, plus we get additional costs for the package headers. Therefore, if you are writing your own protocol, it is ideal to work in MTU size.How to count it?In fact, Google does not bother, puts about 1200 bytes in its QUIC and does not pick it up, because IP fragmentation will then collect all the packets.
We have a server, it sends some packets to the network, they come to the router and at its level the MTU (maximum transmission unit) becomes lower than the size of the packet that came. It splits the packet into large and small (1100 and 400 bytes here) and sends.In principle, there is no problem, it will all be collected on the client and will work. But if we lose 1 package, we drop all the packages, plus we get additional costs for the package headers. Therefore, if you are writing your own protocol, it is ideal to work in MTU size.How to count it?In fact, Google does not bother, puts about 1200 bytes in its QUIC and does not pick it up, because IP fragmentation will then collect all the packets.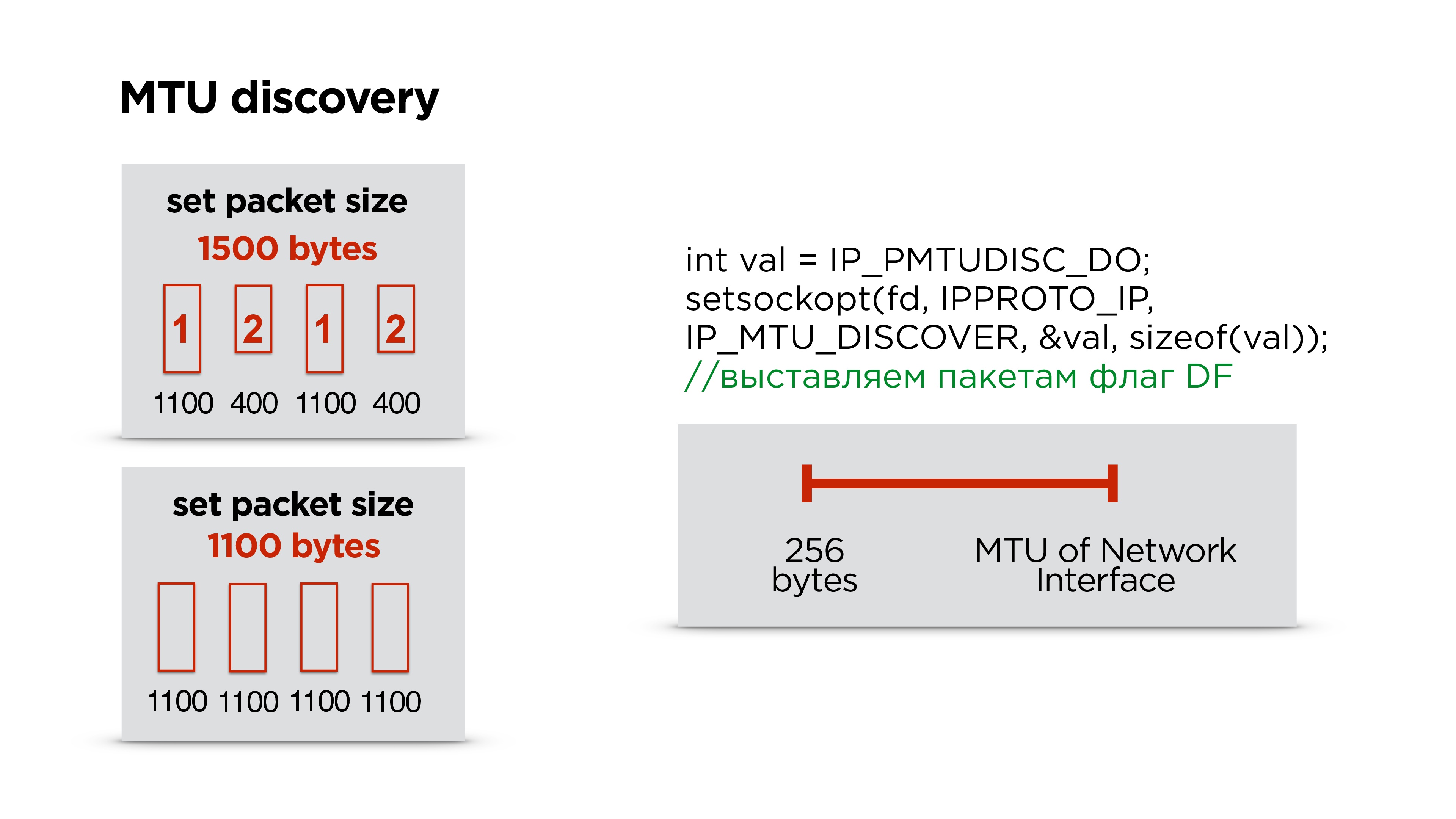 We do exactly the same - first we put some default size and start sending packets - let it fragment them.In parallel, we launch a separate thread and create a socket with the flag of the prohibition of fragmentation for all packages. If the router encounters such a packet and cannot fragment this data, then it will drop the packet and it is possible that ICMP will send you that there are problems, but most likely ICMP will be closed and this will not happen. Therefore, we simply, for example, three times try to send a packet of a certain size at some interval. If it does not reach, we consider that the MTU is exceeded and further decrease it.Thus, having the MTU of the Internet interface, which is on the device, and some minimum MTU, we simply select the correct MTU with a one-dimensional search. After that, we adjust the packet size in the protocol.In fact, it sometimes changes. We were surprised, but in the process of switching Wi-Fi, etc. MTU is changing. It’s better not to stop this parallel process and to correct the MTU from time to time.
We do exactly the same - first we put some default size and start sending packets - let it fragment them.In parallel, we launch a separate thread and create a socket with the flag of the prohibition of fragmentation for all packages. If the router encounters such a packet and cannot fragment this data, then it will drop the packet and it is possible that ICMP will send you that there are problems, but most likely ICMP will be closed and this will not happen. Therefore, we simply, for example, three times try to send a packet of a certain size at some interval. If it does not reach, we consider that the MTU is exceeded and further decrease it.Thus, having the MTU of the Internet interface, which is on the device, and some minimum MTU, we simply select the correct MTU with a one-dimensional search. After that, we adjust the packet size in the protocol.In fact, it sometimes changes. We were surprised, but in the process of switching Wi-Fi, etc. MTU is changing. It’s better not to stop this parallel process and to correct the MTU from time to time.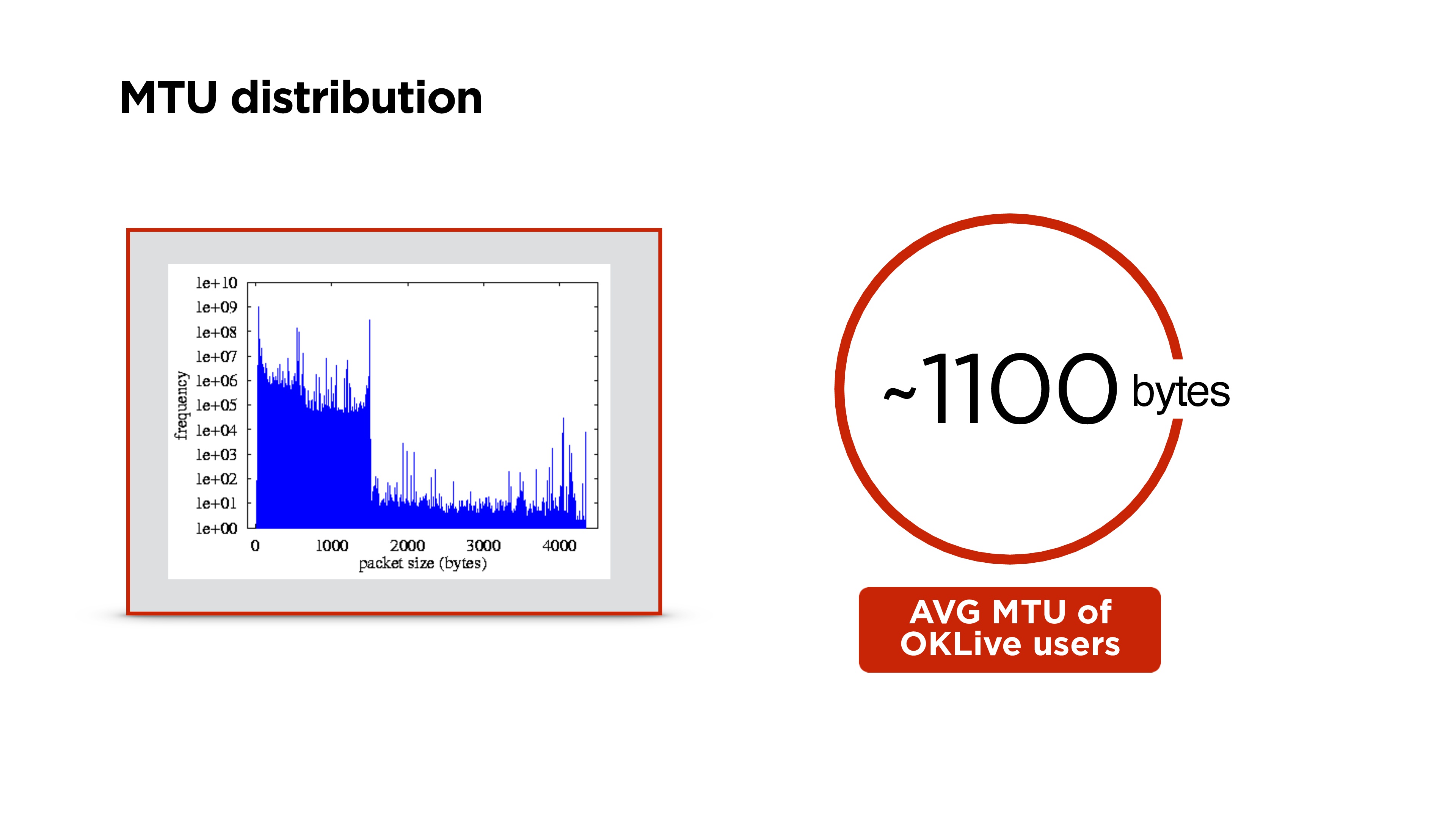 Higher MTU distribution in the world. We got about 1100 bytes on the portal.
Higher MTU distribution in the world. We got about 1100 bytes on the portal.Encryption
We said that we want to optionally manage encryption. We make the easiest option - Diffie-Hellman on elliptic curves. We make it optional - we encrypt only control packets and headers so that man-in-the-middle could not get the translation key, intercept and so on.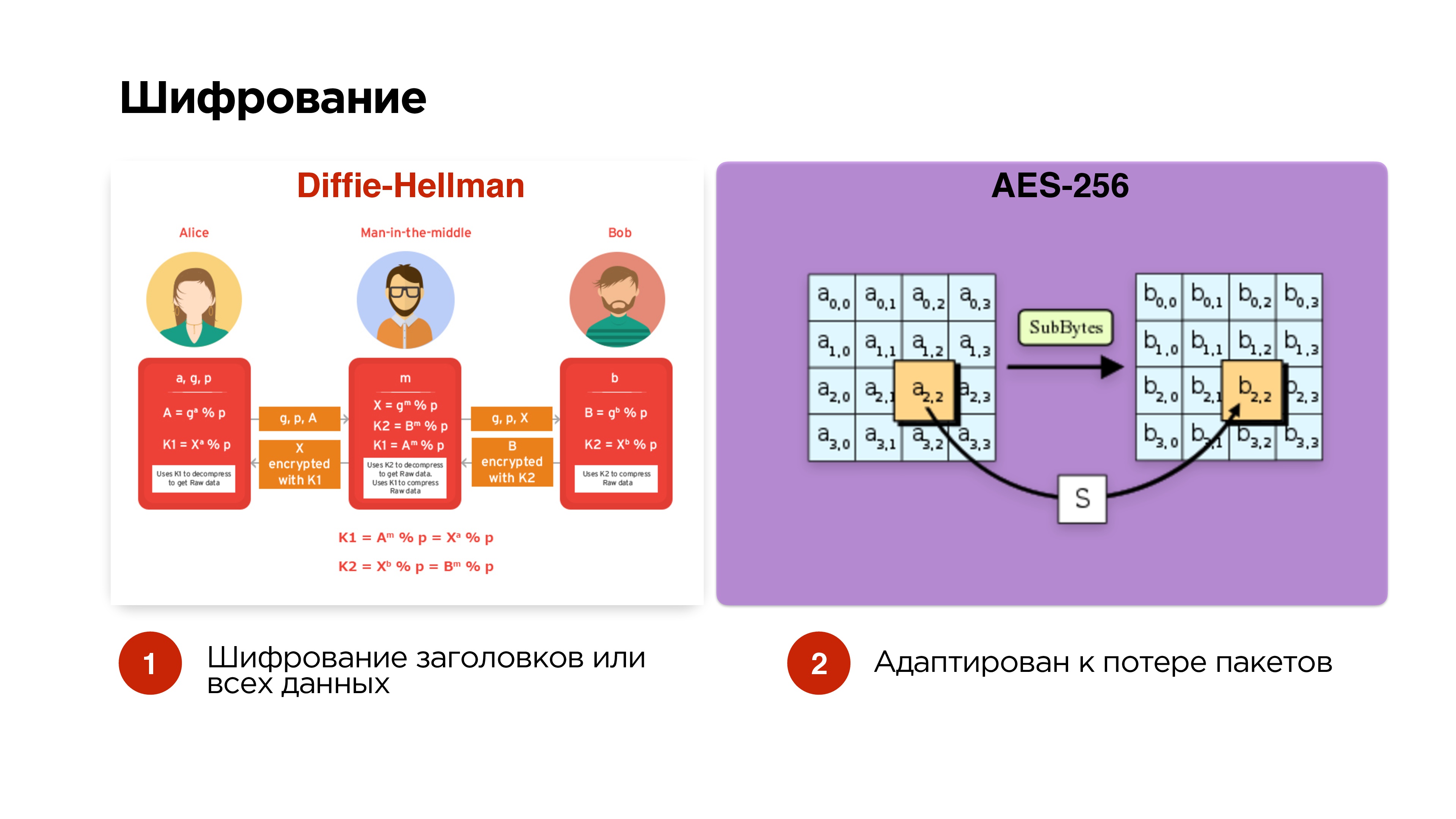 If the broadcast is private, then we can also add encryption of all data.We encrypt AES-256 packets independently, so that packet drop does not affect the further encryption of packets.
If the broadcast is private, then we can also add encryption of all data.We encrypt AES-256 packets independently, so that packet drop does not affect the further encryption of packets.Prioritization
Remember, we wanted the protocol to still be prioritized.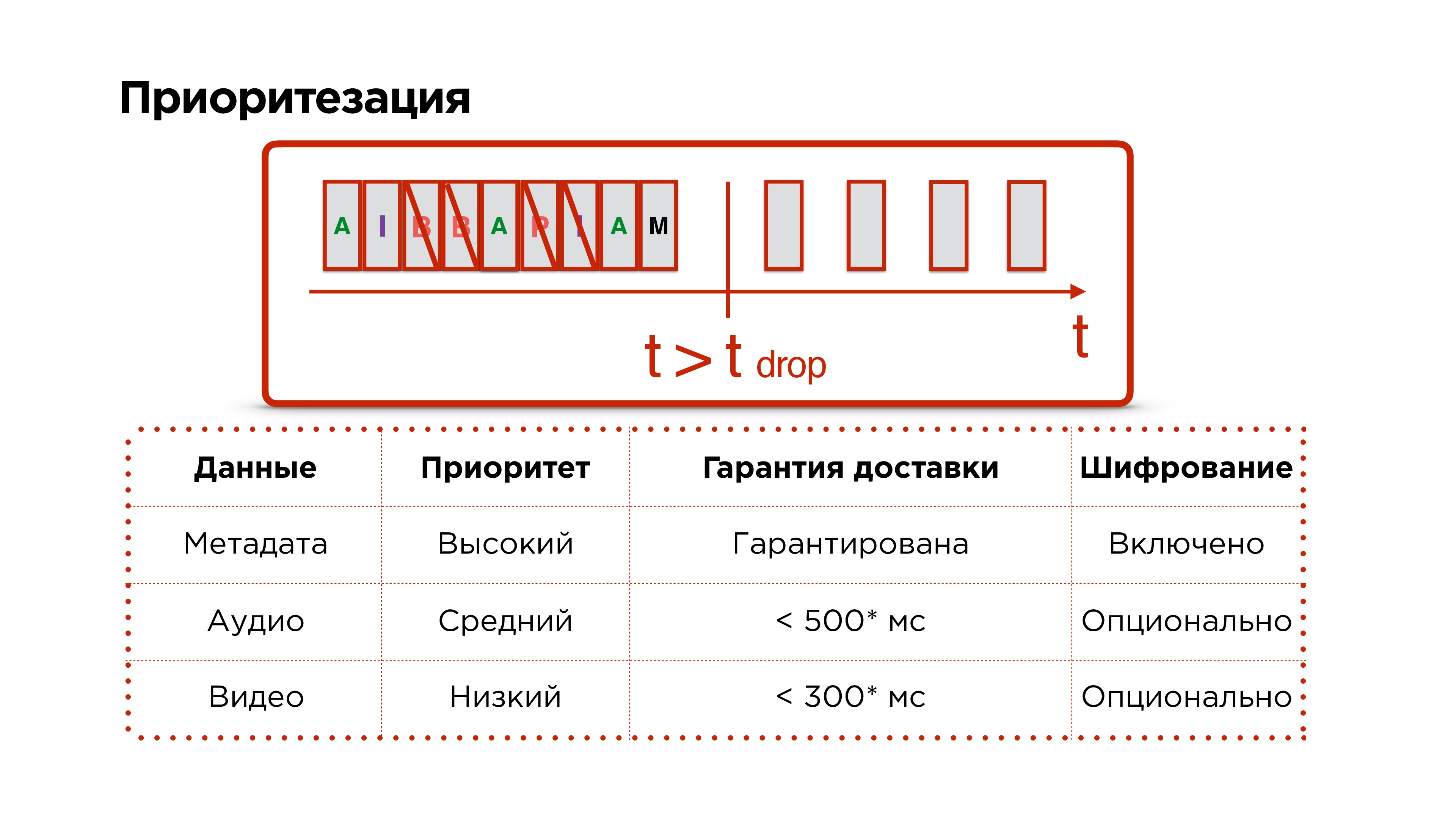 We have metadata, audio and video frames, we successfully send them to the network. Then our network burns down in hell and does not work for a long time - we understand that we need to drop packages.We give priority to dropping video packets, then we try to drop audio and never touch the control packets, because data such as resolution changes and other important issues can go along with them.
We have metadata, audio and video frames, we successfully send them to the network. Then our network burns down in hell and does not work for a long time - we understand that we need to drop packages.We give priority to dropping video packets, then we try to drop audio and never touch the control packets, because data such as resolution changes and other important issues can go along with them.Additional bun about UDP
If you write your UDP protocol, for example, with two-way communication, you need to understand that there is NAT Unbinding and the chance that you will not be able to return from the server to find the client.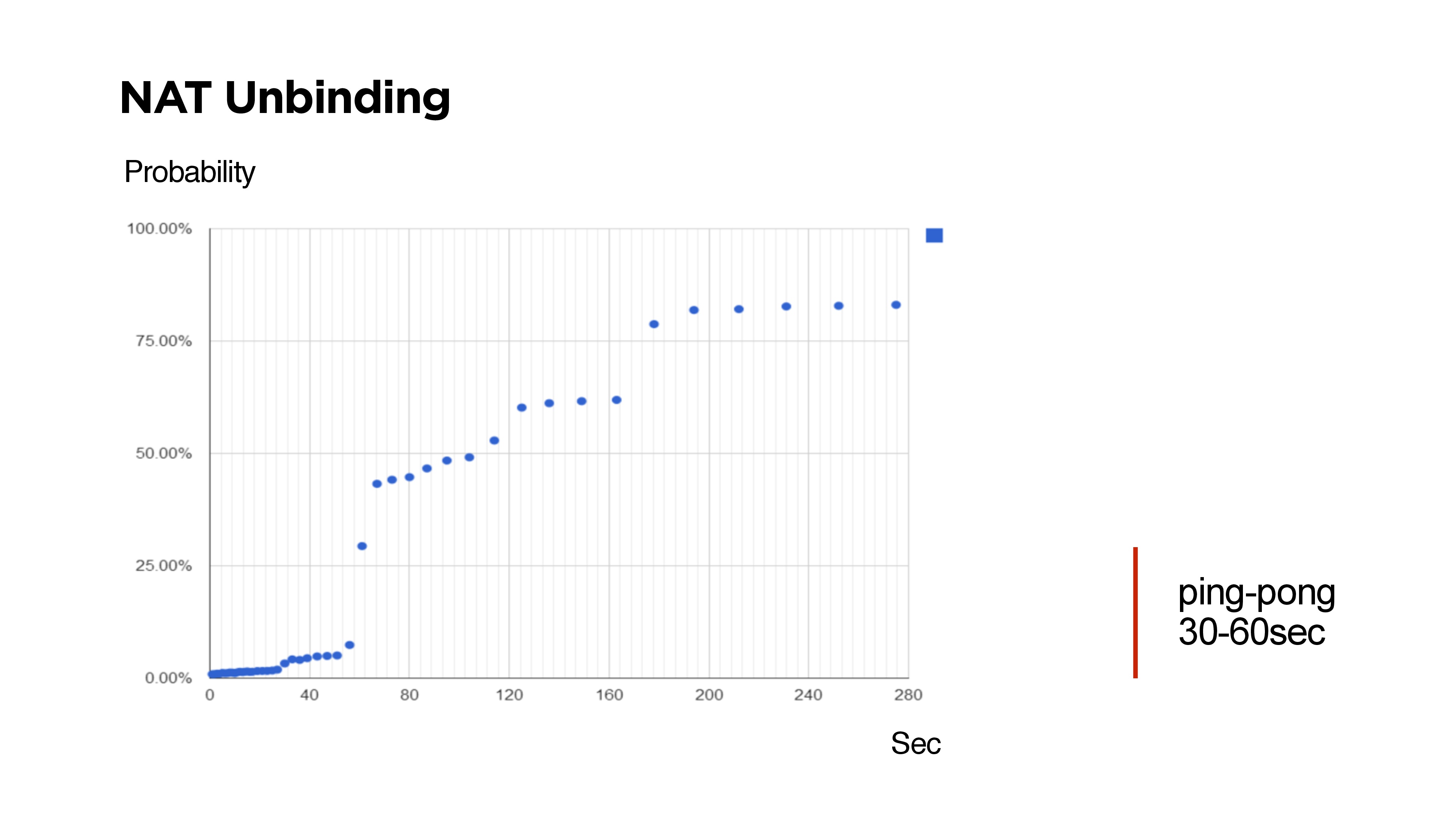 On the slide there are times when it was not possible to reach the client from the server via UDP.Many skeptics say that routers are designed in such a way that NAT Unbinding replaces primarily UDP routes. But the above shows that if Keep-Alive or ping is less than 30 seconds, then with a probability of 99% it will be possible to reach the client.
On the slide there are times when it was not possible to reach the client from the server via UDP.Many skeptics say that routers are designed in such a way that NAT Unbinding replaces primarily UDP routes. But the above shows that if Keep-Alive or ping is less than 30 seconds, then with a probability of 99% it will be possible to reach the client.UDP availability on mobile devices in the world
 Google says that 6%, but it turned out that 7% of mobile users cannot use UDP . In this case, we leave our beautiful protocol with prioritization, encryption, and everything, only on TCP.VOIP on WebRTC, Google QUIC, and many games work on UDP now work on UDP. Therefore, to believe that UDP on mobile devices will be closed, I would not.As a result, we:
Google says that 6%, but it turned out that 7% of mobile users cannot use UDP . In this case, we leave our beautiful protocol with prioritization, encryption, and everything, only on TCP.VOIP on WebRTC, Google QUIC, and many games work on UDP now work on UDP. Therefore, to believe that UDP on mobile devices will be closed, I would not.As a result, we:- Reduced the delay between the streamer and the viewer to 1 s.
- We got rid of the cumulative effect in buffers, that is, the broadcast is not lagging behind.
- The number of stalls in the audience has decreased .
- We were able to support FullHD streaming on mobile devices.

- The delay in our OK Live mobile app is 25 ms - 10 ms longer than the camera scanner works, but it's not that bad.
- Broadcast on the Web shows a delay of only 690 ms - space!
What else can streaming on Odnoklassniki
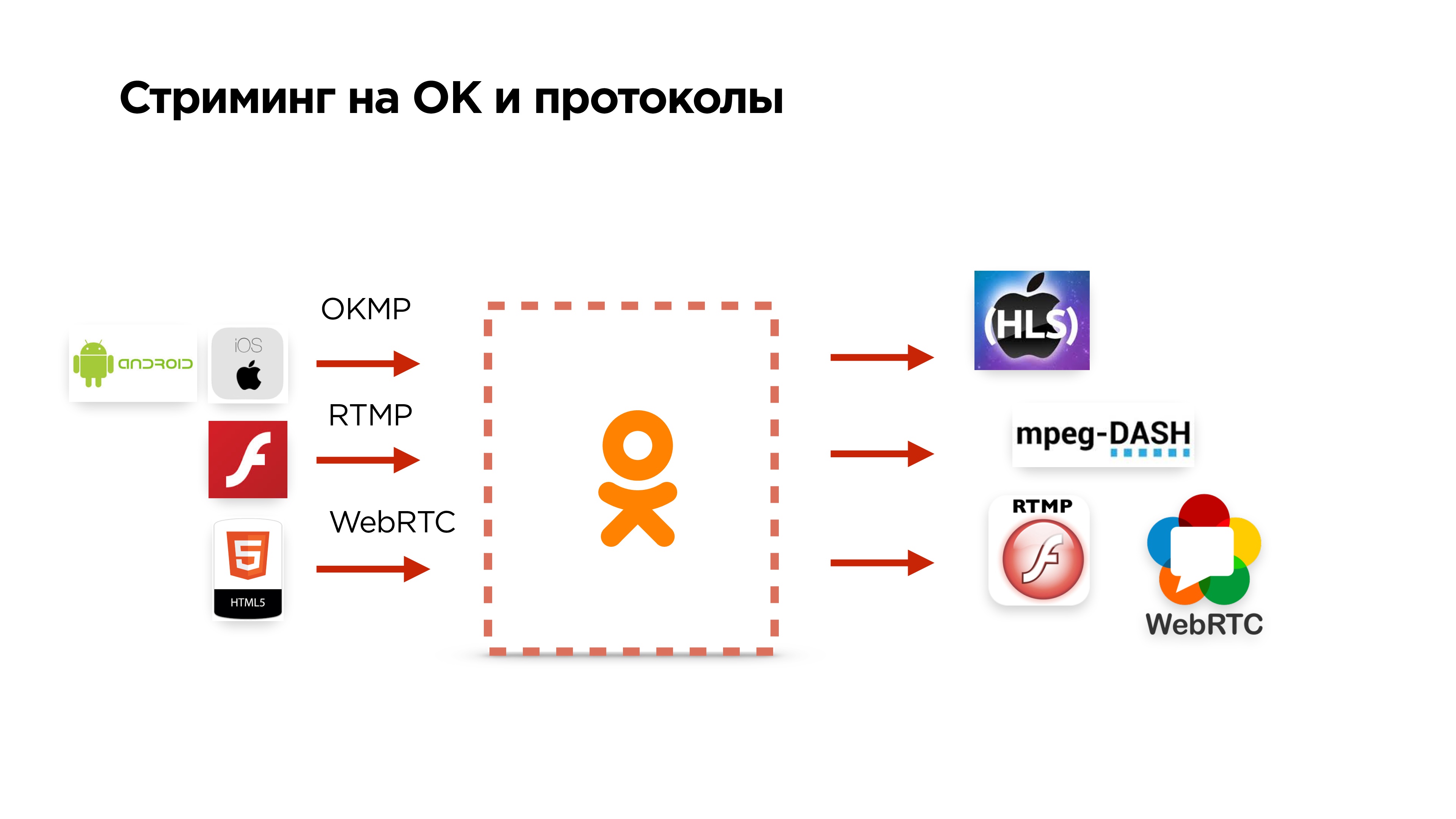
- Accepts our OKMP protocol from mobile devices;
- can accept RTMP and WebRTC;
- gives out HLS, MPEG-Dash, etc.
If you were attentive, you noticed that I said that we can take from the user, for example, WebRTC and convert it to RTMP. There is a nuance. In fact, WebRTC is a packet-oriented protocol and uses the OPUS audio codec. You cannot use OPUS in RTMP.On the backend servers we use RTMP everywhere. Therefore, we had to make some more fixes in FF MPEG, which allows us to push OPUS into RTMP, convert it to AAC and give it to users already in HLS or something else.
There is a nuance. In fact, WebRTC is a packet-oriented protocol and uses the OPUS audio codec. You cannot use OPUS in RTMP.On the backend servers we use RTMP everywhere. Therefore, we had to make some more fixes in FF MPEG, which allows us to push OPUS into RTMP, convert it to AAC and give it to users already in HLS or something else.What does this look like inside us?
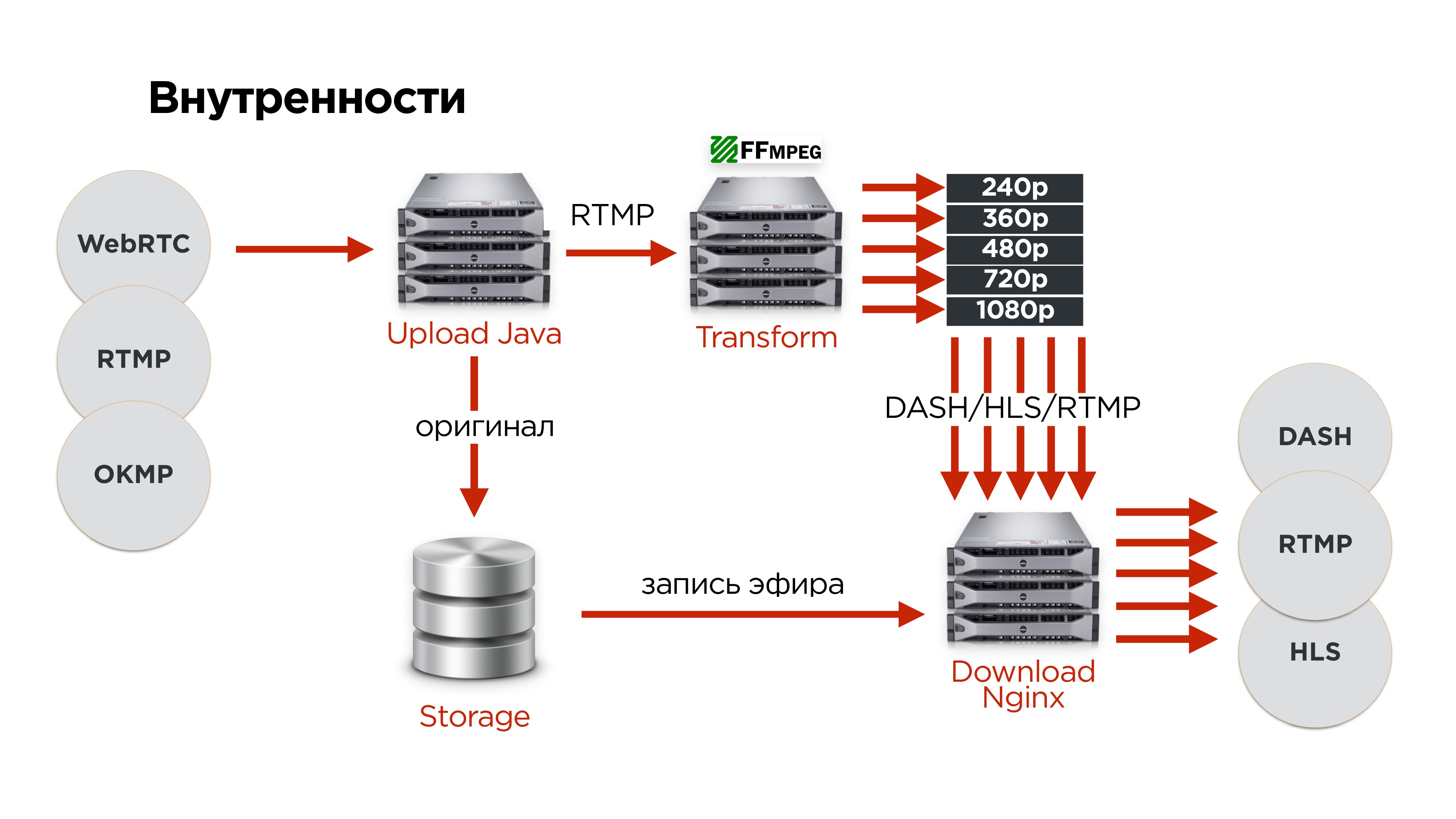
- Users on one of the protocols upload the original video to our upload servers.
- There we expand the protocol.
- By RTMP we send to one of the video transformation servers.
- The original is always saved in the distributed storage so that nothing is lost.
- After that, all videos are sent to the distribution server.
We got the following on hardware: I'll tell you a little more about fault tolerance:
I'll tell you a little more about fault tolerance:- Upload servers are distributed across different data centers and stand behind different IPs.
- Users come by DNS receive IP.
- The upload server sends the video to the slicing servers, they cut and give to the distribution servers.
- For more popular broadcasts, we are starting to add more distribution servers.
- All that came from the user, we save in storage, then to create an archive of broadcasts and nothing to lose.
- The storage is fault tolerant, distributed over three data centers.
To determine which server is currently responsible for the broadcast, we use ZooKeeper . For each broadcast, we store the node and make ephemeral nodes for each server. In fact, this is such a thing that allows for stream to create a queue of servers that will process. Always the current leader in this line is processing the stream.Test failover will be in a hurry. Let's start immediately with the disappearance of the entire data center.What happens?- The user on DNS will take the next IP of another upload server.
- By this time, ZooKeeper will understand that the server in that data center has died, and will choose another cutting server for it.
- Download-servers will find out who is now responsible for the transformation of this stream and will distribute it.
In principle, all this will happen with minimal delays.Using the protocol in the product
We made a mobile application for streaming OK Live. It is fully integrated with the portal. Users can communicate there, conduct live broadcasts, there is a map of ethers, a list of popular ethers - in general, everything you can want. We also added the ability to conduct ethers in FullHD. You can connect an action-camera on Android to an Android device.
We also added the ability to conduct ethers in FullHD. You can connect an action-camera on Android to an Android device. Now we have a mechanism that allows live broadcasts. For example, we conducted a direct line with the President through OK Live and broadcast it to the whole country . Users watched and through the counter stream could get on the air and ask their questions.That is, in fact, two opposite streams at the minimum delay provide a certain format of a public conference call.In fact, we missed somewhere in 2 seconds - a second there and a second back. Remember that “trolley bus”, about which I spoke at the beginning of the article - it now looks like 2 huge trucks. For TV broadcast, remove it from the camera and just mix everything up with a delay of about 1-2 seconds, which is perfectly normal.In fact, we managed to reproduce something comparable with current modern TCPs.
Now we have a mechanism that allows live broadcasts. For example, we conducted a direct line with the President through OK Live and broadcast it to the whole country . Users watched and through the counter stream could get on the air and ask their questions.That is, in fact, two opposite streams at the minimum delay provide a certain format of a public conference call.In fact, we missed somewhere in 2 seconds - a second there and a second back. Remember that “trolley bus”, about which I spoke at the beginning of the article - it now looks like 2 huge trucks. For TV broadcast, remove it from the camera and just mix everything up with a delay of about 1-2 seconds, which is perfectly normal.In fact, we managed to reproduce something comparable with current modern TCPs. Live shows are the current trend. Over the past year and a half on the OK portal, they have grown threefold (not without the help of the OK Live application).
Live shows are the current trend. Over the past year and a half on the OK portal, they have grown threefold (not without the help of the OK Live application). All broadcasts are recorded by default. We have about 50 thousand streams per day, this generates about 17 terabytes of traffic per day, but in general all the video on the portal generates about a petabyte of data per month.
All broadcasts are recorded by default. We have about 50 thousand streams per day, this generates about 17 terabytes of traffic per day, but in general all the video on the portal generates about a petabyte of data per month. What we got:
What we got:- We were able to guarantee the duration of the delay between the streamer and the audience.
- We made the first mobile FullHD streaming application on a dynamically changing mobile Internet channel.
- Got the opportunity to lose data centers and not interrupt the broadcast.
What have you learned:- What is video and how to stream it.
- What can you write your UDP protocol if you know for sure that you have a very specific task and specific users.
- About the architecture of any streaming service - video enters the input, is converted, and exits.
At Highload ++ Siberia, Alexander Tobol promises to tell you about the service of calls to OK, it will be interesting to know what we have managed to apply from what we reviewed in this article, and what had to be implemented completely anew.
In the same section, reports on specific topics are planned:
- Evgenia Rossinsky (ivi) on a system for collecting detailed statistics on the operation of CDN nodes.
- Anton Rusakov (Badoo) on the integration of payment systems without using their own billing.