Hi, username! Every day we are confronted with the search for various data. Almost every website with a lot of information now has a search. Search is in home computers, in mobile phones, in various kinds of software. Of course, if you ask any developer about the search in terms of technology, elasticsearch, lucene or sphinx immediately comes to mind. Today I want to look with you "under the hood" of full-text search and understand the first approximation, how does it work, for example, hh.ru.
 Disclaimer: this article is not the only correct point of view and serves only as an introductory point for the initial acquaintance with the work of text search and some variants of the implementation of its individual parts.
Disclaimer: this article is not the only correct point of view and serves only as an introductory point for the initial acquaintance with the work of text search and some variants of the implementation of its individual parts.If you look at the details of the search, then besides the obvious part in the form of a search line you can see a lot more:
- hint (she suggest),
- search results counter (counter)
- various types of sorting (sort)
- facets (facet) - grouped characteristics of documents, for example, the metro on which there is a vacancy, also performing the function of filters (filters),
- synonyms (synonyms),
- pagination
- snippet (snippet) - a short description of the document in the issue,
- etc.

And all this serves one purpose - to satisfy the user's need to find the necessary information as quickly and relevantly as possible. For example, filtering is important to narrow the search results, in our case it can be a filter by candidate’s experience, location, or employment. Facets are useful to display how many vacancies are in each salary range. It is also important to supplement requests and documents with synonyms so that, upon request, “java developer” can find “java developer” documents.
In addition to the search itself, there are always a number of components that make life easier for the user: a guard who is responsible for correcting errors, or a gremest that prompts more suitable queries when you interact with the search string. In some cases, it is important to be able to reformulate the query. For example, a part of the request should be moved to filters: from the request “programmer moscow” Moscow can be put into the filter by city.
1. Basic
And now to the point. The search itself is divided into two large stages:
- indexing (processing of documents and their unfolding according to the special structures of the index, so that then you can quickly carry out the search itself),
- search (applying filters, boolean searching, ranking, etc.).
1.1. Indexing
A small lyrical digression. Then I will introduce the concept of a term - so it is called the minimum unit of indexing and query. This is the same unit that will be stored in the index dictionary. It can be a word given to its normal word form or basis, number, email, letter n-grams or something else. Usually, a term includes a field in which it is indexed or searched.
To begin with, input documents need to be turned into a set of terms and filter out stop words. They can be both common words - prepositions, conjunctions, interjections, and other things, such as special characters, on which we do not want to search. In order for the search to work with different word forms, in the process of indexing we usually bring all the words to some basic state. Usually one of two procedures is used: either stemming is the process of isolating the stem of the word (development-> development), or lemmatization is the process of bringing the word to normal form (skills-> skill).
1.2 Index Structures
The most popular way to represent an index is the inverted index. In essence, this is a kind of hash table, where the key is a term, and the value is a list of documents (and usually a list of document id's, called a postings list) in which this term is present. Usually an inverted index consists of two parts - a dictionary (term dictionary) and lists of documents for each term (posting list):

In addition, the index may contain information about the positions of terms in the document (position index), which will be useful when searching for terms at a certain distance, in particular with phrasal queries, about the frequency of terms, which will help in ranking and constructing a query plan. But more about that below.
1.2.1 Term dictionary
The dictionary stores all terms that exist in the index, and is designed to quickly find links to the list of documents. There are several options for storing a dictionary:
- The hash table, where term is a key, and value is a link to the list of documents for this term.
- An ordered list by which you can search by binary search.
- Prefix tree (trie).
The best way is the last option, because It has several advantages. First, on a large number of terms the prefix tree will take up much less memory, because the repeating parts of the prefixes will be stored only once. Secondly, we immediately get the opportunity to make prefix queries. And thirdly, such a tree can be compressed by combining unbranching parts.
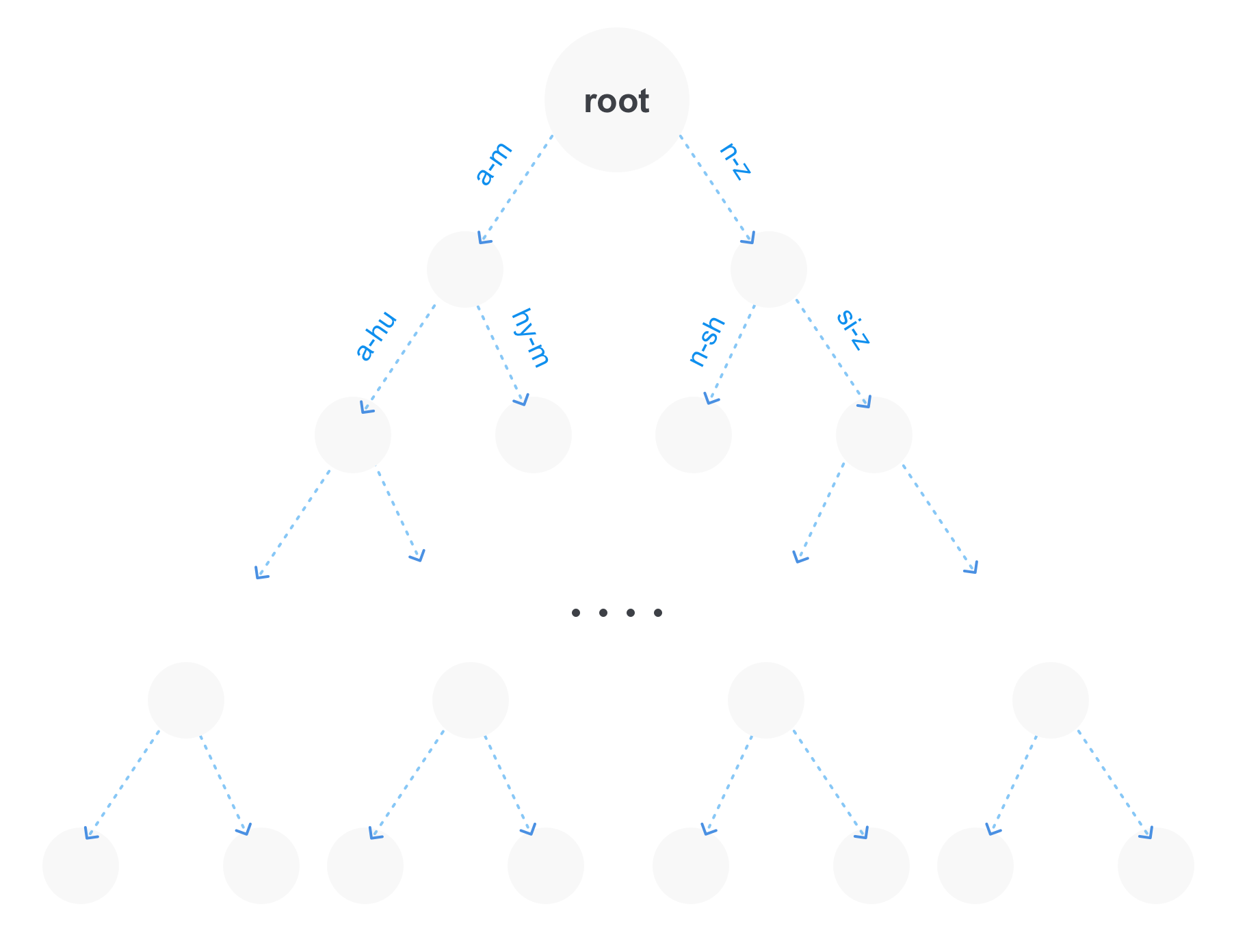
Of course, the prefix tree may not be the only structure for storing terms in the index. For example, there may also be a suffix tree next to it, which in turn will be more optimal for queries with jokers (queries of the form po * sql).
1.2.2 Posting list
The document list is an ordered list of document identifiers, which allows for some optimization with it. Usually he keeps in himself not only the list of documents in which the term is found, but also the positions (postings) on which it is found. This solves several problems at once: we immediately know how many times a word has occurred in a document, we can make queries for phrases and queries with a certain distance between terms, crossing several lists of documents at once and looking at the positions of terms.

For example, in this list on the term
scala in 6 documents in the
title, the word occurs 4 times, in positions 2, 15, 18 and 25.
1.2.3 Documents with multiple fields
Most of the document consists of several fields, at least the name of the document and its body. This helps when searching for individual parts of the document and with the coefficient of significance of the term when ranking (for example, the term found in the title can be considered more significant).
Plus, not only text fields are usually stored in the index, but also signs of documents, some numerical values, etc. can be stored. Storage in the index usually occurs in the form {term-field}.

For example, if you take a job, then it will have several fields at once: name, description, company, salary fork, city and necessary experience. This is necessary so that the user can comfortably search not only by the name and text of the company, but also can filter by salary and experience, see how many vacancies are in his city and in neighboring cities, or even search for vacancies of a particular company.
1.3 Compress and index optimization
Speed is important for searching, so usually most of the index search operations are performed in RAM. For this, it is very important to apply a series of optimizations to the index, which will allow it to fit into a limited memory size. In addition, a number of optimizations are usually used, which allow the search to move through the index with greater speed, skipping its unnecessary pieces.
1.3.1 Delta compression
Since we remember that the list of documents by term (also known as the postings list) is ordered, the first idea how to compress it is to replace the list with documents id with list of offsets relative to the previous ones. On a specific list of 6 identifiers, it will look like this:

Thus moving through the list, we will always calculate the current identifier from the obtained previous value. For example, to the second offset 3 we add the first value 2 and get id 5, to the third 4 we add the value 5, and we get 9 and so on. With a large number of documents, this works very well, especially in conjunction with another compression method — writing numbers of variable length format.
1.3.2 VarByte and VarInt
This is a way to save each individual list item in memory so that it occupies a minimal amount of space. For example, if the first three offsets fit only 1 byte, then there is no need to occupy more. Considering that our list contains not id documents, but deltas - compression will be very effective. In such a representation of numbers, the first bit of each byte is a flag, whether the representation of the current number ends on this byte.

If the first bit of a byte is 0, then this is the last byte of the number, if 1 is not.
1.3.3 Skip list / Jump table
The list with gaps is one of the structures for quickly navigating through a list of documents of a certain term, skipping an unnecessary part of the list. The idea is to store references to distant list items on a disk in front of the list itself, since after compression we cannot say where exactly a 100 or 200 document will be located. For example, it is convenient when there is a request of two terms, where one term will occur frequently, and the second will conversely be rare, and the list of documents will begin only with the 200th id of the document. Then, if there is a list with gaps for the first list, we will be able to save time on the move and skip the unnecessary block of identifiers immediately.

1.4 Requests
1.4.0 Term Request
The simplest type of request, in which we simply need to find the corresponding list of documents and issue documents sorted after ranking.
For example, we will find a list of positions for the
java query:

1.4.1 Boolean queries (and, or, not)
Boolean search is one of the most important parts of the information search that we encounter everywhere. The entire Boolean search is built on the combination of AND, OR and NOT. For example, when we search for a query of two words:
java android , then in fact in the search in a simple version it is converted to
java AND android . And this means that we want to find all the documents that contain both words.
It is worth mentioning at once how the list of documents is moved. Since the lists of documents for each term are sorted, there are usually two ways to navigate through the lists: move through the documents sequentially, passing them one by one, or move immediately to a specific document, skipping those that are not needed (for example, when the first list is much smaller , and we do not need to go through a large block of documents in the second list). In this case, we first use the pointer from the skip pointers for the second list to move as close as possible to the desired document id, and then move to it linearly.
At the time of the search, the following happens: in the index by java and android terms there are lists of documents, then an intersection is made on them - that is, we find documents that contain both terms. In this search, both ways of moving through the lists for faster crossing are used.

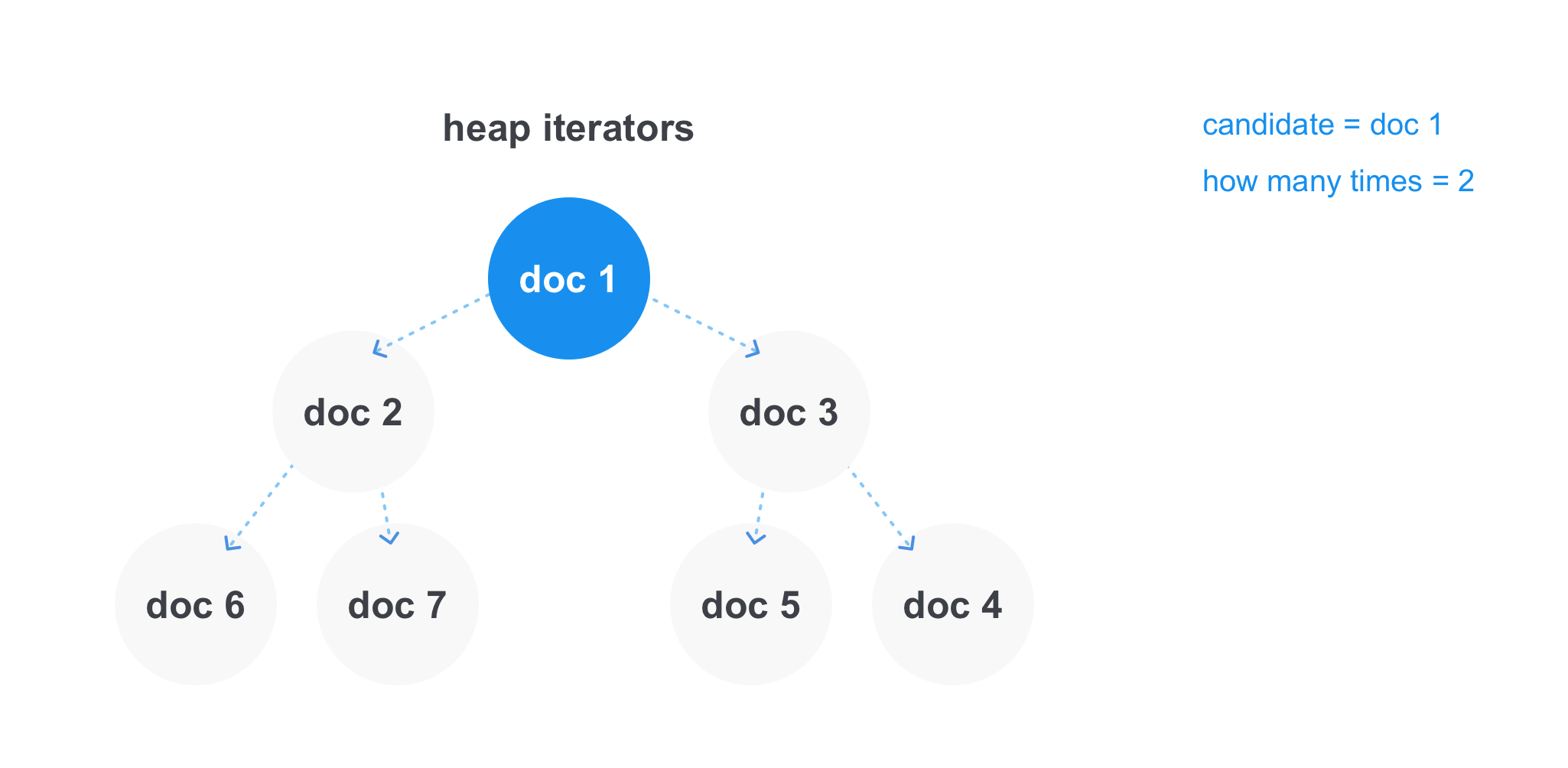
With OR requests of the java OR scala type, where we need to find all the documents containing at least one of the terms, the situation is different — we do not need a term in all the lists of documents at once. But there are requests with several OR operators, and then the condition of the minimum number of matches can occur, for example, there can be a java OR query scala OR cotlin OR clojure with at least two matches, and then we have to show all the documents that contain at least two words from the query .
In this case, the heap works most effectively. We can store references to the iterators of each list in it and get the minimum element in constant time. After we take the minimal element, we remove the iterator from the heap, take a step forward and add it to the heap again. Separately, you can store the current candidate for adding to the result and the counter, how many times he met, and at the moment when the candidate will differ from the minimum element in the heap, see if we go through the minimum number of matches in the operation. And either add to the final list of results, or discard the document.
1.4.2 Prefix / Jokers
Sometimes we want to find all the documents in which there is a word that begins with a specific prefix. In such cases, the prefix request will help us, which will look like
jav * . A prefix query works very well when the dictionary is implemented on a prefix tree, and then we just go to the prefix nesting and take all the terms that lie below.
1.4.3 Queries for phrases and near query
There are cases when you need to find the entire phrase, for example, “java developer”, or find words, between which there will be no more than some words, for example, “java” and “developer”, between which no more than 2 words will be found. Documents containing java android kotlin developer. To do this, additionally used lists of positions of the words in each document.

At the moment of crossing the lists of documents, everything is the same as with the AND operation. But after the document is found in both lists, an additional check is made - that the terms are at the right distance from each other, according to the position difference.
1.4.4 Request Plan
Usually, before the execution of the request itself, its plan is built. This is done in order to optimize the execution of the query and to work such optimizations as a list with gaps for the list of documents.
The easiest way to optimize a query is to intersect the lists of documents in order of increasing their size. Thus, we will not wastely cross documents from large lists that are missing from small lists.
Consider for example the query
android AND java AND sql . Suppose that in the list of android 10 documents, in sql - 20, and in java - 100. In this case, it is best to first cross the smallest lists, and the optimized query will look like
(android AND sql) AND java .
In the case of OR, the simplest is to count the number of documents at the intersection as the sum of two potentially intersecting lists.
1.4.5 Query Expansion - Synonyms
Besides the fact that the user enters the search box, usually the search tries to expand the query itself to find more relevant documents. Many things can be used to expand the search: the user's query history, some personalized data about it, and more. But besides all this, there is also a universal way of expanding the query - synonyms.
In this case, when writing documents to the index, the term is replaced with a “link” in the synonym dictionary:
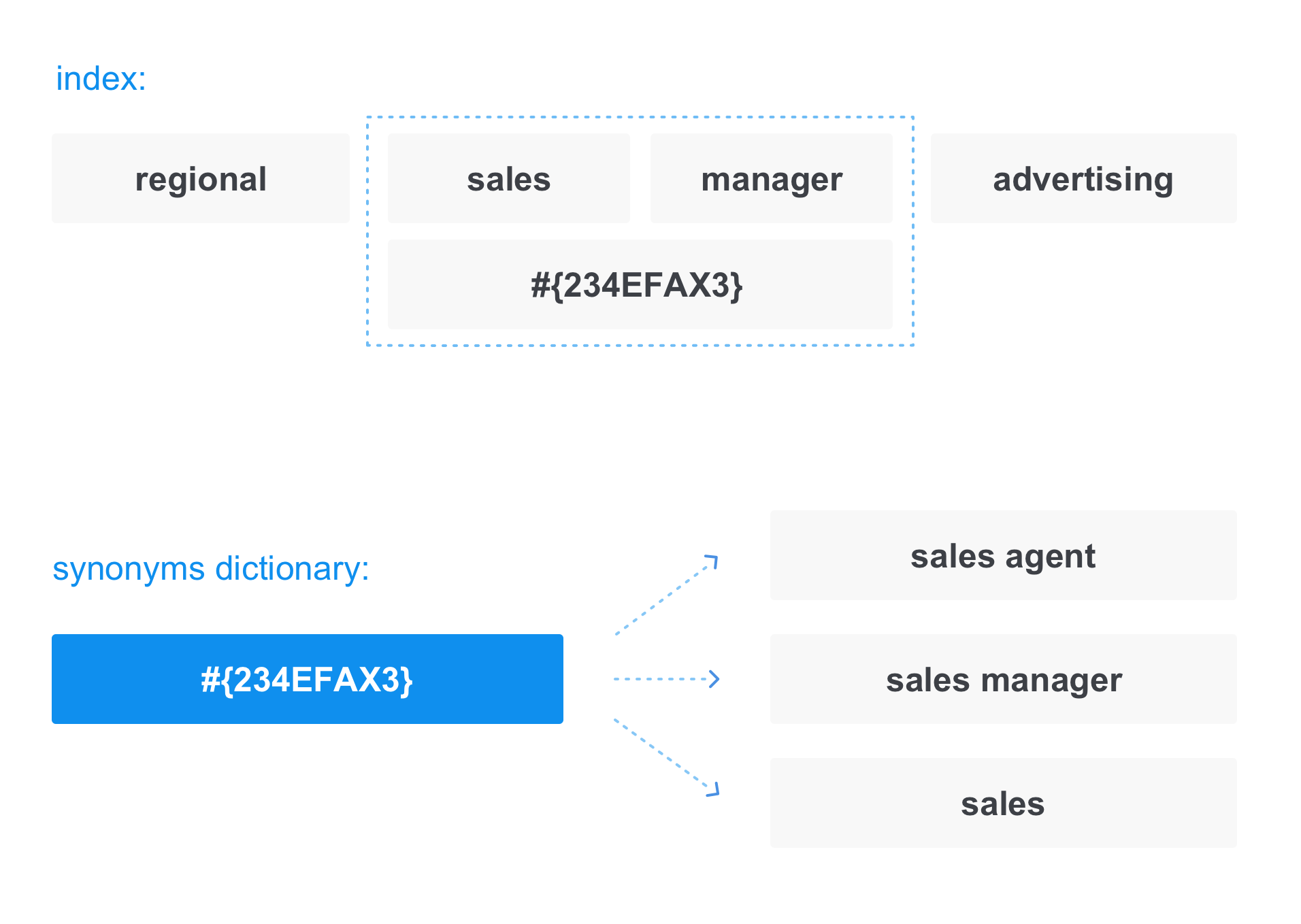
The same thing happens when converting a query. For example, when we request a
sales manager , the request actually looks like:

Thus, in the answer we get not only those documents that contain the sales manager, but also those that contain the sales agent and sales.
1.5 Filtering
1.5.1 Fast range filter
Sometimes we want to filter something by a range of values, for example, by experience in years. Suppose we want to find all the vacancies with the required experience from 3 to 11 years. The first solution is to make a request with all options from the range, combining them through OR. But the problem is that there may be too many meanings. One way to solve this problem is to record the value at once with several precisions:

In this case, we will store 5 accuracy: year (we will consider this as the initial value), two, four, eight and sixteen.
Then the following will happen during the recording: for example, when writing a document with the requirement of 6 years experience, we write down the value at once in all accuracy:

When filtering “from 3 to 11 years”, the following happens: we select only the values we need in the necessary precision, and we get only 3 values instead of 8 and we get the query
(real value == 3) OR (precision 4 == 4) OR (precision 4 == 8)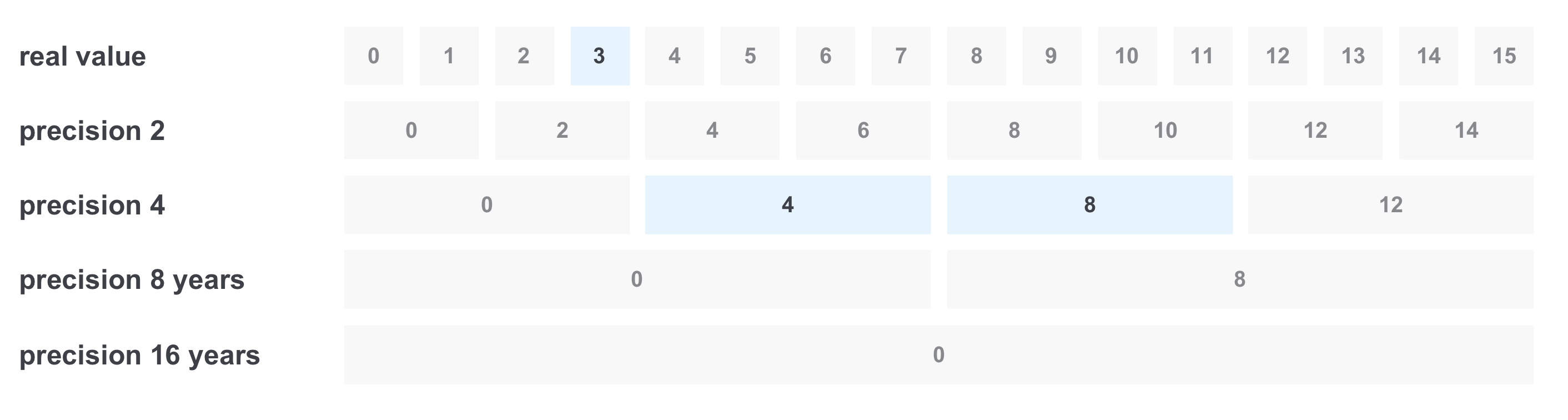
1.5.2 Bitmasks
Bitmasks are an integral part of the index. The most important use is to filter deleted documents. When you delete a document from an index, physical deletion does not occur immediately. A special structure is written next to the index, where each bit means the document id in the index, and a bit is raised during deletion, and when searching, these documents are filtered and do not fall into the output.
You can also use bit masks to set permissions for each user to certain documents and to cache individual popular filters. Then usually bit masks are stored separately from the index.
For example, we have popular filters: the city of Moscow, only part-time employment, without work experience. Then, before the request, we can get the already saved bit masks for these documents, put them together, and get the final bit mask - which documents go through all three of these filters, thereby saving time for filtering.

2. Ranking
As we remember, the main task of the search is to obtain the most relevant information in the shortest possible time. And in this we will be helped by the ranking of documents after we have filtered the documents by text query and applied the necessary filters and rights.
The easiest and cheapest way to make a ranking is to simply sort the documents by date. Some systems used to do this, for example, in the news or in real estate ads, so the user was shown the newest documents first.
Sometimes a ranking model by the number of words found in a document can be used, for example, when there are not so many documents, and we want to find all the documents in which at least one of the query words is found. In this case, those documents in which all the words from the query or more of them are found will be more relevant.
Of course, at present these methods have already become irrelevant, and they can rather be attributed to the history of the issue.
2.1 TF-IDF
TF-IDF (term frequency - inverse document frequency) is one of the most basic and most used ranking formulas. The essence of the formula is to reduce the importance of the terms used everywhere, for example, prepositions and interjections, and to make more meaningful terms that are rare, thereby showing documents with rare and more meaningful terms from the query. And now let's break the formula apart:
TF (term frequency) is the frequency of the term in the document. It is calculated simply:
TF term `java` = number of term` java` in the document / number of all terms in the document
IDF (inverse document frequency) - the inverse of the frequency with which the word is found in the collection of documents. Helps to reduce the weight of frequently used words.
IDF (`java`) = log (the number of documents in the collection / the number of documents in which the term` java` is found)Next, to get the TF-IDF term java, we just need to multiply the resulting TF and IDF values. Greater weight will be given to documents in which terms are more common, but they are also found in fewer other documents. This allows you to properly weigh the request, for example, the word developer will appear in programmer’s job vacancies much more often than the name of a particular programming language, and if you request java developer, this will allow you to make the correct ranking of search results.
2.2 field weight
Combinations with weights help fairly well when there are several fields in a document, such as a heading and text. Then we can set a larger coefficient for terms that occur in the document header, and a smaller one for those found in his body.
2.3 BM25 and BM *
BM25 (Okapi best match 25) is a variation of the TF-IDF formula with free weights and normalization to average document size. In a separate formula, BM25F is allocated, which essentially uses instead of the average document size the average size of a specific field (for example, a header or body text).
mathrmBM25= sumwi=1 frac(1+k) cdot mathrmTFi cdot mathrmIDFi mathrmTFi+k(1−b+b frac mathrmDLavg mathrmDL) mathrmIDFi= frac mathrmlog( fracN−n+1n) mathrmlogN
2.4 Other ranking formulas
In addition to the basic ranking formulas, there are others, for example:
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5 Ranking machine learning
In modern search rankings are increasingly beginning to use personalization, the behavior of a particular user, as well as assessor assessments to improve the results of issuance. I will not go into the details of machine learning for ranking tasks in this article, but I will leave a
link for those interested in this topic.
2.6 Top k documents after ranking
An important point in the search is taking top documents or a certain part of it, for example, for pagination. The main problem is that during the ranking we do not know how many documents are and in what order they stand.
Also, we can not guarantee that the entire list of documents can fit in memory and will be quickly sorted. And that is why special algorithms are usually used to take
top k documents.
One way to get top documents is to use a bunch. The heap size is always k, where k is usually
the page size * the number of the desired page . We iterate over the flow of documents and let all their speeds through heap. With this method, you can guarantee the complexity of n * log (n) and memory consumption k.
In addition, you can use the optimization when loading not the first page of the top. For example, if a person moves to the next page after he was already on another page on this request, for example, from 10 page goes to 12, then you can memorize the score of the last document from 10 page and immediately discard all documents with a large score value. So you can save on the size of the heap or array, so as not to store sorted documents for page n - (n * page size).
3. Physical index storage
3.1 Segments
Usually the storage of the index occurs in the form of segments - small independent indexes. For recording in such indices only one segment is available, the last one.
Documents can be added to the index, but removing them is rather difficult: to delete one document, you need to go through all the lists of documents of each term, delete the document from each one and change them. In general, the task is not simple. Therefore, deletion is performed by setting a special bit and filtering such documents with a bit mask. The document is also updated (the old version of the document is marked as deleted, and the new version is added to the end of the open index). The physical removal of the document from the index occurs only during the merge of the segments (merge).
One of the advantages of several segments in the index is that the search operation can be done by walking simultaneously across all segments of the index:

But a large number of segments is not always good. If there are too many segments in the index, the search queries can run longer, and the index itself will take up more memory than it could, due to the duplication of the dictionary in each segment.
3.2 Merge segments (megre)
There is another important index operation - merging segments. The main purpose of this operation is to rid the index of “garbage” - deleted or old versions of modified documents. During a merge, several segments are merged, their vocabulary and lists of documents are rebuilt, and physical documents (deleted or old versions of modified ones) are also physically deleted.

This can be a costly operation, so there are merge strategies that define the rules when it is necessary and best to do them. They may depend on various factors:
- The percentage of deleted documents in the index
- the number of segments at one level (for example, when moving to the next level, the size of new segments increases by 2 times),
- the time when you can merge (perhaps at a certain time of day the load on the search is less).
4. Search cluster
When it comes to searching not on a single machine, but on a whole cluster, one of the options is to divide the search into basic and meta. Basic searches are directly responsible for searching the index segments, and meta-searches distribute the query to basic ones (for example, if the basic ones have sharding or depending on the load, etc.). And after meta gets the results from the base ones, it merges them into one final result in order to give it to the user.

4.1 Sharding and Replication
Searching sharding can be done at the domain level level (for example, hh has separate indexes for vacancies, resumes and employers), and within a particular index. This allows you to distribute the load between machines with an index.
Also in search clusters, as in all fault tolerant distributed storage systems, data replication is often used. First, it is necessary to speed up the search, so that you can send different requests to different basic searches. Secondly, this is done for data redundancy so that the loss of one replica is not a problem for the entire cluster, and the search can easily read data from other replicas.
4.2 Speculative Timeouts
In the case where the replicas of our index are stored on several basic searches, we can apply different search bypass strategies. You can send requests for several basic searches at once, you can wait for a timeout from one and only then proceed to the next one.
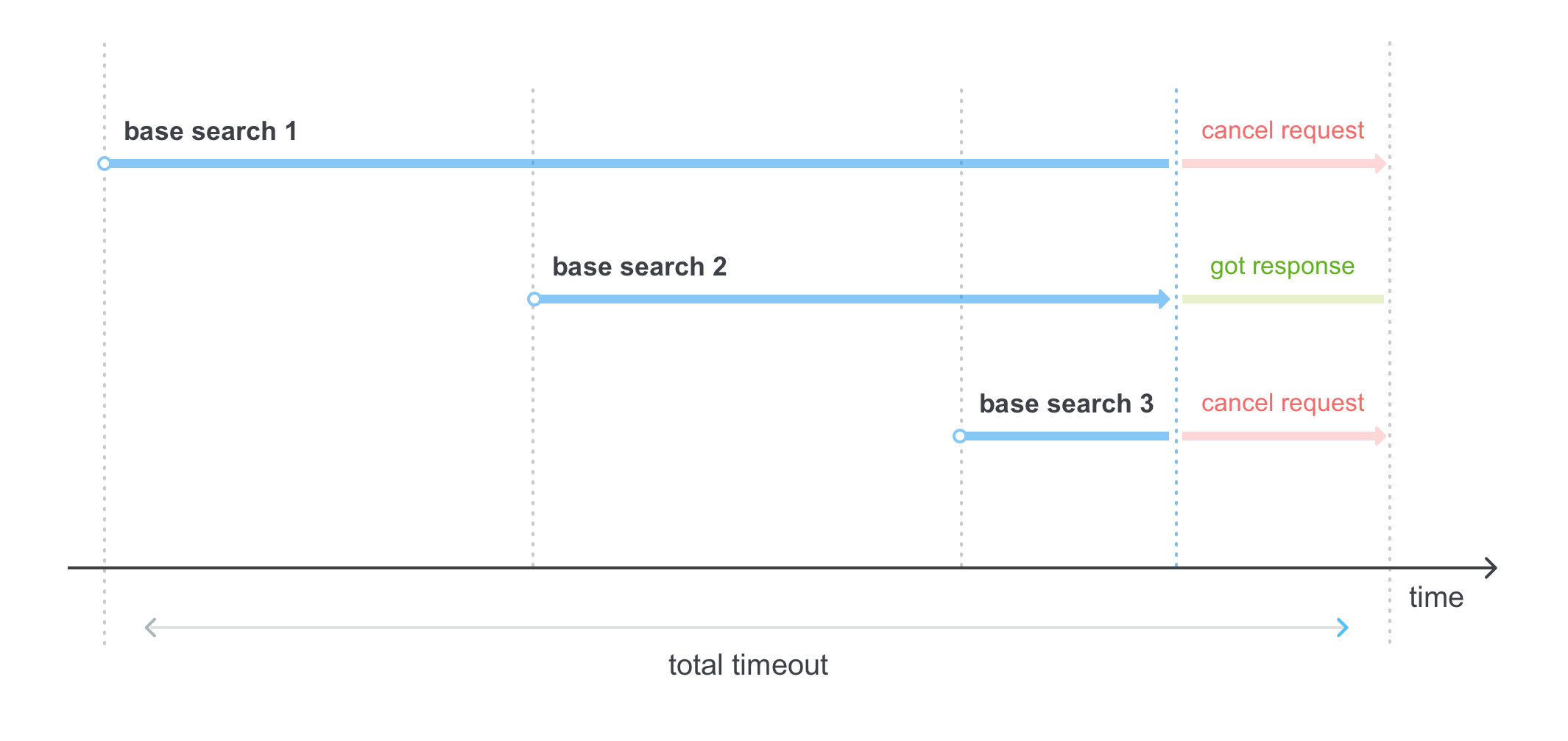
One of the mixed strategies, which is used in hh search, are
speculative timeouts , when the search is performed sequentially at certain intervals, in order to meet the total timeout on the meta-search:
5. Bonus track ... or what's next
So we looked at how the search is arranged in the first approximation, but there are still a lot of unaffected topics and topics that you can go into. Then you can see how other parts of the search are arranged: how clusters work, facets, statistics, how snippets from whole documents are displayed that are shown in search results, and how the highlight of the search terms works, how to work with typos. Separate topics deserve the severe search engine search line, the indexing device on the cluster, other ways of working of the mechanisms described in the article, for example, taking top k documents.
In the continuation of the study topic, you can:
That's all, thank you all for your attention, it is interesting to hear your comments and questions.
PS
I would like to express my
deep gratitude to
gdanschin for help in writing this article.