 Author: Igor Masternoy, Senior Developer, leader of the DataArt Java community
Author: Igor Masternoy, Senior Developer, leader of the DataArt Java communityOn May 18–19, JEEconf took place in Kiev - one of the most awaited events for the entire Java-community of Eastern Europe. DataArt became a conference partner. Speakers from all over the world performed on four stages: Volker Simonis - SAP representative at
JCP and OpenJDK contributor, Jürgen Höller - Chief Engineer of Pivotal, father of the beloved Spring Framework, Klaus Ibsen creator Apache Camel, and Hugh McKee - an evangelist in Lightbend.
The schedule was very intense: in two days more than 50 speeches, 45 minutes each. 10 minutes break - and run to the new report. It will take a lot of time to watch all the videos when they appear online. Therefore, I will briefly describe the reports that I found most interesting and which I personally visited.
15 years of Spring
The conference was opened by Jürgen Höller. He spoke about the 15-year-old (!) History of the Spring Framework, starting with the “favorite” XML configs in version 0.9 and ending with the reactive Spring WebFlux, which emerged from research projects influenced by
Reactive Manifesto . Jürgen talked about the coexistence of Spring MVC and Spring WebFlux in the Spring WEB, explaining why they decided not to merge into one. The fact is that the main abstraction of Spring MVC is Servlet API 3.0 and blocking IO, whereas in Spring WebFlux the abstraction of Reactive Streams and non-blocking IO is used. You can run your SpringWebFlux service on any server that supports non-blocking IO: Netty, new versions of Tomcat (> 8.5), Jetty. Creating WebFlux jet controllers is not much different from creating them using Spring MVC, but there are some differences. When processing a user request, the reactive controller does not process it in the usual sense, but creates a pipeline for processing the request. Dispatcher calls the controller method, which creates a pipeline and immediately returns it as a publisher stream. Publisher stream in Reactive Spring is presented in the form of two abstractions: Flux / Mono. Flux returns a stream of objects, and Mono always a single object.
Jürgen also mentioned the ease of use of Java 8-style when working with Spring 5.0 and promised a release candidate Spring 5.1 in July 2018 and a release in September, which will support Java 11 and work on fine tuning new features for Spring 5.0
Python / Java integration
There were a lot of reports, and it was difficult to choose the most interesting one in the next slot. The descriptions were equally interesting, so I trusted my instincts and decided to listen to Tamas Rozman, vice president of BlackRock from Hungary. But it would be better to once again listened to the Events Sourcing and CQRS. Judging by the description, the company is engaged in Data Science for a large investment fund. The purpose of the report was to show how they created a scalable, stable system that was equally convenient for both data analysts with their Python and Java developers of the main system. However, it seemed to me doubtful that the constructed system really turned out to be convenient. To make friends with Python and Java, engineers at BlackRock came up with the idea of running a Python interpreter as a process from a Java application. They came to this for several reasons:
- Jython (Python on JVM) did not work due to outdated code base 2.7 vs Python 3.6.
- The option to rewrite the logic of Data Science in Java, they found the process too long.
- Apache Spark decided not to take, because, as the speaker explained, you cannot mix Jobs written in Java and Python. Although it is not entirely clear why UDF and UDFA did not fit [ 2 ]. Also, Spark did not fit, because they already had some kind of job framework, and it was not very desirable to introduce a new one. And, as it turned out, they also don’t have Big Data, and all processing is reduced to statisticians over a measly 100 MB files.
Communication from Java with the Python process was organized using memory mapped files (one file is used as the input data file) and commands (the second file is the output of the Python process). Thus, communication represented something in the form:
Java: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
Java: 1 + success | 64
Python: success | 65
The main problems of such integration Tamas called the overhead during serialization and de-serialization of input / output parameters.

Java 10 App CDS
After a report on the intricacies of running Python, I really wanted to listen to something deeply technical from the world of Java. Therefore, I went to the report of Volker Simonis, in which he spoke about the feature of Application class data sharing from
Java 10+ . In the modern world built on microservices in Docker, the ability to share Java Codecache and Metaspace speeds up the launch of an application and saves memory. In the picture, the results of launching dock-operated tomkats with a common / shared archive of Tomcat classes. As you can see, for the second process, a certain amount of pages in memory is already marked as shared_clean - this means that the current one and at least one more process (the second started volume) refers to them.

Details on how to play with CDS in OpenJDK 10 can be found at:
App CDS . In addition to dividing / sharing application classes between processes, in the future, it is also planned to share interned strings in
JEP-250 .
The main limitations of AppCDS:
Does not work with classes up to 1.5.
- Classes loaded from files cannot be used (.jar archives only).
- It is impossible to use classes modified by the classifier.
- Classes loaded with multiple class loaders can only be reused once.
- Byte-code rewriting does not work, which can lead to a drop in performance of up to 2%. JDK-8074345

Natural language processing pipeline with Apache Spark
A report on NLP and Apache Spark was presented by Vitaliy Kotlyarenko, an engineer from Grammarly. Vitaly showed how Grammarly prototyped NLP-jobs on Apache Zeppelin. An example was the construction of a simple pipeline for thematic modeling based on the
LDA algorithm of the
common crawl Internet archive. The results of thematic modeling were used to filter sites with unwanted content as an example of the parental control function. To create the pipeline, they used the Terraform scripts and the
AWS EMR Spark cluster, which allows you to deploy Spark Cluster with YARN in Amazon. Schematically, the pipeline looks like this:
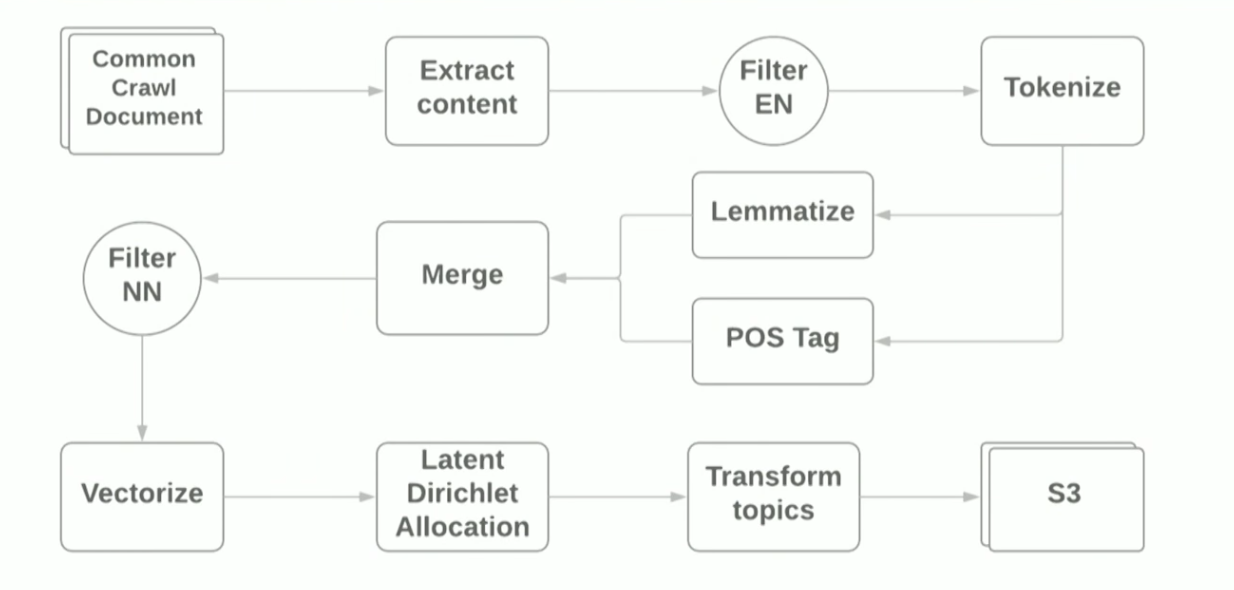
The purpose of the report was to show that using modern frameworks to make a prototype for ML tasks is quite simple, however, using standard libraries, you still run into difficulties. For example:
- At the very first step of reading the WARC files using the HadoopInputFormat library , sometimes IllegalStateExceptions crashed due to incorrect file headers and I had to rewrite the library and skip the incorrect files.
- The dependencies on the guava - the language definition library - clashed with the dependencies that Spark was pulling. Java 8 helped, with the help of which it turned out to throw away the dependencies on guava in the library used.
During the demo, we monitored the execution of the job using the standard Spark UI and the monitoring subsystem
Ganglia , which is automatically available when deployed on AWS EMR. The author focused on the heat map Server Load Distribution, which shows the distribution of the load between the nodes in the cluster, and gave general tips on how to optimize Spark Job work: increasing the number of partitions, optimizing data serialization, analyzing GC logs. Read more about optimizing Spark Jobs
here . Source files for the demo can be found in the
report author's
githaba .
Graal, Truffle, SubstrateVM and other perks:
The most awaited for me was the report of Oleg Chirukhin from JUG.ru. He told how to optimize the ready-made code with the help of the Grail. What is the Grail? Grail is a brand of
Oracle Labs , which combined the JIT (just-in-time) compiler, the DSL language writing framework - Truffle - and the special JVM (
SubstrateVM ) - the universal
Closed-world virtual machine, which you can write to in JavaScript, Ruby, Python, Java, Scala. The report focused on the JIT compiler and its testing in production.
To begin, let us recall the process of executing code by the Java machine and note that there are already two compilers in Java: C1 (Client compiler) and C2 (Server Compiler). Grail can be used as a C2 compiler.
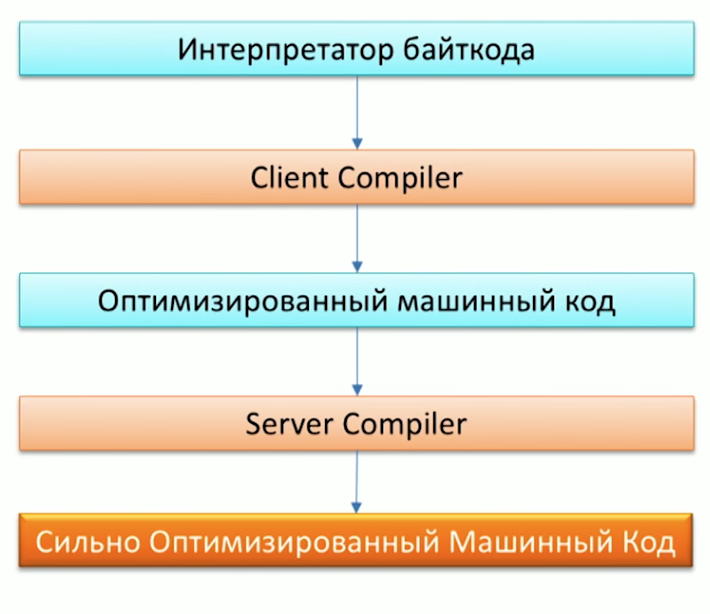
When asked why we need another compiler, one of the employees of Oracle Labs, Dr. Chris Seaton, very well answered in the article
Understanding How Graal Works . In short, the original idea of the Graal project, like the
Metropolis project, is to rewrite parts of the JVM code written in C ++ in Java. This will give an opportunity to further conveniently add code. For example, one of the optimizations - P
artial Escape Analysis - is already in the Grail, but not in Hotspot -
because extending the Grail code is much simpler than the C2 code .
It sounds great, but how will this work in practice in my project, you ask? Grail is suitable for projects:
- That trash a lot, creating a lot of small objects.
- Written in the style of Java 8, with a bunch of streams and lambdas.
- Using different languages: Ruby, Java, R.
One of the first in the production of the Grail began to use Twitter. You can read more about this in an interview with Christian Talinger, who came out on Habré (
interview_1 and
interview_2 ). There, he explains that, by replacing C2 with Graal, Twitter started saving about 8% of CPU utilization, which is very good, given the scale of the organization.
At the conference, we were also able to verify the speed of Graal by running one of the Scala benchmarks,
Scala DaCapo , under it. As a result, the Graal Bench went for ~ 7000 ms, and on a regular JVM for ~ 14000 ms! Why this happened, you can see by looking at the gclog tests. The number of Allocation failure when using Graal is significantly less than that of Hotspot. However, it is still impossible to say that the Grail will be a solution to the performance problems of your Java application. Oleg in the report showed the history of failure, comparing the work of
Apache Ignite under the Grail and without it - there was no noticeable change in performance.

Designing Fault Tolerant Microservices
Orhan Gasimov from AppsFlyer read the next report on the fault-tolerant microservice architecture. He presented popular design patterns for building distributed applications. Many of them, we may well know, but once again walk and remember about each of them does not hurt.
The main problems of the resiliency of services that the patterns described in the report are designed to fight against are: network, peak loads, RPC-mechanisms for communication between services.
To solve problems with the network, when one of the services is no longer available, we need the ability to quickly replace it with another one. In practice, this can be achieved by using multiple instances of the same service and describing alternative paths to these instances, which is a
Service Discovery pattern. Engage
heartbeat services and register new services will be a separate instance - Service Registry. As a Service Registry, it is customary to use the well-known
Zookeeper or
Consul . Which, in turn, also have a distributed nature and support for resiliency.
Having solved the problems with the network, we turn to the problem of peak loads, when some services are under load and are processing requests much slower than normal. To solve it you can use
Auto-scaling -pattern. It will undertake not only the tasks of automatic scaling of high-load services, but also the stopping of instances after the end of the peak load period.
The final chapter of the author's report was a description of the possible problems of RPC internal inter-service communication. Urakhan paid particular attention to the thesis "The user should not wait for an error message for a long time." This situation may arise if its request is processed by a chain of services, and the problem is at the end of the chain: accordingly, the user can wait for the request to be processed by each of the services in the chain and only at the last stage receives an error. Worst of all, if the final service is overloaded, and after a long wait, the client will receive a meaningless HTTP-ERROR: 500.
Timeout s can be used to deal with such situations, however, requests that can still be correctly processed can get into the timeout. For this, the timeout logic can be complicated and add a special threshold value for the number of service errors during the time interval. When the number of errors exceeds the threshold, we understand that the service is under load and we consider it unavailable, giving it the necessary time to cope with current tasks. This approach describes the
Circuit Breaker pattern. You can also use CircuitBreaker.html "> Circuit Beaker as an additional monitoring metric that allows you to quickly respond to potential problems and clearly identify which service chains they are experiencing. To do this, you need to wrap each service call into Circuit Breaker.
Also in the report, the author recalled the
N-Modular redundancy pattern, designed to "process requests faster, if possible," and cited a beautiful example of its use for validating the client's address. A request in their system through the cache of addresses was sent immediately to several Geo Map-providers, as a result of which the fastest answer was won.
In addition to the patterns described, the following were mentioned:
- Fast Path pattern , which can be applied, for example, when caching query results. Then cache access - fast path.
- The Error Kernel pattern is a pattern from the Akka world which involves dividing the task into subtasks and delegating the subtasks to downstream actors. Thus, the flexibility of processing subtask execution errors is achieved.
- Instance Healer , which assumes the presence of a special service - a supervisor who manages other services and reacts to changes in their condition. For example, in case of errors in the service, the supervisor can restart the problem service.

Clustered Event Sourcing and CQRS with Akka and Java
The last report to which I want to draw your attention, read one of the evangelists and architects of the company Lightbend Hugh McKee. Lightbend (formerly Typesafe) is something like Oracle, but for the Scala language. The company is also actively developing the
Akka.io framework. In the report, Hugh spoke about the implementation of the popular
CQRS (Command Query Responsibility Commands / SEGREGATION) approach on the Akka framework. Schematically, the CQRS system architecture looks like this:
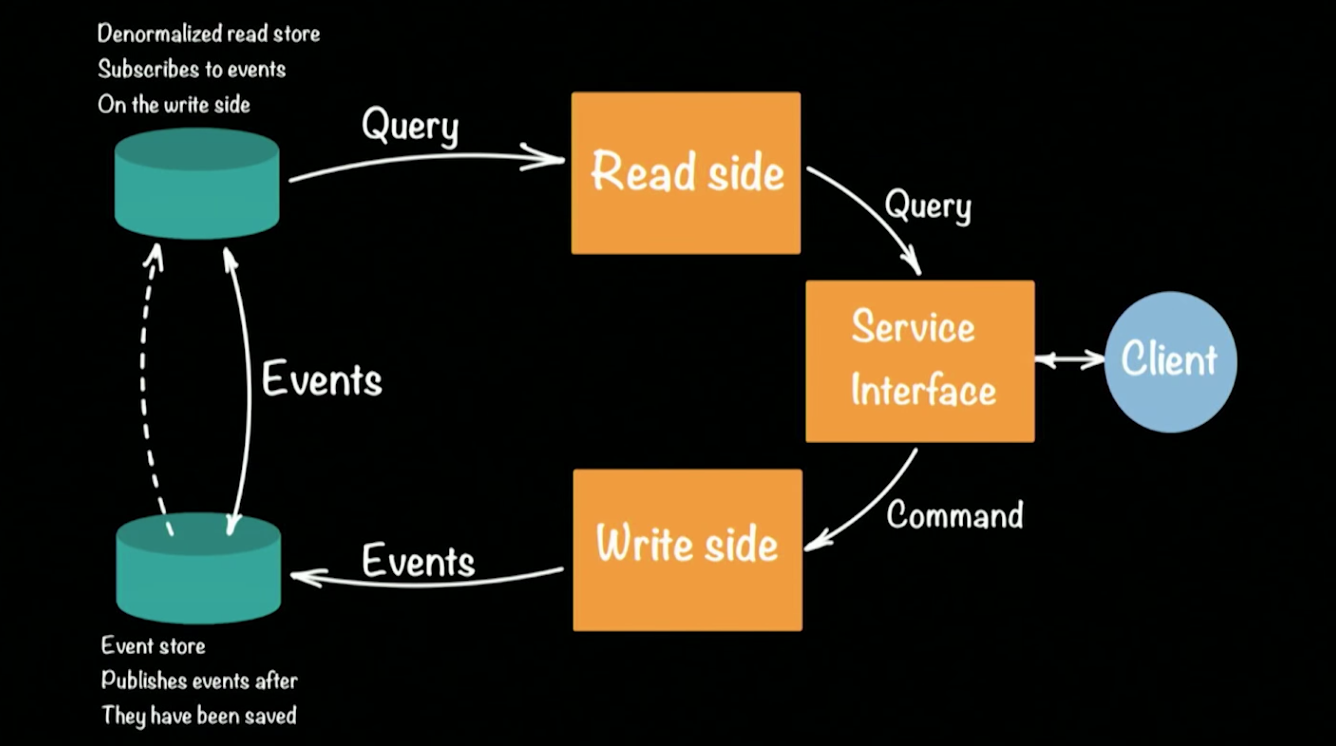
As an example of a working system, Hugh took the prototype of the bank. The client in the CQRS architecture performs two operations: query, command. Each team (for example, a bank transaction for transferring money from one account to another) generates an event (an accomplished fact) that will be recorded in the EventStore (for example: Cassandra). Aggregation of the chain (put money into the account, transfer from the account to the account, withdraw at the ATM) of events forms the current state of the client, his balance of money in the account. Current status requests go to a separate repository, a certain snapshot of event repositories, since storing the complete history of a bank account is meaningless. It is enough to periodically update the status snapshot for each user.
This approach makes it possible to automatically recover when errors occur: for this we need to get the last impression of the user's state and apply to it all the events that occurred before the error occurred. Due to the presence of two repositories, the CQRS architecture tolerates the spikes that occur well. A large number of events will load the Event Store, but will not affect the Read Store, and users will still be able to execute queries into the database.
Returning to prototyping the banking system on Akka and CQRS. Each bank client / account / possible team in the system will be represented by one (!)
Actor . A large bank can support hundreds of thousands of accounts, and this will not be a problem for Akka. The out-of-box framework supports clustering and can be run on hundreds of JVMs. If one of the machines in the cluster fails, Akka provides special mechanisms that allow you to automatically respond to such situations: in our case, the client's actor can be recreated again on any available machine in the cluster, and its state will be re-read from the storage.
Under the actor, a separate stream is not created - this makes it possible to support tens of thousands of actors within one JVM. In this case, the actor guarantees that each request will be processed separately (!) In the order of receipt of requests. This guarantee automatically eliminates possible race conditions when processing requests. You can get a better understanding of the prototype of the system by opening its code by reference in GitHub. Each subproject shows the implementation of the most difficult stages of building a prototype:
wasps.
Records of all reports will appear online within a few weeks. I hope that this article will help you decide on the order of viewing, especially since I think it's worth watching the performances.