This blog is usually dedicated to license plate recognition. But, working on this task, we came up with an interesting solution that can be easily applied to a very wide range of computer vision tasks. Now we will tell about it: how to make a recognition system that will not let you down. And if you fail, you can tell her where the error is, retrain and have a slightly more reliable solution than before. Welcome under the cut!

What happened?
Imagine, you have a task: to find a pizza in a photo and determine what kind of pizza it is.
Let us briefly go through the standard way we often went. What for? To understand how to do ... do not.
Step 1: dial the base
 Step 2:
Step 2: for reliability of recognition, it is possible to note that there is a pizza, and that the background (so we will include the segmentation neural network in the recognition procedure, but it is often worth it):
 Step 3:
Step 3: we will bring it into a “normalized form” and classify it with the help of another convolutional neural network:

Fine! Now we have a training base. On average, the size of the training base can be several thousand images.
We take 2 convolutional networks, for example, Unet and VGG. The first is trained on the input images, then we normalize the image and train the VGG for classification. Works great, we transfer to the customer and we consider honestly earned money.
This is not how it works!
Unfortunately, almost never. There are several serious problems that arise during implementation:
- Variability of input data. We studied by one example, in reality everything turned out differently. Yes, just during the operation something went wrong.
- Very often, recognition accuracy remains insufficient. I want to 99.5%, and it goes from 60% to 90% on a good day. But they wanted, as a rule, to automate a solution that works by itself, and even better than people!
- Such tasks are often outsourced, which means that the contracts are already closed, the acts are signed and the business owner has to decide whether to invest in the revision or abandon the decision altogether.
- Yes, with time everything starts to degrade, as in any complex system, if you do not involve specialists who participated in the creation, or the same skill level.
As a result, many who have touched all this mechanics with their hands, it becomes clear that everything should happen quite differently. Like that:
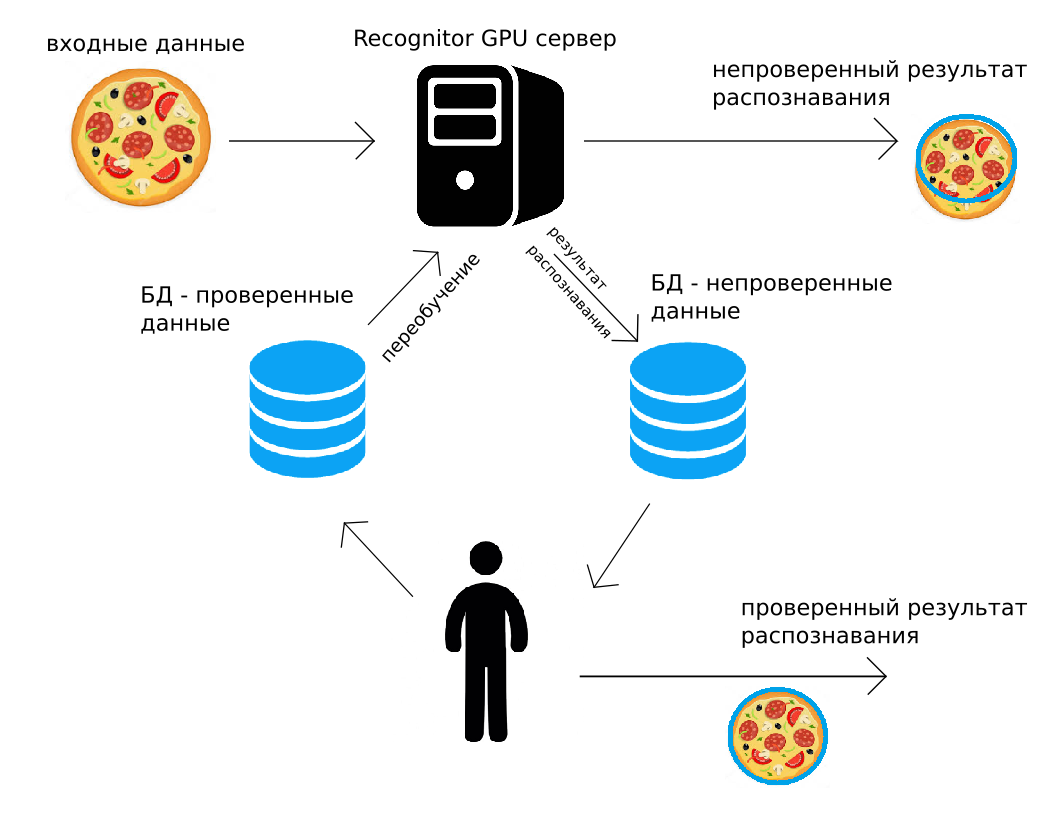
The data comes to our server (via http POST, or using the Python API), the GPU server recognizes them “as it could”, immediately returning the result. Along the way, the same recognition result together with the image is added to the archive. The person then controls all the data, or a random part of them, corrects. The corrected result is placed in the second archive. And then, when it will be convenient to do (for example, at night), all convolutional neural networks used for recognition are retrained using the data corrected by the person.
Such recognition closure, human supervising and additional training solve many of the problems listed above. In addition, in solutions where high accuracy is needed, you can use human-tested output. It seems that this use of human-verified data is too expensive, but later we will show that it almost always makes economic sense.
Real example
We have implemented the described principle and successfully apply it already on several real problems. One of them is the recognition of the number on the pictures of containers in the railway terminals, taken from the tablet. It is quite convenient to point the tablet onto the container, get the recognized number and operate with it in the tablet program.
Typical snapshot example:

The number in the picture is almost perfect, only a lot of visual noise. But there are harsh shadows, snow, unexpected lettering arrangements, severe inclines or perspective when shooting.
And this is how a set of Internet pages looks like, on which all the “magic” happens:
1) Sending a file to the server (of course, the same can be done not with the html page, but with the help of Python or any other programming language):
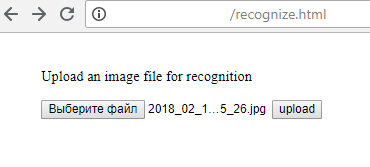
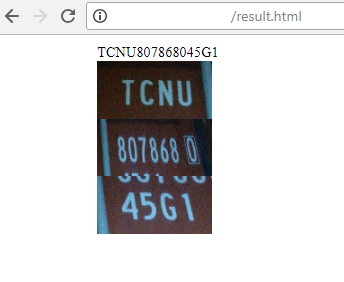
2) The server returns the result of recognition:
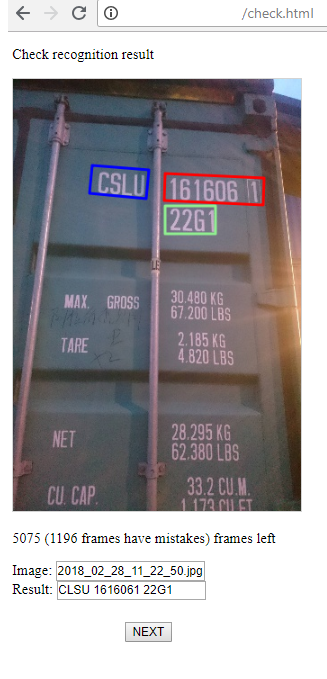
3) And this is the page for the operator who controls the success of recognition, and if necessary corrects the result. There are 2 stages: search for areas of groups of characters, their recognition. The operator can fix all this if he sees an error.
4) Here is a simple page where you can start training for each of the recognition stages, and, after starting, see the current loss.
Severe minimalism, but it works great!
How can this look from the side of a company that has decided to use the described approach (or our experience and Recognitor servers)?
- Selected state-of-art neural networks. If everything is based on existing debugged solutions, then you can start the server and set up markup in a week.
- A stream of data (preferably endless) to the server is organized, several hundred frames are laid out.
- Start training. If everything “came together”, then the result is 60-70% of successful recognitions, which greatly helps in further markup.
- Then begins the systematic work on the presentation of all possible situations, verification of recognition results, editing, retraining. As you learn, embedding the system in a business process becomes more and more cost-effective.
Who else does that?
The theme of the closed loop is not new. Many companies offer systems to work with data of one type or another. But the paradigm of work can be structured in a completely different way:
- Nvidia Digits - some pretty good and strong models, wrapped in a clear GUI, where the user must put their pictures and JSON. The main advantage - minimal knowledge of programming and administration gives you a good solution. Minus - this solution can be far from optimal (for example, it’s not good to look for car numbers through SSD). And to understand how to optimize the solution, the user does not have enough knowledge. If there is enough knowledge - he does not need DIGITS. The second minus is that you need to have your own equipment on which to set everything up and deploy.
- Markup services such as Mechanical Turk, Toloka, Supervise.ly. The first two provide you with markup tools, as well as people who can markup data. The latter provides excellent tools, but without people. Through services, you can automate human labor, but you need to be an expert in setting the problem.
- Companies that have already trained and provide a fixed solution (Microsoft, Google, Amazon). Read more about them here (https://habr.com/post/312714/). Their solutions are not flexible, not always “under the hood” will be the best solutions that are necessary in your particular case. In general, it almost always does not help.
- Companies that work with your data, for example ScaleAPI (https://www.scaleapi.com/). They have a great API, for the customer it will be a black box. Input data - output result. It is very likely that inside there are all the best automation solutions, but it does not matter to you. Enough expensive solutions in terms of one frame, but if your data is really valuable - why not?
- Companies that have the tools to do almost a full cycle of their own hands. For example, PowerAI from IBM . This is almost like DIGITS, but all you have to do is markup datasets. Plus, no one optimizes neural networks and solutions. But a lot of case studies. The resulting neural network model is deployed to you and given http access. There is the same flaw as in Digits, - you need to understand what to do. It is your case that may “not converge” or simply require an unusual approach to recognition. In general, the solution is excellent if you have a fairly standard problem, with well separable objects that need to be classified.
- Companies that solve exactly your problem with their tools. There are not many such companies. In reality, I would only refer them to CrowdFlower. Here, for reasonable money, they will plant markers, select a manager, deploy their servers, where they will launch your models. And for more serious money they will be able to change or optimize their decisions for your task.
They work with large companies - ebay, oracle, tesco, adobe. Judging by their openness, they successfully interact with small companies.
How does this differ from the development under the order, which does, for example, EPAM? The fact that everything is ready here. 99% of the solution is not written, but is assembled from ready-made modules: data markup, network selection, training, scanning. Companies that develop under the order, do not have such a speed, the dynamics of the scanning solutions, ready-made infrastructure. We believe that the trend and approach that CrowdFlower outlined is true.
What tasks does it work for?
Perhaps 70% of tasks are automated in this way. The most appropriate tasks are various recognitions of areas containing text. For example, car license plates, about which we
have already spoken , train numbers (
here is our example of two years ago ), inscriptions on containers.

Many symbolic technical information is recognized in factories to account for products and their quality.
This approach is very helpful in recognizing products on the shelves of stores and price tags, although there it is necessary to create quite complex recognition solutions.

But, you can distract from the tasks with technical information. Any semantics, be it instance segmentation, with detection of cars, argali, moose and sea lions will also be excellent for such an approach.

A very promising direction is to maintain communication with people in voice and text chat bots. There will be a rather unusual way of marking: the context, the type of phrase, its “content”. But the principle is the same: we work in automatic mode, a person controls the correctness of understanding and answers. You can resort to the help of the operator in case of dissatisfied or irritated customer tone. With the accumulation of data retrain.
How to work with video?
If you or within your company have the necessary competences (some experience in Machine Learning, working with the zoo frameworks, both offline and online), then there will be no difficulty in solving simple computer vision tasks: segmentation, classification, text recognition and other
But for the video is not so smooth. How generally to mark these infinite data volumes? For example, it may be that every few seconds an object (or several objects) appears in the frame that needs to be laid out. As a result, all this can turn into a frame-by-frame view and takes so many resources that a person doesn’t even have to say about additional control by a person after launching a solution. But this can be overcome if we present the video in the correct form in order to highlight frames with areas of interest.
For example, we are faced with huge video series in which it was necessary to single out a single specific object - a hitch of railway platforms. And it was really not easy. It turned out that everything is not so bad, if we take the monitor wider, choose a frame rate, for example 10FPS and place 256 frames on one image, i.e. 25,6s in one image:

It probably looks scary. But in fact, it takes about 15s to click through to every single frame, choosing the center of the car’s coupling on the frame. And even one person in a day or two can mark at least 10 hours of video. Get more than 30 thousand examples for learning. In addition, the passage of the platforms in front of the camera in this case is not a constant process (and quite a rare one, it should be noted), it is quite realistic even in real time to correct the recognition machine, adding to the training base! And if recognition occurs in most cases, then an hour of video can be overcome in a couple of minutes. And then to neglect the total control by the person, as a rule, is not economically profitable.
It is still easier if the video should be marked “yes / no”, and not the localization of the object. After all, events are often “stuck together”, and with one stroke of the mouse you can mark up to 16 frames at a time.
The only thing you usually have to use is 2 stages when analyzing a video: searching for “frames or areas of interest”, and then working with each such frame (or sequence of frames) by other algorithms.
Machine-human economy
How much can you optimize the cost of processing visual data? One way or another it is strictly necessary to have a person to control data recognition. If this control is selective, then the costs are insignificant. But if we are talking about total control, then how can it be profitable? It turns out that this makes sense almost always, if before a person performed the same task without the help of a machine.
Take not the best example given at the very beginning: searching for a pizza in an image, marking and choosing a type (and in reality a number of other characteristics). Although, the task is not as synthetic as it may seem. The control of the appearance of the products of franchise networks in reality does exist.
Suppose that for recognition using a server GPU you need 0.5s of computer time, for a full frame marking by a person about 10s (choose the type of pizza and its quality by a number of parameters), and to check whether everything is correctly determined by the computer, you will need 2s. Of course, there will be a challenge in how convenient it is to present these data, but such times are quite comparable with our practice.
Looking for some more introductory cost of manual markup and rental server GPU. Count on a full server load, as a rule, is not necessary. Let it be possible to achieve a load of 100,000 frames per day (it takes 60% of the computing power of one GPU) with an estimated cost of a monthly server rental of 60,000 rubles. It turns out 2 pennies for the analysis of one frame on the GPU. A manual analysis at a cost of 30 000r for 40 hours of working time will cost 26 kopecks per frame.
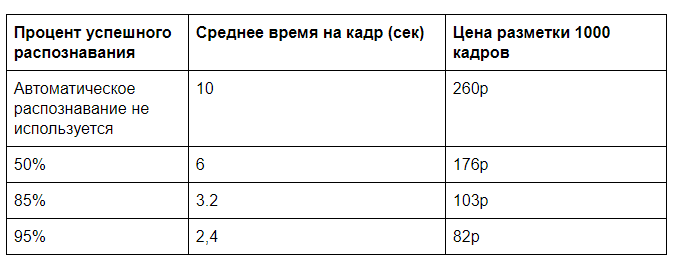
And if you subsequently remove the total control, then you will be able to achieve prices of almost 20p per 1000 frames. If there is a lot of input data, you can optimize recognition algorithms, work on data transfer and achieve even greater efficiency.
In practice, unloading a person as the recognition system is trained has another important meaning - it makes it much easier to scale your product. A significant increase in the amount of data allows for better training of the recognition server, and the accuracy is improved. And the number of employees involved in data processing will not increase in proportion to the amount of data, which will significantly simplify the growth of the company from an organizational point of view.
As a rule, the more text and contour selection you have to enter manually, the more advantageous is the use of automatic recognition.
And that changes everything?
Of course, not all. But now some lines of business are not as insane as they used to be.
Want to do offline service without a person at the facility? Land the operator remotely and follow
on cameras for each client? Get a little worse than a living person on the spot. Yes, and operators need almost more. And if you unload the operator every 5? This may be a beauty salon without a reception, and control of production, and security systems. 100% accuracy is not required - it is possible to completely exclude the operator from the chain.
It is possible to organize fairly complex accounting systems for existing services to improve their efficiency: control of passengers, vehicles, time of service, where there is a risk of “bypassing” cash, etc.
If the task is at the current level of computer vision development and does not require completely new solutions, then this will not require serious investments in development.