The
Antiplagiat system is a specialized search engine. As befits a search engine, with its own engine and search indexes. Our largest index by the number of sources is, of course, the Russian-language Internet. For a long time, we decided that we would put in this index everything that is text (not a picture, music or video), written in Russian, has a size greater than 1 kb and is not an “almost duplicate” of something that already there in the index.
Such an approach is good in that it does not require complex pre-processing and minimizes the risks of “throwing out the baby with water” - skipping a document from which the text can potentially be borrowed. On the other hand, as a result, we know little about which documents are in the end in the index.
As the Internet index grows - and now, for a second, it’s already more than 300 million documents
only in Russian - a completely natural question arises: are there really a lot of really useful documents in this dump?
And since we (
yury_chekhovich and
Andrey_Khazov ) were engaged in such a reflection, then why should we not answer a few more questions at the same time. How many scientific documents are indexed, and how many are unscientific? What is the share of scientific articles occupied by diplomas, articles, abstracts? What is the distribution of documents by topic?

Since we are talking about hundreds of millions of documents, it is necessary to use automatic data analysis tools, in particular, machine learning technology. Of course, in most cases, the quality of expert evaluation exceeds machine methods, but to attract human resources to solve such an extensive task would be too expensive.
So, we need to solve two problems:
- Create a filter of "scientific", which, on the one hand, allows you to discard not automatically the documents that are structured and content, and on the other hand determines the type of scientific document. Immediately make a reservation that the "scientific" in no way refers to the scientific significance or reliability of the results. The task of the filter is to separate documents that have the form of a scientific article, dissertation, diploma, etc. from other types of texts, namely fiction, publicistic articles, news notes, etc .;
- Implement a means of categorizing scientific documents that relates the document to one of the scientific specialties (for example, Physics and Mathematics , Economics , Architecture , Cultural Studies , etc.).
At the same time, we need to solve these tasks, working exclusively with the text substrate of documents, without using their metadata, information about the arrangement of text blocks and images inside documents.
Let's explain with an example. Even a quick glance is enough to distinguish a
scientific article.
from, for example, a
children's fairy tale .

But if there is only a text layer (for the same examples), you have to read the content.
Filter "scientific" and sorting by type
We solve problems sequentially:
- At the first stage we filter out unscientific documents;
- At the second stage, all documents that have been identified as scientific are classified by type: article, PhD thesis, doctoral dissertation, diploma, etc.
It looks like this:
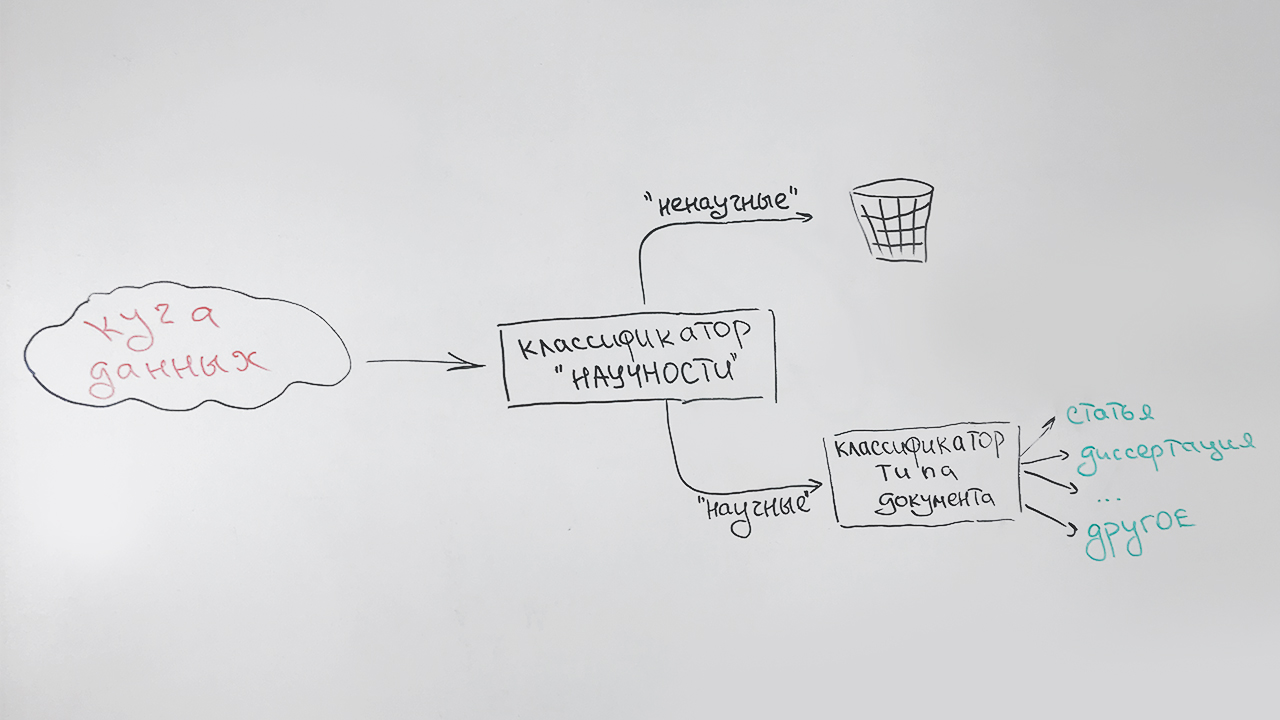
A special type (indefinite) is assigned to documents that cannot be categorized with any particular type (mainly short documents - pages of scientific sites, abstracts of abstracts). For example, this publication will be referred to this type, which has some signs of scientific knowledge, but is not similar to any of the above.
There is one more circumstance that needs to be taken into account. This is a high speed of the algorithm and undemanding of resources - after all, our task is of an auxiliary nature. Therefore, we use a very small characteristic description of the documents:
- average sentence length in the text;
- the proportion of stop words in relation to all words of the text;
- readability index ;
- the proportion of punctuation in relation to all characters of the text;
- the number of words from the list ("abstract", "dissertation", "thesis", "certification", "specialty", "monograph", etc.) in the initial part of the text (the sign is responsible for the title page);
- the number of words from the list ("list", "literature", "bibliographic", etc.) in the last part of the text (the sign is responsible for the list of references);
- the proportion of letters in the text;
- average word length;
- the number of unique words in the text.
All these signs are good because they are quickly calculated. As a classifier, we use the random forest algorithm (
Random forest ) - a classification method popular in machine learning.
With quality assessments in the absence of a sample marked up by experts, it is difficult, therefore, we start the classifier on the collection of articles by the scientific electronic library
Elibrary.ru . We assume that all articles will be defined as scientific.
The result is 100%? Nothing of the kind - only 70%. Maybe we created a bad algorithm? Browse the filtered articles. It turns out that scientific journals publish many unscientific texts: editorials, jubilee greetings, obituaries, recipes and even horoscopes. Selective viewing of articles that the classifier considered scientific does not reveal errors, therefore we recognize the classifier as valid.
Now we undertake the second task. Here, without quality material for learning is not enough. We ask assessors to prepare a sample. We get a little more than 3.5 thousand documents with this distribution:
| Document type | Number of documents in the sample |
|---|
| Articles | 679 |
| PhD dissertations | 250 |
| Abstracts of PhD theses | 714 |
| Collections of scientific conferences | 75 |
| Doctoral dissertations | 159 |
| Abstracts of doctoral theses | 189 |
| Monographs | 107 |
| Tutorials | 403 |
| Thesis | 664 |
| Undefined type | 514 |
To solve the problem of multi-class classification, we use the same Random forest and the same signs in order not to calculate something special.
We get the following quality classification:
| Accuracy | Completeness | F-measure |
|---|
| 81% | 76% | 79% |
The results of applying the trained algorithm to the indexed data are visible in the diagrams below. Figure 1 shows that more than half of the collection consists of scientific documents, and among them, in turn, more than half of the documents are articles.
 Fig. 1. The distribution of documents on the "scientific"
Fig. 1. The distribution of documents on the "scientific"Figure 2 shows the distribution of scientific documents by type, with the exception of the “article” type. It can be seen that the second most popular type of scientific document is a textbook, and the rarest type is a doctoral dissertation.
 Fig. 2. Distribution of other scientific documents by type
Fig. 2. Distribution of other scientific documents by typeIn general, the results are in line with expectations. From the fast "rough" classifier, we no longer need.
Determining the subject of the document
It so happened that a single generally accepted classifier of scientific works has not yet been created. The most popular today are the
HAC ,
STI , and
UDC rubricators. We decided to just in case thematically classify documents for each of these categories.
To build a thematic classifier, we use an approach based on thematic modeling (
topic modeling ) - a statistical method for constructing a model of a collection of text documents, in which for each document its probability of belonging to certain topics is determined. As a tool for building a thematic model, we use the
BigARTM open library. We have already used this library before and we know that it is great for thematic modeling of large collections of text documents.
However, there is one difficulty. In thematic modeling, determining the composition and structure of topics is the result of solving an optimization problem with respect to a specific collection of documents. We cannot influence them directly. Naturally, the themes that you get when tuning up for our collection will not match any of the target classifiers.
Therefore, in order to get the final unknown value of the rubricator of a specific query document, we need to perform another transformation. To do this, in the BigARTM theme space, we use the nearest neighbor algorithm (
k-NN ) to search for some of the most similar documents to the request with known rubricator values, and, on this basis, assign the most relevant class to the request document.
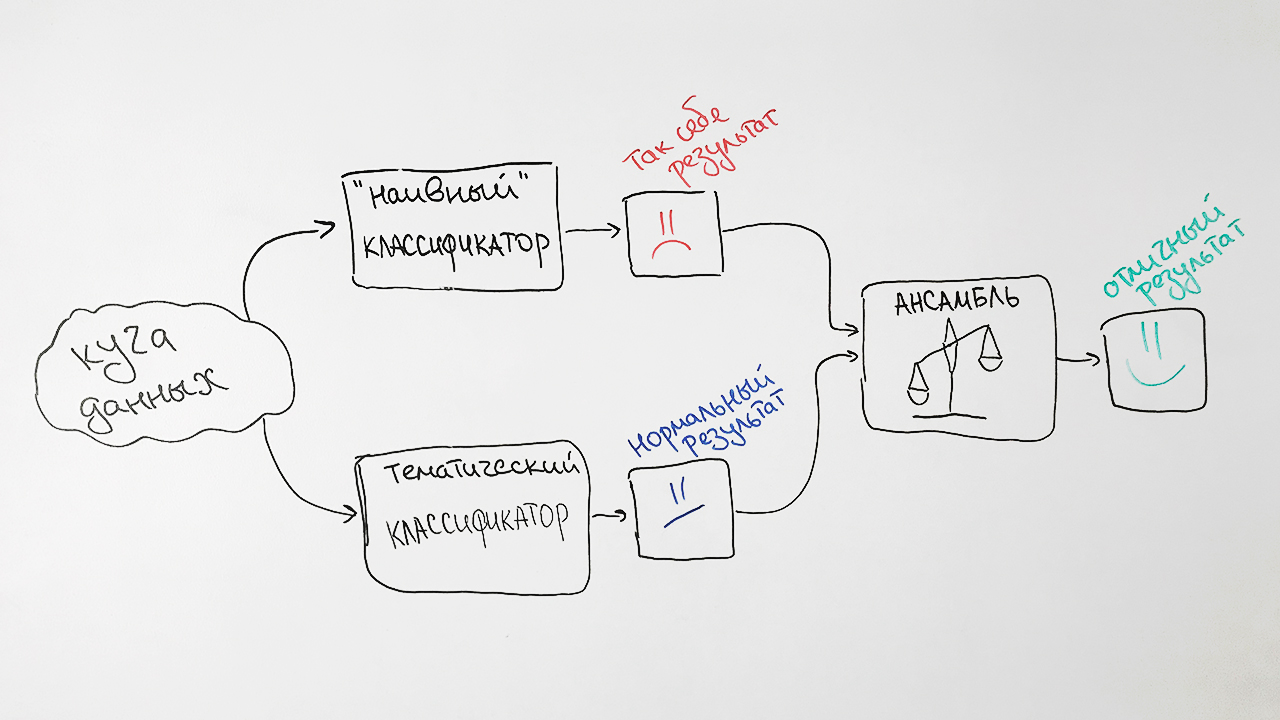
In a simplified form, the algorithm is shown in the figure:

For training the model, we use documents from open sources, as well as data provided by Elibrary.ru with well-known specialties VAK, GRNTI, UDC. We remove from the collection documents that are tied to very common positions of rubricators, for example,
General and complex problems of the natural and exact sciences , since such documents will noisy the final classification.
The final collection contained about 280 thousand documents for training and 6 thousand documents for testing for each of the rubricators.
For our purposes, it is enough for us to predict the values of the first level rubrics. For example, for a text with a value of GRNTI
27.27.24: Harmonic functions and their generalizations, the prediction of rubric
27: Mathematics is correct.
To improve the quality of the developed algorithm, we add to it a pair of approaches based on the good old
Naive Bayes classifier. As signs, it uses the frequencies of words most characteristic of each of the documents with a specific value of the HAC rubricator.
Why so hard? As a result, we take the predictions of both algorithms, we weigh them and give the average prediction for each query. This technique in machine learning is called
ensembling . This approach ultimately gives us a noticeable increase in quality. For example, for the GRNTI specification, the accuracy of the original algorithm was 73%, the accuracy of the naive Bayes classifier — 65%, and their combinations — 77%.
The result is this scheme of our classifier:
Note two factors that affect the results of the classifier. First, any document can be simultaneously assigned more than one rubricator value. For example, the values of the rubricator VAK 25.00.24 and 08.00.14 (
Economic ,
social and political geography and the
world economy ). And it will not be a mistake.
Secondly, in practice, the values of rubricators are placed expertly, that is, subjectively. A vivid example is such seemingly dissimilar topics as
Mechanical Engineering and
Agriculture and Forestry . Our algorithm referred to the articles with the names
“Machines for thinning of forest care” and
“Prerequisites for the development of a standard-size tractor range for the conditions of the north-western zone” to mechanical engineering, and according to the original marking, they belonged
specifically to agriculture.
Therefore, we decided to display the top 3 most likely values for each of the rubricators. For example, for the article
“Professional tolerance of a teacher (on the example of the activity of a teacher of Russian in a polyethnic school)”, the probabilities of the values of the HAC rubricator were as follows:
| Value rubricator | Probability |
|---|
| Pedagogical sciences | 47% |
| Psychological sciences | 33% |
| Culturology | 20% |
The accuracy of the final algorithms was:
| Rubricator | Accuracy on top 3 |
|---|
| GRNTI | 93% |
| HAC | 92% |
| UDC | 94% |
The diagrams present the results of a study on the distribution of subjects of documents in the Russian-language Internet index for all (Figure 3) and only for scientific (Figure 4) documents. It can be seen that most of the documents are related to the humanities: the most frequent specifications are economics, jurisprudence and pedagogy. Moreover, among only scientific documents their share is even greater.
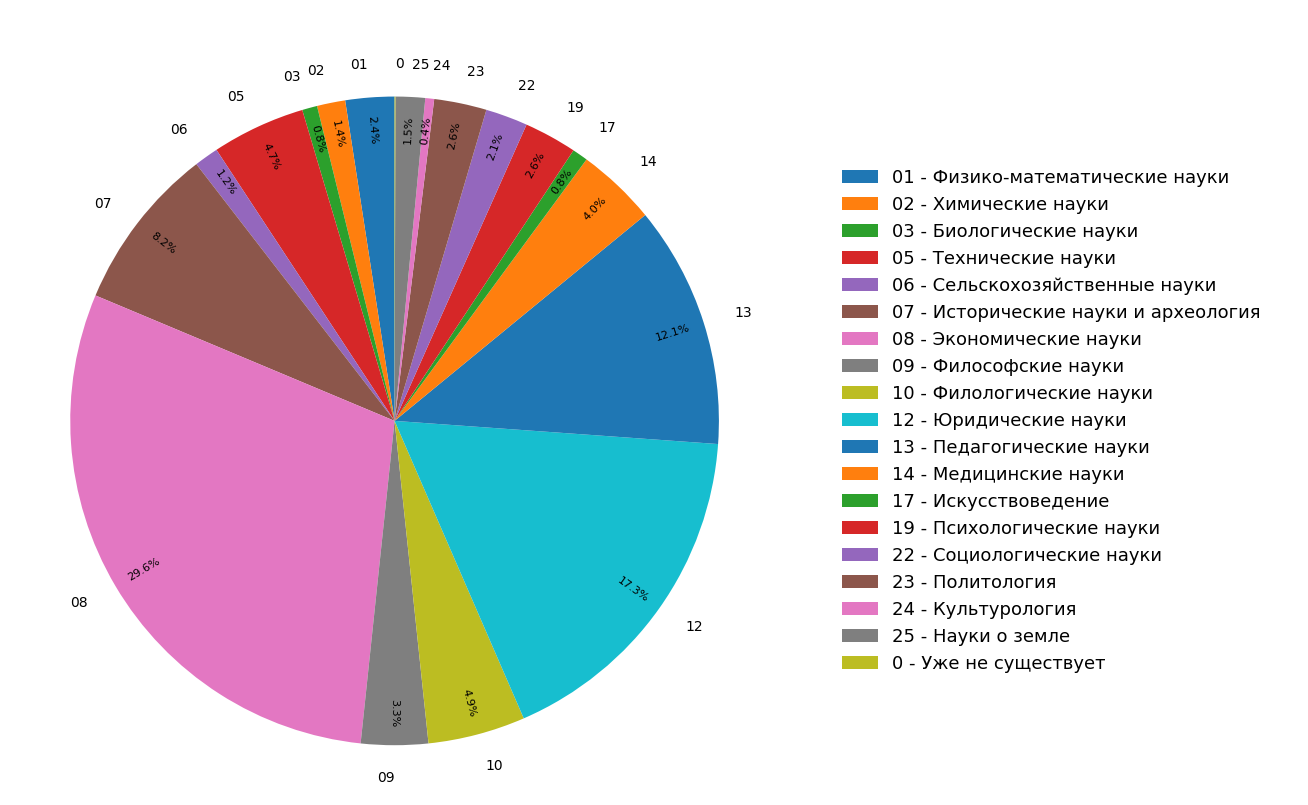 Fig. 3. The distribution of topics across the search module
Fig. 3. The distribution of topics across the search module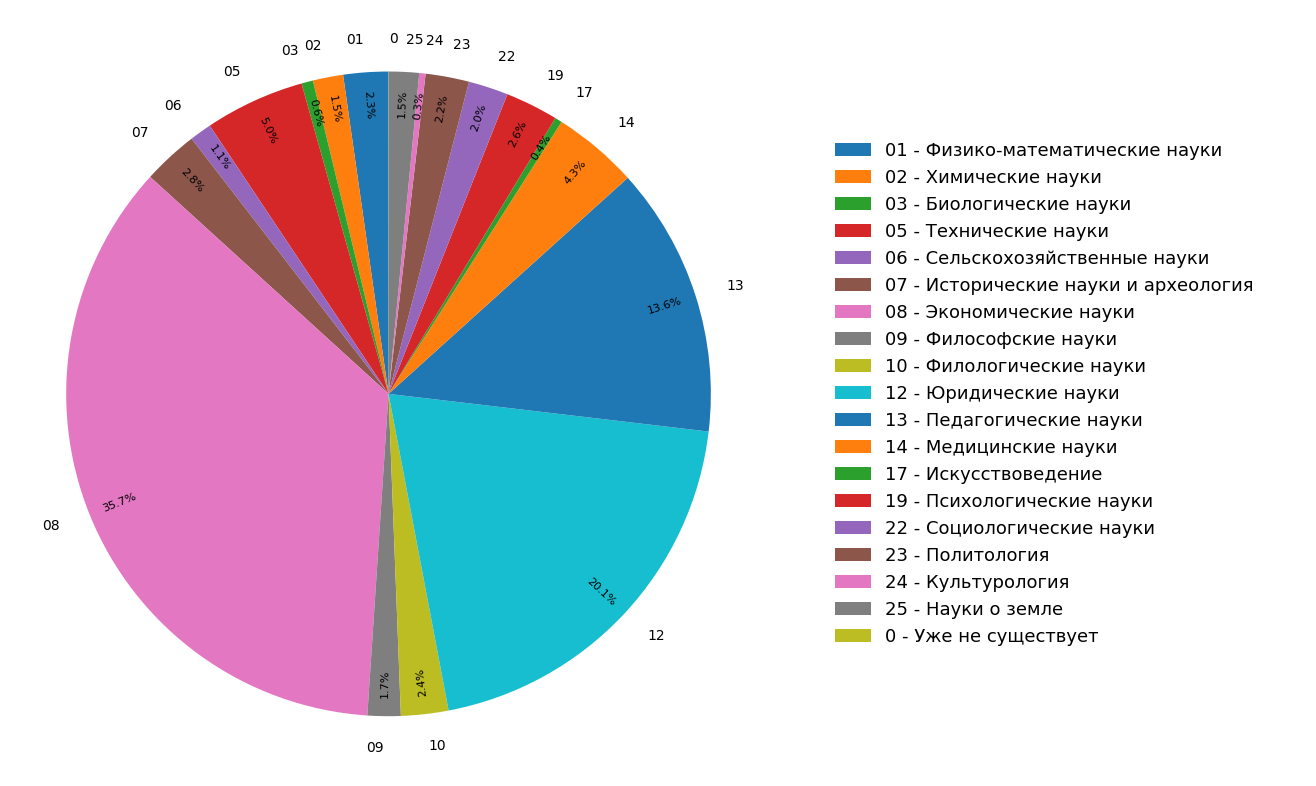 Fig. 4. Distribution of topics of scientific documents.
Fig. 4. Distribution of topics of scientific documents.As a result, we literally from the materials at hand not only learned the thematic structure of the indexed Internet, but also made additional functionality, with the help of which we can classify an article or other scientific document in one single motion by three thematic rubricators.

The above functionality is now being actively implemented in the Antiplagiat system and will soon be available to users.