Update: good discussion on Hacker NewsDavid Yoo on GitHub has developed an
interesting performance test for function calls through various external interfaces (Foreign Function Interfaces,
FFI ).
He created a shared object file (
.so ) with one simple C function. Then he wrote code to repeatedly call this function through each FFI with the time dimension.
For C "FFI", he used the standard dynamic layout, not
dlopen() . This distinction is very important, as it really affects the test results. One can argue how fair such a comparison is with the actual FFI, but it is still interesting to measure it.
The most surprising result of the benchmark is that the FFI from
LuaJIT is significantly faster than C. It is about 25% faster than the native C call for a shared object function. How could a weakly and dynamically typed scripting language overtake in the benchmark C? Is the result accurate?
In fact, this is quite logical. The test is running on Linux, so the delay is from the Procedure Linkage Table (PLT). I prepared a really simple experiment to demonstrate the effect in a simple old C:
https://github.com/skeeto/dynamic-function-benchmarkHere are the results on the Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callHere are three different types of function calls:
- Via PLT.
- Indirect function call (via
dlsym(3) ) - Direct function call (via JIT-compiled function)
As you can see, the last is the fastest. It is usually not used in C programs, but this is a natural option in the presence of a JIT compiler, including, obviously, LuaJIT.
The
empty() function is called in my benchmark:
void empty(void) { }
Compiling into a shared object:
$ cc -shared -fPIC -Os -o empty.so empty.c
As in the previous
GPSN comparison , the benchmark can call this function many times before the alarm goes off.
Procedure Layout Tables
When a program or library calls a function in another shared object, the compiler cannot know where the function will be in memory. Information is found only at runtime, when the program and its dependencies are loaded into memory. Usually the function is located in random places, for example, in accordance with address space randomization (Address Space Layout Randomization, ASLR).
How to solve such a problem? Well, there are several options.
One of them is to mark each call in the binary metadata. The dynamic runtime linker then
inserts the correct address with each call. The specific mechanism depends on the
code model that was used during the compilation.
The disadvantage of this approach is to slow downloads, increase the size of binary files and reduce the
exchange of code pages between different processes. Loading slows down because all dynamic paging points need to be patched to the correct address before starting program execution. The binary is inflated, because each entry needs a place in the table. And the lack of public access is associated with a change in code pages.
On the other hand, the costs of invoking dynamic functions can be eliminated, which gives JIT-like performance, as shown in the benchmark.
The second option is to route all dynamic calls through the table. The original dial peer refers to the stub in this table, and from there to the actual dynamic function. With this approach, the code does not need to be patched, which leads to a
trivial exchange between processes. Only one record in the table needs to be patched to each dynamic function. Moreover, these corrections can be made
lazily when the function is first called, which speeds up loading even more.
In systems with ELF binary files, this table is called the Procedure Linkage Table (PLT). PLT itself is not corrected in reality - it is displayed as read-only for the rest of the code. Instead, the global offset table (GOT) is corrected. The PLT stub retrieves the address of the dynamic function from the GOT and
indirectly switches to that address. In order to lazily load function addresses, these GOT records are initialized with the address of a function that finds the target character, updates the GOT with this address, and then moves on to this function. Subsequent calls use the lazily detected address.
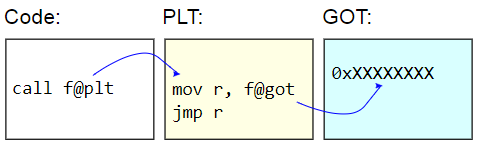
The disadvantage of PLT is the additional overhead of calling a dynamic function, which was manifested in the benchmark. Since the benchmark measures
only function calls, the difference seems quite significant, but in practice it is usually close to zero.
Here is the benchmark:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
Since
empty() is in a shared object, the call goes through PLT.
Indirect dynamic calls
Another way to dynamically invoke functions is bypassing PLT and getting the address of the target function in the program, for example, via
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
If the address of the function is obtained, then the cost is less than the function calls through PLT. No intermediate stub function and access to GOT. (Caution: if the program has a PLT entry for this function, then
dlsym(3) can actually return the address of the stub).
But this is still an
indirect challenge. On conventional architectures,
direct function calls get its immediate relative address. That is, the purpose of the call is some hard-coded offset from the call point. The CPU can understand much earlier where the call will go.
Indirect calls have more costs. First, the address needs to be stored somewhere. Even if it is just a register, its use increases the register deficit. Secondly, indirect calls provoke the predictor of branches in the CPU, imposing an additional load on the processor. In the worst case, a call can even lead to a pipeline stop.
Here is the benchmark:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
The function passed to this benchmark is retrieved using
dlsym(3) , so the compiler cannot
do something tricky , such as converting this indirect call back to direct.
If the loop body is complicated enough to cause a shortage of registers and thus giving the address to the stack, then this benchmark also cannot be honestly compared with the PLT benchmark.
Direct function calls
The first two types of calls to dynamic functions are simple and easy to use.
Direct calls for dynamic functions are more difficult to organize because they require code changes during its execution. In my benchmark, I put together a
small JIT compiler to generate a direct call.
The trick is that on x86-64, explicit transitions are limited to a 2 GB range due to a 32-bit immediate operand signed. This means that the JIT code should be placed almost next to the target function,
empty() . If the JIT code should call two different dynamic functions divided by more than 2 GB, then it is impossible to make two direct calls.
To simplify the situation, my benchmark does not worry about the exact or very careful choice of the address of the JIT code. After receiving the address of the target function, he simply subtracts 4 MB, rounds to the nearest page, allocates some memory and writes code to it. If everything is done properly, then to search for a place, you need to check your own program views in memory, and this cannot be done in a clean portable way. On Linux
, parsing of virtual files under / proc is required .
This is how my JIT memory allocation looks. It assumes
reasonable behavior for casting uintptr_t types :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
There are two pages: one for recording and the other with non-writable code. As in my
library for closures , here the bottom page is writable and contains the variable
running , which is reset on alarm. This page should be located next to the JIT code in order to provide effective access relative to the RIP, as functions in the two other benchmarks. The top page contains such an assembly code:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty is the only dynamically generated instruction, it is necessary for correct filling of the relative address (minus 5 is indicated relative to the
end of the instruction):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
If the
empty() function is not in a shared object, but in the same binary file, then this is essentially a direct call that the compiler will generate for
plt_benchmark() , assuming that for some reason it has not embedded
empty() .
Ironically, calling a JIT-compiled code requires an indirect call (for example, through a function pointer), and this cannot be bypassed. What is there to do, jit-compile another function for a direct call? Fortunately, it doesn’t matter, because only the direct call is measured in the loop.
No secrets
Given these results, it becomes clear why LuaJIT generates more efficient calls to dynamic functions than PLT,
even if they remain indirect calls . In my benchmark, indirect calls without PLT were 28% faster than with PLT, and direct calls without PLT were 43% faster than with PLT. This small advantage of JIT programs over simple old native programs is achieved due to the absolute rejection of code exchange between processes.