Greetings dear community!
Repetition is the mother of learning, and to understand the syntactic analysis is a very useful skill for any programmer, so I want to raise this topic again and talk this time about the analysis by the method of recursive descent (LL), without extra formalisms (they can always be return).
As the great D. Strogov writes, “to understand is to simplify.” Therefore, in order to understand the concept of syntactic parsing by the method of recursive descent (it is LL parsing), we simplify the task as much as possible and manually write a parser format similar to JSON, but simpler (if you wish, you can then expand it to a full JSON parser, if want to exercise). We will write it, based on the idea of
cutting a string .
In classic books and courses on compiler construction, they usually begin to explain the topic of syntactic analysis and interpretation, highlighting several phases:
- Lexical analysis: splitting the source text into an array of substrings (tokens, or tokens)
- Syntax analysis: building a parse tree from an array of tokens
- Interpretation (or compilation): traversing the resulting tree in the correct (direct or reverse) order and performing some actions on interpreting or code generation at some steps of this traversal
really not exactlybecause in the process of parsing we get a sequence of steps, which are a sequence of visits to the nodes of the tree, the tree itself in the explicit form may not be at all, but we will not go deeper. For those who want to go deep, there are links at the end.
Now I want to use a slightly different approach to the same concept (LL parsing) and show how to build an LL analyzer, based on the idea of cutting a line: fragments are cut off from the original line, it becomes smaller, and then parse exposed the rest of the string. As a result, we will come to the same concept of recursive descent, but in a slightly different way than is usually done. Perhaps this way will be more convenient for understanding the essence of the idea. And if not, then it is still an opportunity to look at a recursive descent from a different angle.
Let's start with a simpler task: there is a string with delimiters, and I want to write an iteration on its values. Sort of:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
How can I do that? The standard way is to convert a delimited string to an array or list using String.split (in Java), or names.split (",") (in javascript), and iterate over the array. But let us imagine that we don’t want to use the conversion to an array (or, for example, if we program in the AVAJ ++ programming language, which doesn’t have an “array” data structure). You can still scan the string and track delimiters, but I will not use this method either, because it makes the loop iteration code cumbersome and, most importantly, it goes against the concept I want to show. Therefore, we will refer to a delimited string in the same way that lists are used in functional programming. And there the functions head (get the first element of the list) and tail (get the rest of the list) are always defined for them. Starting from the first lisp dialects, where these functions were called completely awful and non-intuitive: car and cdr (car = content of address register, cdr = content of decrement register. Old times, yes, eheheh.).
Our line is a delimited string. Highlight the separators with purple:
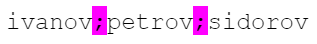
And the elements of the list are highlighted in yellow:

We assume that our string is mutable (it can be changed) and write the function:
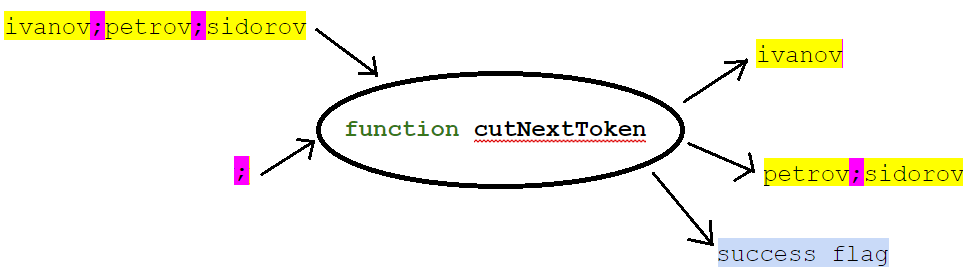
Its signature, for example, might be:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
At the input of the function we give a list (as a string with delimiters) and, in fact, the value of the separator. At the output, the function returns the first element of the list (a line segment to the first separator), the rest of the list, and a sign if the first element could be returned. In this case, the rest of the list is placed in the same variable as the original list.
As a result, we were able to write this:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Displays, as expected:
ivanov
petrov
sidorov
We did without converting to ArrayList, but then we corrupted the names variable, and now it has an empty string. It looks so far not very useful, as if they changed the awl on the soap. But let's move on. There we will see why it was necessary and where it will lead us.
Let's now sort out something more interesting: a list of key-value pairs. This is also a very frequent task.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Conclusion:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
Also expected. And the same can be achieved with String.split, without cutting lines.
But suppose that now we wanted to complicate our format and move from a flat key-value to a format that allows nesting resembling JSON. Now we want to read something like this:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
Which splitter should split? If by comma, then in one of the tokens we will have a string
'birthdate':{'year':'1984'
Clearly not what we need. Therefore, we must pay attention to the structure of the line we want to parse.
It starts with a curly bracket and ends with a curly bracket (pair to it, which is important). Inside these brackets is a list of pairs of 'key': 'value', each pair is separated from the next pair by a comma. The key and value are separated by a colon. The key is a string of letters enclosed in apostrophes. The value may be a string of characters enclosed in apostrophes, or it may be the same structure, starting and ending with paired braces. Let's call such a structure the word “object”, as it is usually called in JSON.
We have just described the grammar of our format, which resembles JSON, informally. Usually grammars are described on the contrary, in a formal form, and BNF-notation or its variations are used to write them. But now I’ll do without it, and we’ll just see how this string can be “cut” so that it can be disassembled according to the rules of this grammar.
In fact, our “object” begins with an opening brace and ends with a pair of closing brace. What can a function parse such a format? Most likely, the following:
- check that the passed string starts with an opening brace
- check that the passed string ends with a pair of closing brace
- if both conditions are true, cut the opening and closing parenthesis, and transfer what is left to the function that parses the list of pairs 'key': 'value'
Please note: the words “function that parses such a format” and “function that parses the list of pairs 'key': 'value'” have appeared. We have two functions! These are the same functions that are called “parse nonterminal symbol functions” in the classical description of the recursive descent algorithm, and which says that “for each nonterminal symbol its own parse function is created”. Which, in fact, it parses. We could name them, say, parseJsonObject and parseJsonPairList.
Also now we need to note that we have the concept of a “pair bracket” in addition to the concept of a “separator”. If for cutting the line to the next delimiter (a colon between the key and value, a comma between the key: value pairs), the cutNextToken function was enough for us, now, when we can act as a value not only a line, but also an object, we will need the function “cut to the next pair bracket”. Something like this:

This function cuts a fragment from the string from the opening bracket to the pair to it closing, taking into account the nested brackets, if any. Of course, it is possible not to be limited to brackets, but to use a similar function for cutting off various block structures admitting nesting: operator blocks begin..end, if..endif, for..endfor and similar to them.
Draw graphically what will happen to the string. Turquoise - this means we scan the line forward for the character highlighted in turquoise to determine what to do next. Violet is “what to cut off, this is when we cut off fragments from the string, marked purple, and what is left, we continue to disassemble further.

For comparison, the output of the program (the text of the program is given in the Appendix), which parses this line:
Demonstration of parsing JSON-like structure
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
We know at any time what we expect to find in our input line. If we enter the parseJsonObject function, we expect that an object was passed to us there, and we can check this by the presence of an opening and closing bracket at the beginning and end. If we enter the parseJsonPairList function, we expect a list of “key: value” pairs, and after we “bite off” the key (before the separator “:”), we expect the next thing that we “bite off” is value. We can look at the first character of the value, and make a conclusion about its type (if the apostrophe is, then the value is of the type “string”, if the opening brace is, then the value is of the type of “object”).
Thus, cutting off fragments from a string, we can perform its syntactic analysis using the method of downward analysis (recursive descent). And when we can parse, we can parse the format we need. Or invent your own convenient format and disassemble it. Or come up with a DSL (Domain Specific Language) for our specific area and construct an interpreter for it. And construct correctly, without forced decisions on regexps or self-made state-machines, which arise for programmers who are trying to solve some problem that requires syntactic analysis, but do not quite own the material.
Here it is. Congratulations to all on the coming summer and I wish you good, love and functional parsers :)
For further reading:
Ideological: a couple of long but worthwhile articles by Steve Jegge (eng.):
Rich Programmer FoodA couple of quotes from there:
DSLs, or you get a better language
The first big phase of the compilation pipeline is parsing.
The pinocchio problemQuote from there:
It is clear that there is a possibility to make , because (they don't know) they are actually hardware.
Technical: two articles on syntactic analysis, on the difference between LL and LR-approaches (English):
LL and LR Parsing DemystifiedLL and LR in Context: Why Parsing Tools Are HardAnd even deeper into the topic: how to write a Lisp interpreter in C ++
Lisp interpreter in 90 lines of C ++Application. An example of a program code (java) implementing the analyzer described in the article: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {