
What is the difference between Machine Learning and data analysis, who is sitting in Odnoklassniki and how to start your journey in machine learning - we talk about this in the twelfth issue of talk shows for programmers.
Video on the channel TehnostrimThe host of the program is the technical director of media projects Pavel Scherbinin, the guest is the analyst at Odnoklassniki, Dmitry Bugaychenko.
00:56 Dmitry Bugaychenko: from outsourcing to OC and scientific activities
02:42 Why combine work at the university and in a large company
02:57 Where machine learning is used in OK
03:49 Machine learning and data analysis - what's the difference?
05:08 Screencast "We understand the audience OK using data analysis"
22:34 Are classmates a dating service?
24:07 How to start learning Machine Learning?
25:33 Should we participate in machine learning championships?
26:53 How to get to practice in OK
28:18 Handbook for machine learning
30:28 Machine Learning Events
32:48 How does the data pipeline in OK (shown on the board)
43:42 Survey
Tell me something about yourself.It can be considered that my career path began in 1999, when I entered mathematics. For five years, he actively studied mathematics, programming, and various related disciplines. Then he worked for a long time in an outsourcing company. Outsourcing is a very interesting experience. I managed to work in a wide variety of projects, from writing a driver for a refrigerator to creating distributed enterprise systems.
All this time, in addition to the main work, I taught at the university in order to maintain contact with the academic community, which was difficult enough. When in 2011 I was invited to Odnoklassniki to engage in recommender systems, it was a very good chance that I used. Here it is possible to combine both the mathematical preparation of the university and the practical programming experience. However, I continue to teach at the university.
Does teaching take a lot of time?1.5 days a week goes to the university, but it's worth it, because we already have three former students in our staff. That is, the university works as a forge of personnel.
At work, calmly refer to the fact that you are not 1.5 days?Humbled Everyone understands what a profit from this, so I do not meet with opposition.
Tell us where machine learning is used in Odnoklassniki.We have a lot of applications. Historically, the first system based on machine learning was the recommendation of music. It all started in 2011. Then there was just explosive growth: the recommendation of the communities, the recommendation of friends, “perhaps you are familiar,” attempts to rank the content in the person’s feed. Now a lot of projects are being developed. In what part of "Odnoklassniki" do not push, everywhere there are components associated either with machine learning or with data analysis.
Help our readers to separate these two concepts: machine learning and data analysis.The data is analyzed by a person in order to find any patterns, relationships, test some hypotheses. For this, different means of mathematical statistics are used. Machine learning is a more advanced way of finding patterns, which uses techniques based on, as a rule, a large, complex model with a large number of parameters.
We are trying to select the parameters of this model so that it describes well the phenomenon that we need. There are many different algorithms, methods for iterating over parameters, but all this is done in order to find some regularity. For example, according to data about a post in a social network, assess the probability that a particular person will put a “class” on this post. That is, machine learning is a tool for data analysis.
You and I could have debunked one of the myths about “Classmates”, according to which there is a very old audience in this social network?No problem. This is a map that in real time reflects the logins of each specific user. That is, each point is a person who logged in and does something in Odnoklassniki.
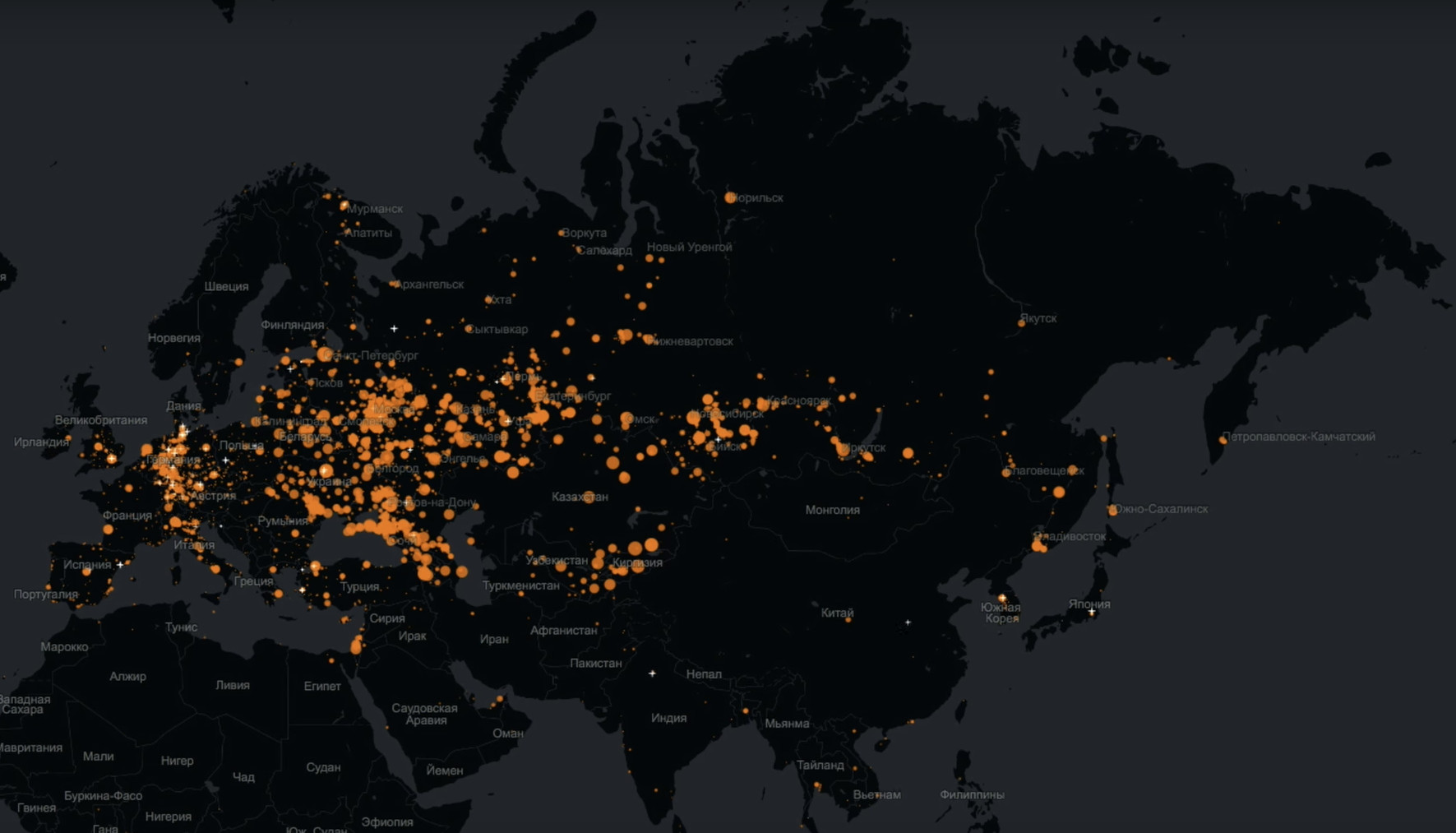
Big red circles are cities from which many users came to us. It is very clearly seen here that the “Classmates” are not just alive, they cover almost the whole of Eurasia.
We calculate how many users yesterday put the "class" in "Classmates", and see the distribution by age.
How to start writing code? Of course, with the import of various useful data for the future calculation of aggregates. Our main tool is
Spark , for access to which we use the
Zeppelin web front. Basically, the data comes through
Apache Kafka , added up in packets and broken into different blocks. In this case, we are interested in a block that describes the activity of users for yesterday, in particular, classes. There is a field in which the demographics of users are stored, including birthdays.

At the exit we get the year of birth of the first ten entries. Now we will try to build from this some aggregate. We want to count the number of unique users. Looking for id and year of birth, grouped by year and count the number of unique users. And a little heck on it: for sure there will be people whose year of birth is not specified, so we will filter them so that we do not create noise on the chart.
To make the calculation, the system needs to shovel about 1 TB of data. We get the result and present it graphically:

The age peak occurs in 1983 - 35 years. That is quite a not old users.
To more fully represent the situation, not enough information from one source. If we are talking about the demographics of users, then the most interesting source for comparison is the statistics on the population of Russia. From the
Rosstat website, I downloaded data on the years of birth of Russians, collected in 2016.
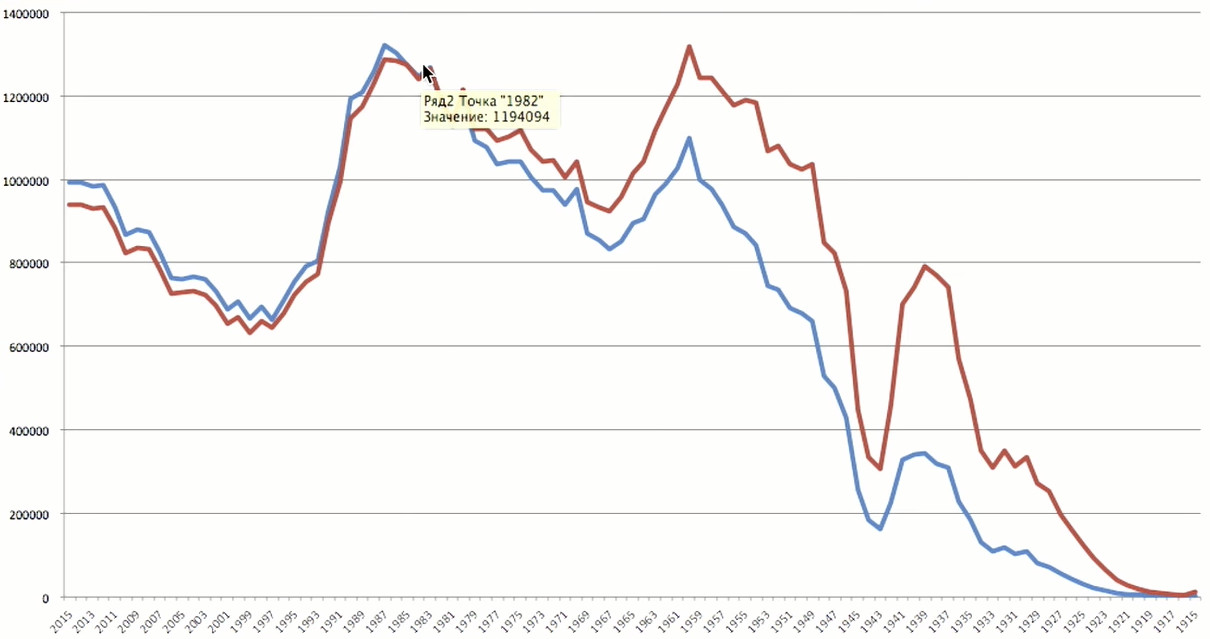
The peak in statistics is very close to the peak according to Odnoklassniki - we have users born in 1983, and Rosstat in 1987. What struck me, these are two big failures. The pit of the early 1940s is the Great Patriotic. The war cost us not only more than 20 million dead, but also millions of unborn people. This is a demographic hole, which is still felt. The second pit is the 1990s. And we have not fully recovered from this crisis. We see the same picture in the Odnoklassniki data: after 1990, there was a strong decline. We still cannot have people born in 2015, because the minimum age of registration is 5 years.
Add a gender attribute to our sample and group it not only by year, but also by gender.
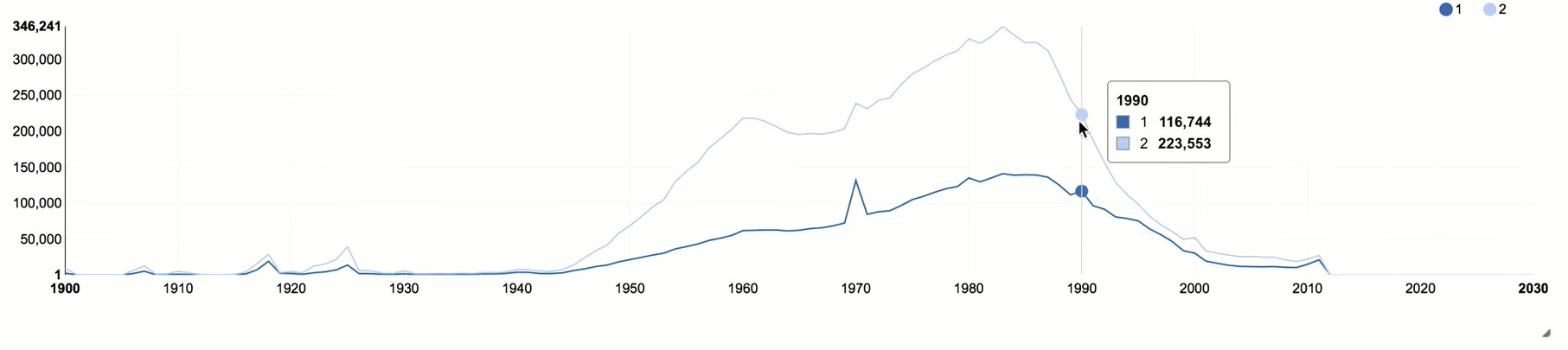
After 1990, there is a sharp decline, which correlates with the general age situation in Russia. Women put the “class” much more actively, almost twice as many as men. This is quite a characteristic picture for social networks, because women are more socially active than men.
You can also pay attention to several peaks that correlate with the "round" years. These peaks can be used to estimate the influence of bots or people who deliberately distort their age, because in such cases some round dates are most often indicated.
We are also interested in the geographical distribution of our users. We need a user ID to count unique visitors, and the residence addresses specified in the profiles. Group by city and calculate the unit. Sort by the number of users in descending order and leave only the first 200 cities. We start aggregation:

This is the top cities in the number of class members who use Odnoklassniki. Naturally, Moscow is in the lead. South of Russia is represented much better than the North-West. We have users in the USA, Canada, a lot in Germany, a lot in Israel. Interesting fact: 36 thousand people from Yuzhno-Sakhalinsk liked the day. And just in the city, according to Wikipedia, 180 thousand people live. 20% of the population of Yuzhno-Sakhalinsk entered Odnoklassniki and put a “class”.

Increase the scale and see what happens in Moscow and the Moscow suburbs.

Very well represented in the "Classmates" Central Asian republics, Moldova, Ukraine.

We immediately see where they tried to block access to our social network, and where not.
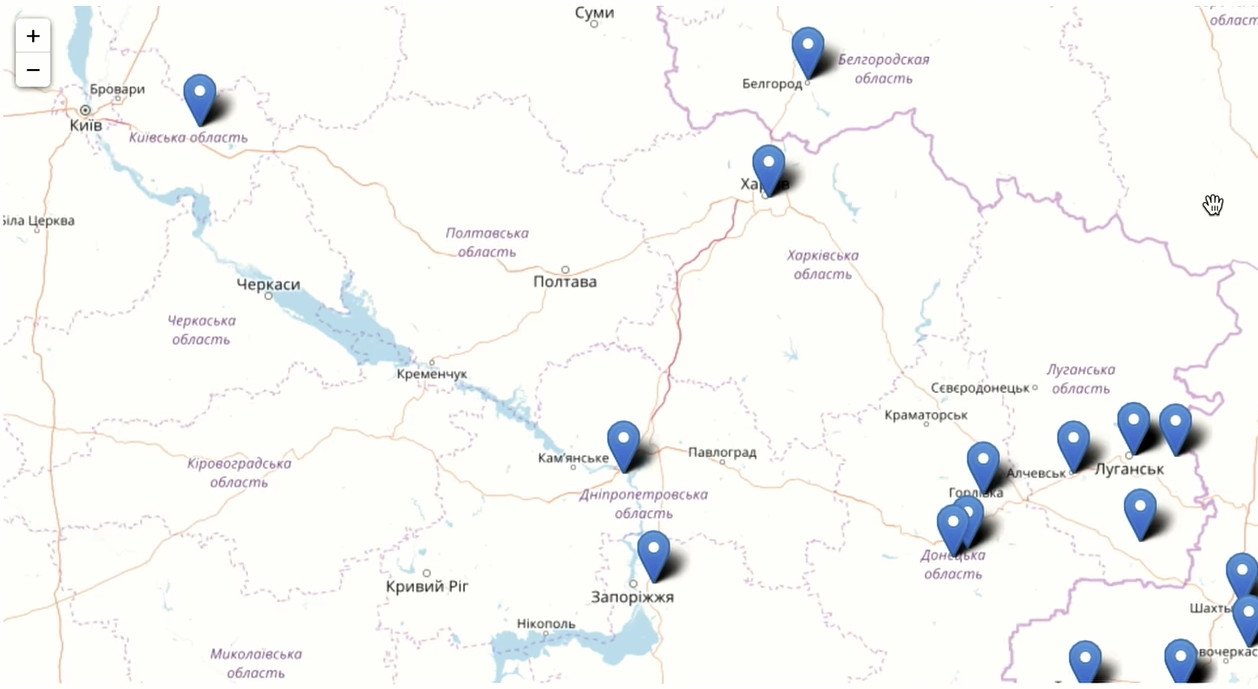
As you can see, Odnoklassniki is a living, dynamic product that is used by young people and older people all over the world, sometimes even where you don’t expect. Among all age categories, we have the most 30-year-olds.
Social networks are built around communities. It often happens that if a community is included in a certain social network, it knows very little about other social networks. Therefore, for example, the professional community of journalists may experience the illusion that Odnoklassniki is mainly an elderly audience. In fact, this is a subjective opinion of a community. We have users aged 50–60 years and older, there are schoolchildren, there are 20-year-old youth, there are mature, matured people 30–35 years old.
Coverage "Odnoklassniki" - this is all regions of Russia, CIS countries, Ukraine, Belarus, Central Asia. We have a very well represented diaspora, for example, the German diaspora of Russian emigrants, the American diaspora, the Israeli. They are quite actively communicating with their relatives who remained in Russia and the former Soviet republics. From this point of view, Odnoklassniki very well contribute to the implementation of the basic function of a social network - to maintain contacts between people living far from each other.
There is an opinion that "Classmates" are so attractive to many because it is an easy way to meet friends and acquaintances of your friends and relatives. That is, Odnoklassniki is presented as a dating service. How much is this way of dating in demand and part of the Odnoklassniki ideology?The need to meet other people, including the opposite sex, is a basic human need. Naturally, it is expressed in any social network. But in Odnoklassniki it is expressed no more and no less than in other social networks. We have no emphasis on dating services. The ideology of the development of our social network is built on such a common value as the communication of people. We are not so important, whether it will be classmates who have traveled to different cities, or people who are looking for a mate. Both options are fine with us. We are glad that people found each other and communicate. But no more than that
You do a lot of machine learning. This topic now excites many. How to start, how to come to this profession?First, you need to get some knowledge. There are no problems with this, there are wonderful courses on
Coursera , on
Stepik and in some university programs that provide very good basic knowledge of machine learning. To really join this sphere, you need a goal and an understanding of where you can apply it. Because simply listening to an abstract course is not nearly as effective as if you are really going to solve a certain problem or problem.
In the case of students, the ideal option is term papers, theses. And even in this case, I try not to lower the task from above, but to encourage the ideas to come from the students, then they will have much more motivation.
That is, setting a goal for yourself, listen to online courses, and then try to apply knowledge. And everything will turn out.
It seems to me that there are enough tasks today. A large number of competitions from Sberbank, Tinkoff and many other companies are taking place on the Point.Of course. But they are focused primarily on those who are already closely engaged in machine learning. In this case, very often at such competitions, one can observe not machine learning, but hats and caps. Those models that are trained in Flanges will not help in solving practical problems, because they are driven into too many parameters. As a result, the models specialize specifically for specific competitions on the Flander, and only in them do they produce any results. And if you transfer these models to the real world, they will not work.
The best experience is practice. How to get practice with your team?There are so many ways. If we talk about research teams, then we have a project called OK Data Science Lab, within which we provide computing resources, data, our knowledge and experience to people who want to develop their ideas related to machine learning and data analysis. And not necessarily for a social network. For example, we have a study in which the author tries to understand what is most interesting for modern schoolchildren.
If you are a specialist and are looking for a job, we always have a lot of open vacancies related to machine learning. Come to us for an interview.
Is there any book reader for machine learning?This is a field that is changing so fast that writing a book or a textbook on machine learning is too ambitious. I can advise the classic work “
Elements of statistical training ”. This is about the most basic methods of machine learning, originating in statistics.
Sergey Nikolenko has published a book on deep machine learning.In my opinion, deep learning is not something to start with. If you already own classic machine learning, then this is a good option. But if you don’t yet know the classic tricks, it’s wrong to start right away with deep learning, because it often removes the researcher from the problem, it’s a very powerful tool. Before applying it, it is necessary to analyze the problem "manually" in more simple ways. And only then, with the understanding of the subject area, move on to in-depth learning. Otherwise, your model will learn, and you - no. When you become more stupid than your model, it is, to put it mildly, ineffective. You will not be able to develop the model further, and this is a dead end. Therefore, it is better to first become skilled in the classic ML. This does not mean that you need to spend years, it is quite possible to master in a reasonable time.
Do you have any machine learning events?We have a series of hackathons
SNA Hackathon . While passed two times. For the first time, the hackathon was devoted to analyzing the text and trying to predict how many “classes” a certain post will accumulate. The second hackathon passed a year ago and was devoted to graph analysis. Many interesting things happened there. We provided information about the "friendships" of a part of our users, a seemingly small piece of data of about 1 GB. But when the participants who wanted to send their predictions, tried to work with him, almost no one did it, even on machines with 16 and 32 GB of memory everything collapsed, flew into a swap, did not want to work at all. We even had to hastily explain how to do it and how not to work with the data.
It turned out that very many, even quite advanced machine learning specialists had come off the roots and began to forget the basic basics of programming. Forget what boxing is, how hash tables are arranged, what kind of memory overhead can be if you use hash tables. If you do not think about all this and do it in the forehead in Python, Java or Scala, there will be problems described. We made a demo in Python, the same rake is in other languages. A graph of 40 million connections, which could fit in 200 MB of memory, explodes sharply by 20 GB simply because you forgot how the basic data structures are organized. It was very impressive at that time. Even if you are an expert in machine learning, the basics of programming can not be forgotten.
How is your data processing workflow?Users interact with the whole ecosystem of our products. Conventionally, there are two levels: front-end applications (mobile applications, portal, mobile version, various additional applications) and business logic. Fronts often interact with users and have access to a very limited number of servers, so business logic has some special techniques that allow fronts to log data.
This data falls into a single Apache Kafka data bus. This is the turn that has become practically an industry standard that is used to collect raw data. Naturally, raw data is difficult to analyze in Kafka, so they are regularly transferred to the big and thick Hadoop. Some may say that Hadoop is the last century, now Spark is driving. But Hadoop is a platform where you can run a lot of tools. We have various analytics tools spinning over Hadoop. I often resort to this classification:
- Style data entry .
- Batch processing. There is some amount of data that you somehow process.
- Stream processing. You work with real-time data that comes directly from streams, in this case from our Kafka.
If during batch processing there can be quite serious delays - they collected statistics during the day, and you teach the model at night, then in the case of stream processing, delays are measured in units of seconds between the arrival of data and their processing.
- Operating analytics . This is process control and monitoring. Serves production, must work itself, without human intervention.
- Interactive analytics . What a person does. Here the speed of the reaction is important: they did something, got the result.
In each of these niches we have our own ecosystem of products. For example, batch operational analytics mainly uses classic MapReduce, Apache Tez, and a little Spark. If we are talking about interactive batch analytics, then this is Spark SQL and the scripting languages Pig and Hive.
Of course, there is no clear line, because some interactive languages are often used for operational batch analytics. Apache Samza. LinkedIn. 2014 . , Spark Streaming, -.
- production, . , Kafka, . Kafka — , , . , Kafka , Streaming Index. Kafka : Casandra , SMC.
, , 99 %. - Streaming Index, . , , , «» , . , .
, , -. ?Mac.
IDE?Idea.
: ?Startup
Why?, .
, IT- 10 ?, .
?: , . , , , .
?, . . , , . , , .
, . «»?, : «».
?, .
?Yes.
Why?Technology.