
Most likely, you have already heard about the Go programming language, its popularity is constantly growing, which is quite reasonable. This language is simple, fast and relies on a wonderful community. One of the most curious aspects of the language is the multithreaded programming model. The primitives on which it is based make it possible to create multi-threaded programs easily and simply. This article is intended for those who want to explore these primitives: gorutiny and channels. And, through the illustrations, I will show you how to work with them. I hope this will be a good help for you in further study.
Single-threaded and multi-threaded programs
You have probably already written single-threaded programs. Usually it looks like this: there is a set of functions for performing various tasks, each function is called only when the previous one has prepared data for it. Thus, the program works sequentially.
This will be our first example - the mining program. Our functions will search, mine and process ore. In our example, ore in the mine is represented by lists of strings, functions take them as parameters and return a list of “processed” strings. For a single-threaded program, our application will be designed as follows:
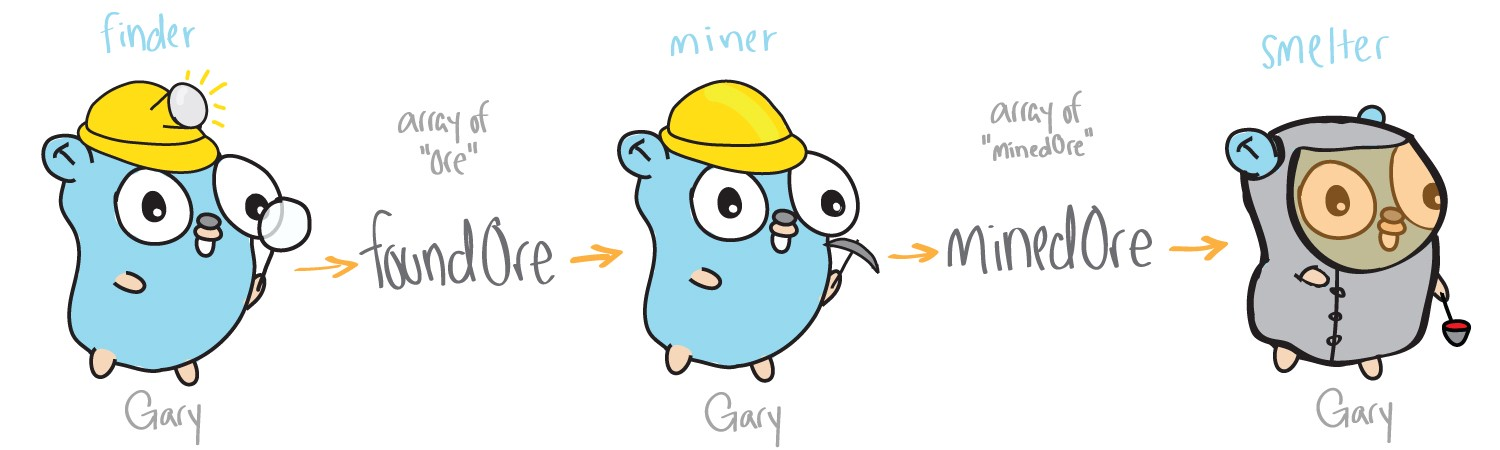
In this example, all work is performed by one stream (Gary gofer). Three main functions: search, extraction and processing are performed sequentially one after another.
func main() { theMine := [5]string{"rock", "ore", "ore", "rock", "ore"} foundOre := finder(theMine) minedOre := miner(foundOre) smelter(minedOre) }
If you print the result of each function, we get the following:
From Finder: [ore ore ore] From Miner: [minedOre minedOre minedOre] From Smelter: [smeltedOre smeltedOre smeltedOre]
Simple design and implementation is the advantage of a single-stream approach. But what if you want to run and execute functions independently of each other? This is where multithreaded programming comes to your rescue.
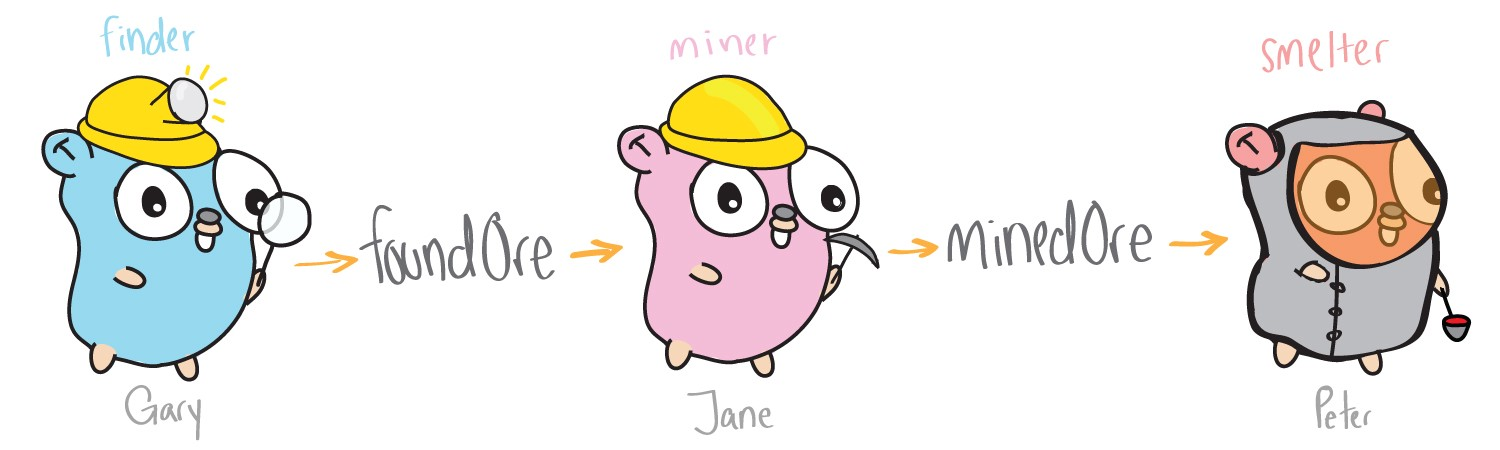
This approach to the extraction of ore is much more efficient. Now several threads (gophers) work independently, and Gary does only part of the work. One gopher searches for ore, another mines, and the third melts, and all this is potentially simultaneously. In order to implement this approach, in the code we need two things: to create gofer-processors independently of each other and transfer ore between them. In Go for this there are gorutiny and channels.
Gorutiny
Gortuins can be thought of as "lightweight threads"; to create a gorutin, you just need to put the
go keyword before the function call code. To demonstrate how easy it is, let's create two search functions, call them with the
go keyword and type a message every time they find “ore” in their mine.

func main() { theMine := [5]string{"rock", "ore", "ore", "rock", "ore"} go finder1(theMine) go finder2(theMine) <-time.After(time.Second * 5)
The output of our program will be as follows:
Finder 1 found ore! Finder 2 found ore! Finder 1 found ore! Finder 1 found ore! Finder 2 found ore! Finder 2 found ore!
As you can see, there is no order in which function will first find ore; Search functions work simultaneously. If you run the example several times, the order will be different. Now we can run multi-threaded (multi-area) programs, and this is a serious progress. But what to do when we need to establish a connection between the independent Gorutines? It's time for the magic channels.
Channels
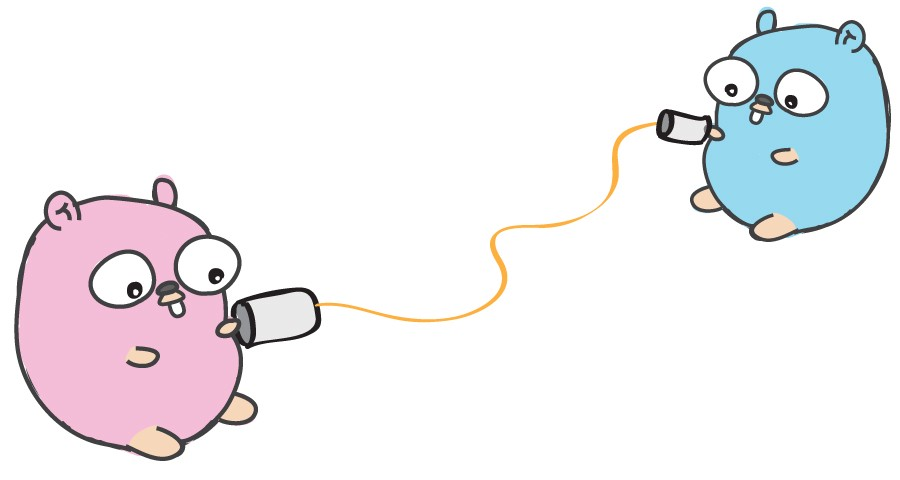
Channels allow gorutinami to share data. This is a kind of pipe through which the gorutins can send and receive information from other gorutins.
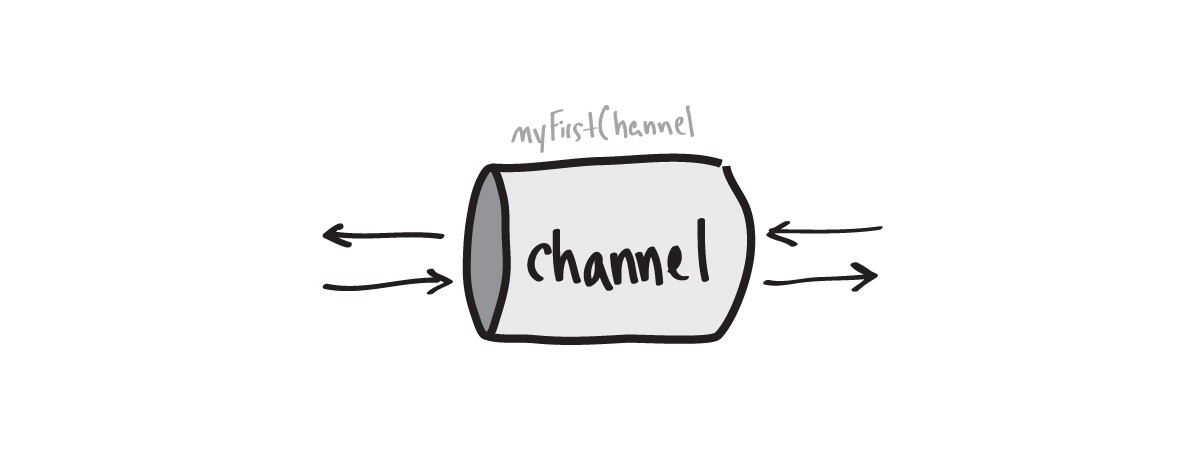
Reading and writing to the channel is carried out using the operator-arrow (<-), which indicates the direction of movement of the data.

myFirstChannel := make(chan string) myFirstChannel <- "hello"
Now our scout hogher does not need to accumulate ore, he can immediately transfer it further using channels.
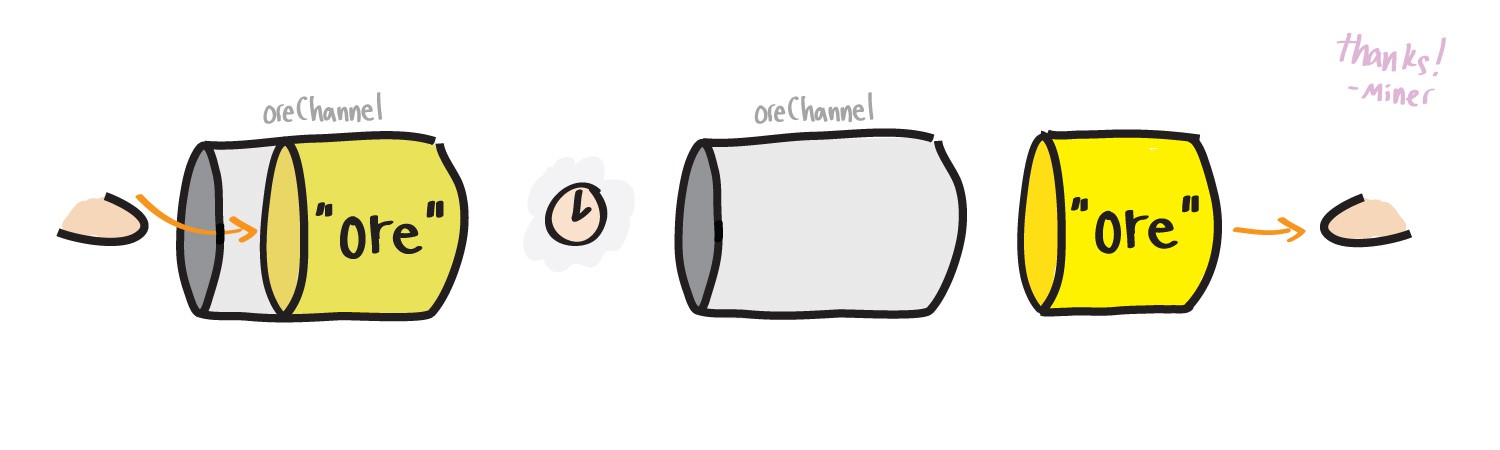
I updated the example, now the code for the seeker and the miner is anonymous functions. Do not bother too much if you have not encountered them before, just keep in mind that each of them is invoked with the keyword
go , therefore, it will be executed in its own gorutin. The most important thing here is that the gorutines transmit data among themselves using the
oreChan channel. And with anonymous functions, we will understand closer to the end.
func main() { theMine := [5]string{“ore1”, “ore2”, “ore3”} oreChan := make(chan string)
The output below vividly demonstrates that our Grainer receives three portions of the ore one time at a time from the channel.
Miner: Received ore1 from finder Miner: Received ore2 from finder Miner: Received ore3 from finder
So, now we are able to send data between different gorutinami (goferov), but before you start writing a complex program, let's deal with some important properties of channels.
Locks
In some situations, when working with channels, Gorutin may be blocked. This is necessary so that the gorutines can synchronize with each other before they start or continue working.
Lock on Write
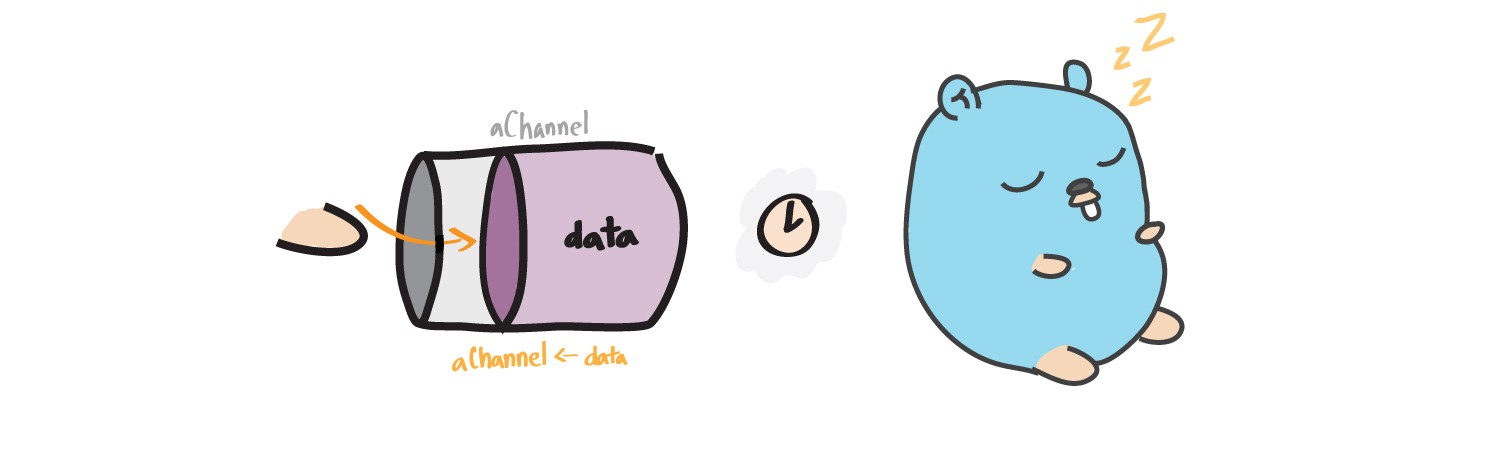
When a gorutin (gofer) sends data to a channel, it is blocked until another gorutin reads data from the channel.
Read lock
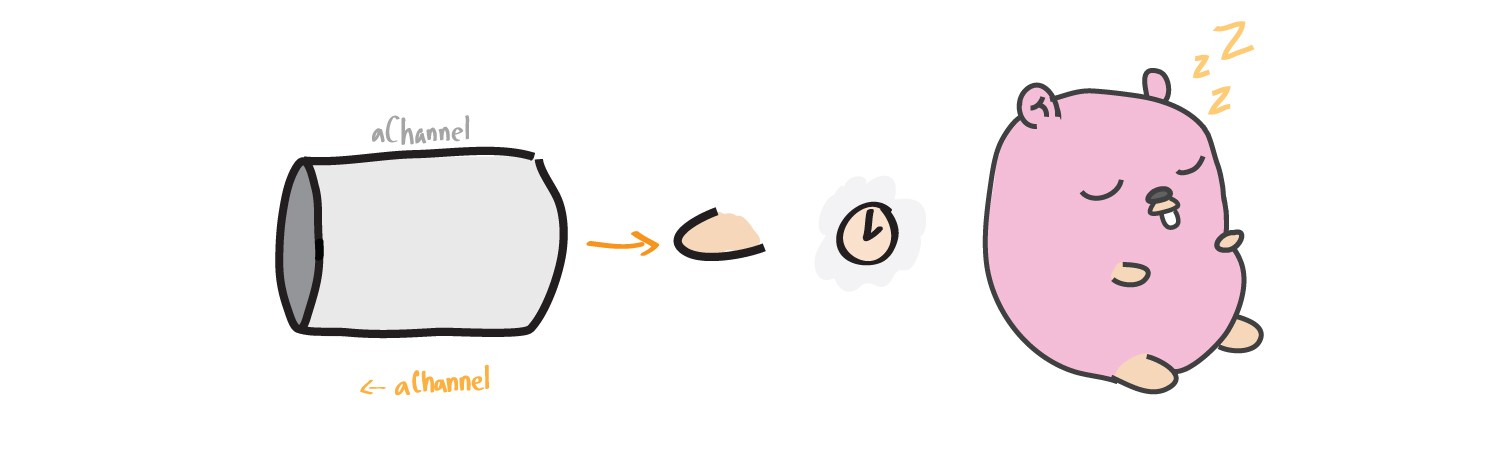
Similar to blocking when writing to a channel, a gorutin can be blocked when reading from a channel until it is recorded in nothing.
If locks, at first glance, seem to you to be something complicated, you can imagine them as a “transfer of money” between two Gorutinas (gophers). When one goffer wants to transfer or receive money, he has to wait for the second participant in the transaction.
Having dealt with the gorutin blocking on the channels, let's discuss two different types of channels: buffered and unbuffered. Choosing one or another type, we largely determine the behavior of the program.
Unbuffered Channels
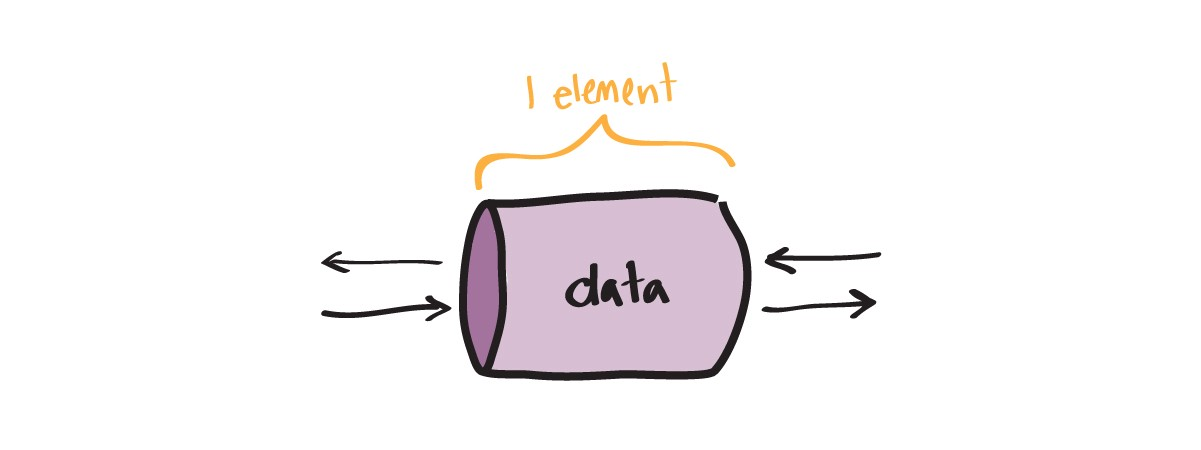
In all the previous examples we used such channels. Only one piece of data can be transmitted over such channels (with blocking, as described above).
Buffered Channels

The threads in the program may not always be perfectly synchronized. For example, in our example, it happened that the gopher intelligence officer found three parts of ore, and the goffer miner managed to extract only one part of the found reserves during the same time. This is to ensure that the intelligence officer does not spend most of his time waiting for the miner to finish his work, we will use buffered channels. Let's start by creating a channel with a capacity of 3.
bufferedChan := make(chan string, 3)
We can send several data fragments to a buffered channel without having to read them with another gorutina. This is the main difference from unbuffered channels.

bufferedChan := make(chan string, 3) go func() { bufferedChan <- "first" fmt.Println("Sent 1st") bufferedChan <- "second" fmt.Println("Sent 2nd") bufferedChan <- "third" fmt.Println("Sent 3rd") }() <-time.After(time.Second * 1) go func() { firstRead := <- bufferedChan fmt.Println("Receiving..") fmt.Println(firstRead) secondRead := <- bufferedChan fmt.Println(secondRead) thirdRead := <- bufferedChan fmt.Println(thirdRead) }()
The order of output in such a program will be as follows:
Sent 1st Sent 2nd Sent 3rd Receiving.. first second third
To avoid unnecessary complications, we will not use buffered channels in our program. But it is important to remember that these types of channels are also available for use.
It is also important to note that buffered channels do not always relieve you of locks. For example, if a reconnaissance goffer is ten times faster than a miner-miner and they are connected through a buffered channel of capacity 2, then the reconnaissance goffer will be blocked each time it is sent, if there are already two data fragments in the channel.
Putting it all together
So, armed with gorutinami and channels, we can write a program, using all the advantages of multi-threaded programming in Go.
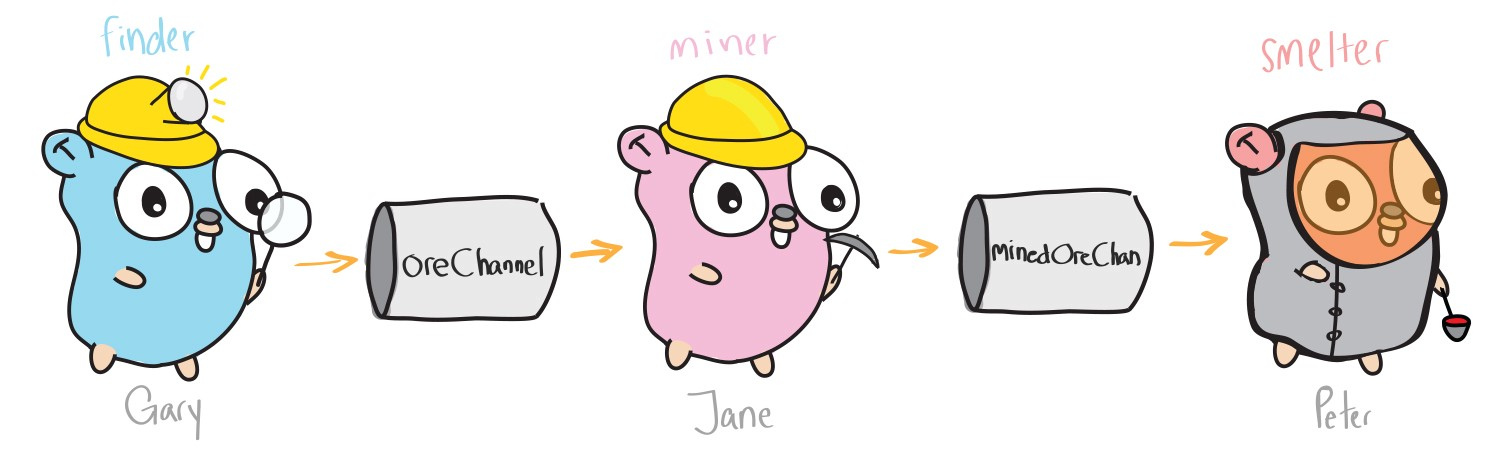
theMine := [5]string{"rock", "ore", "ore", "rock", "ore"} oreChannel := make(chan string) minedOreChan := make(chan string)
Such a program will output the following:
From Finder: ore From Finder: ore From Miner: minedOre From Smelter: Ore is smelted From Miner: minedOre From Smelter: Ore is smelted From Finder: ore From Miner: minedOre From Smelter: Ore is smelted
Compared to our first example, this is a major improvement; now all functions are performed independently, each in its own mountain. And also we have a conveyor of channels through which ore is transferred immediately after processing. To keep the focus on the basic understanding of the work of channels and gorutin, I dropped some points, which can lead to difficulties with the launch of the program. In conclusion, I want to dwell in greater detail on these features of the language, as they help in working with the channels and channels.
Anonymous gorutiny

Just as we start a regular function in gorutin, we can declare an anonymous function immediately after the
go keyword and call it using the following syntax:
Thus, if we only need to call a function in one place, we can run it in a separate gorutin, without worrying in advance about its declaration.
The main function is gorutina.

Yes, the
main function really works in its own mountain. And, more importantly, after its completion, all other Gorutinas are also completed. It is for this reason that we placed a timer call at the end of our
main function. This call creates a channel and sends data to it after 5 seconds.
<-time.After(time.Second * 5)
Remember that Gorutina will be blocked when reading from the channel, until something is sent to it? This is exactly what happens when you add the specified code. The main gorutina is blocked, giving other gorutiam 5 seconds of time to work. This method works well, but, usually, a different approach is used to verify the completion of all gorutin work. To transmit a signal about the completion of work, a special channel is created, the main gorutin is blocked from reading from it and, as soon as the subsidiary gorutina completes its work, it records in this channel; the main gorutin is unlocked and the program ends.

func main() { doneChan := make(chan string) go func() {
Reading from a pipe in a for-range loop
In our example, in the function of the earner gopher, we used a
for loop to select three elements from the channel. But what to do if it is not known in advance how much data can be in the channel? In such cases, you can use the channel as an argument for the
for-range loop, as well as with collections. The updated feature might look like this:
Thus, the ore miner will read everything that the scout will send him, the use of the channel in the cycle is guaranteed. Note that after all the data from the channel has been processed, the cycle will be blocked on reading; To avoid blocking, you need to close the channel by calling
close (channel) .
Non-blocking channel reading
Using the
select-case construct, you can avoid blocking reads from the channel. Below is an example of using this construction: Gorutin will read data from the channel, if only they are there, otherwise the
default block is executed:
myChan := make(chan string) go func(){ myChan <- “Message!” }() select { case msg := <- myChan: fmt.Println(msg) default: fmt.Println(“No Msg”) } <-time.After(time.Second * 1) select { case msg := <- myChan: fmt.Println(msg) default: fmt.Println(“No Msg”) }
After launch, this code will output the following:
No Msg Message!
Non-blocking channel recording
Locks when writing to a channel can be avoided by using the same
select-case construct. Let's make a small edit in the previous example:
select { case myChan <- “message”: fmt.Println(“sent the message”) default: fmt.Println(“no message sent”) }
What to study next

There are a large number of articles and reports that cover the work with channels and gorutines in much more detail. And now, when you have a clear idea of why and how these tools are used, you can get the most out of the following materials:
Thanks for taking the time to read. I hope that I have helped you to understand the channels, gorutinami and the benefits that give you a multi-threaded program.