
Today, CERN is one of the largest Kubernetes users in the world. According to recent statistics, this European organization behind the Large Hadron Collider (LHC) and a number of other well-known research projects, launched 210 K8s clusters, serving the simultaneous execution of hundreds of thousands of tasks. This success story is about them.
CERN containers: start
For those who are at least superficially familiar with the activities of CERN, it is not a secret that this organization pays a lot of attention to current information technologies: it’s enough to remember that this is the birthplace of the World Wide Web, and among the more recent merit you can remember the grid systems (including
LHC Computing Grid ), a specialized
integrated circuit , a
Scientific Linux distribution, and even
its open hardware
license . As a rule, these projects, be they software or hardware, are connected with the main brainchild of CERN - BAK. This also applies to the CERN IT infrastructure, which largely serves its own needs.
 At the CERN data center in Geneva
At the CERN data center in GenevaThe earliest publicly available information about the practical use of containers in the organization’s infrastructure, which was found, dates from April 2016. As part of the “
Containers and Orchestration in the CERN Cloud ” internal report,
CERN employees described how they use the OpenStack Magnum
(an OpenStack component to work with container orchestration engines) to provide support for containers in their cloud (CERN Cloud) and their orchestration. Even then, mentioning Kubernetes, the engineers sought to be independent of the chosen orchestration tool, supporting other options: Docker Swarm and Mesos.
Note : The cloud itself with OpenStack was introduced into the production-infrastructure of CERN a few years before, in 2013. As of February 2017, 188,000 cores, 440 TB of RAM were available in this cloud, 4 million virtual machines were created (of which 22,000 were active).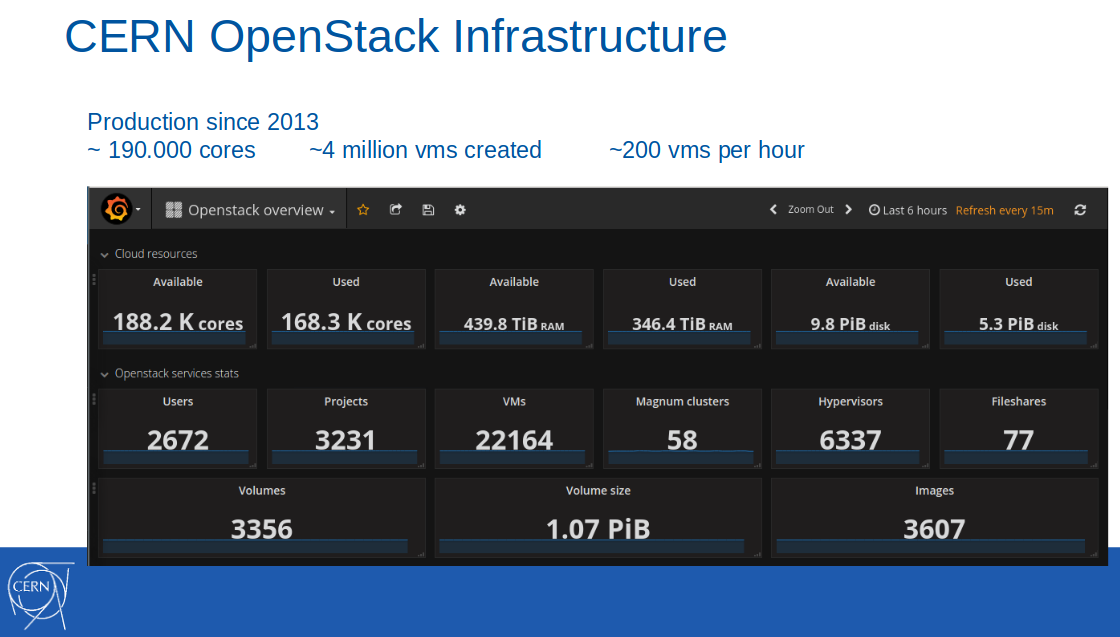
At that time, container support in the Containers-as-a-Service format was positioned as a pilot service and was used in ten IT projects of the organization. Among the application scenarios, continuous integration with GitLab CI for building and rolling out applications in Docker containers was called.
 From the presentation to the report at CERN of April 8, 2016.
From the presentation to the report at CERN of April 8, 2016.The launch of this service in production was expected by the third quarter of 2016.
Note : It should be noted separately that CERN employees invariably place their achievements in upstream used Open Source projects, including and numerous components of OpenStack, which in this case were Magnum, puppet-magnum, Rally, etc.Millions of queries per second with Kubernetes
As of June of the same (2016) year, the service at CERN still
had the status of pre-production:
"We are gradually moving to full production mode to include Containers-as-a-Service in the standard set of IT services available at CERN."
And then, inspired by the
publication in the Kubernetes blog about servicing 1 million HTTP requests per second without downtime during the update of the service in K8s, the engineers of the scientific organization decided to repeat this success in their cluster on OpenStack Magnum, Kubernetes 1.2 and the hardware base of 800 CPU cores.
Moreover, they decided not to limit themselves to a simple repetition of the experiment and successfully brought the number of requests to 2 million per second, simultaneously preparing several patches for the same OpenStack Magnum and performing tests with a different number of nodes in the cluster (300, 500 and 1000).
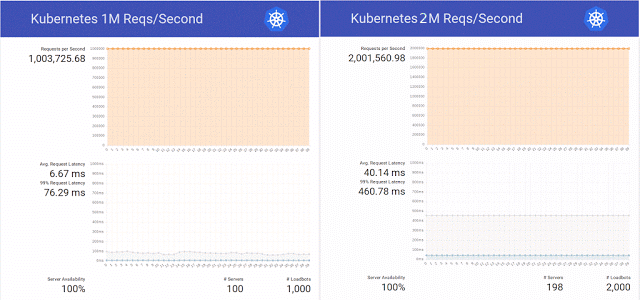
Summing up the results of this testing, the engineers again noted that "there is still Swarm and Mesos, and we plan to conduct tests on them soon." Whether it came to these tests, the Internet space is unknown, but by the end of the same year the experiment with Kubernetes
was continued - already with 10 million requests per second. The result was quite positive, but was limited to a successful mark of just over 7 million - due to a network problem unrelated to OpenStack.
Engineers specializing in OpenStack Heat and Magnum, at the same time, measured that cluster scaling from 1 to 1000 nodes took 23 minutes, regarding it as a good result
(see also the “ Toward 10,000 Containers on OpenStack ” performance at OpenStack Summit Barcelona 2016) .
Containers at CERN: transition to production
In February of the next (2017) year, containers at CERN were already widely used to solve problems from different areas: batch processing, machine learning, infrastructure management, continuous deployment ... This was revealed from the report “
OpenStack Magnum at CERN. Scaling container clusters to thousands of nodes ”(
video ) at FOSDEM 2017:

It also reported that the use of Magnum at CERN was transferred to the production stage in October 2016, and the support for three instruments for orchestration was again emphasized: Kubernetes, Docker Swarm and Mesos. Why it was so important,
explained at one of his speeches (OpenStack Summit in Boston, May 2017) Ricardo Rocha from the CERN IT department:
“Magnum also allows us to choose the container engine, which was very valuable to us. In the organization, there were groups of people who advocated Kubernetes, but there were also those who had already used Mesos, and some of them worked with the usual Docker, wanting to continue to rely on the Docker API, and there is a lot of potential for Swarm. We wanted to achieve ease of use, not to require people to understand complex patterns to customize their clusters. ”
At that time, CERN used about 40 clusters with Kubernetes, 20 with Docker Swarm and 5 with Mesosphere DC / OS.
A year later, by May 2018, the situation has changed significantly. From the performance of “
CERN Experiences with Multi-Cloud Federated Kubernetes ” (
video ) of the same Ricardo and his colleagues (Clenimar Filemon) on KubeCon Europe 2018, new details on the use of Kubernetes became known. Now it is not just one of the container orchestration tools available to users of a scientific organization, but also an important technology for the entire infrastructure that allows - thanks to the federation - to significantly expand the computing cloud by adding third-party resources (GKE, AKS, Amazon, Oracle ...) to its own capacities.
Note : Federation in Kubernetes is a special mechanism that simplifies managing multiple clusters by synchronizing their resources and automatically discovering services in all clusters. The actual case of its use is working with a variety of Kubernetes clusters distributed across different providers (their data centers, third-party cloud services).As can be seen from this slide, demonstrating some quantitative characteristics of the CERN data center in Geneva ...

... the organization’s internal infrastructure has grown dramatically. For example, the number of available cores for the year has almost doubled - already to 320 thousand. Engineers went further and combined several of their data centers, achieving the availability of 700 thousand cores in the CERN cloud, which are engaged in the parallel execution of 400 thousand tasks (event reconstruction, detector calibration, simulation, data analysis, etc.) ...
But in the context of this article, of greater interest is the fact that 210 Kubernetes clusters, whose sizes varied greatly (from 10 to 1000 knots), were already functioning at CERN.
Federation with Kubernetes
However, the internal capacities of CERN were not always enough - for example, for periods of sharp surges in load: before large international conferences on physics and in the case of large campaigns for the reconstruction of experiments being conducted. A notable use case, requiring large resources, was the CERN Batch Service (CERN) system, which accounts for about 80% of the total load on the organization’s computing resources.
This system is based on the
HTCondor open source
framework designed for solving problems of the HTC category (high-throughput computing). The StartD daemon is responsible for the calculations in it, which starts at each node and is responsible for starting the workload on it. It was he who was containerized at CERN for the purpose of launching on Kubernetes and further federation.
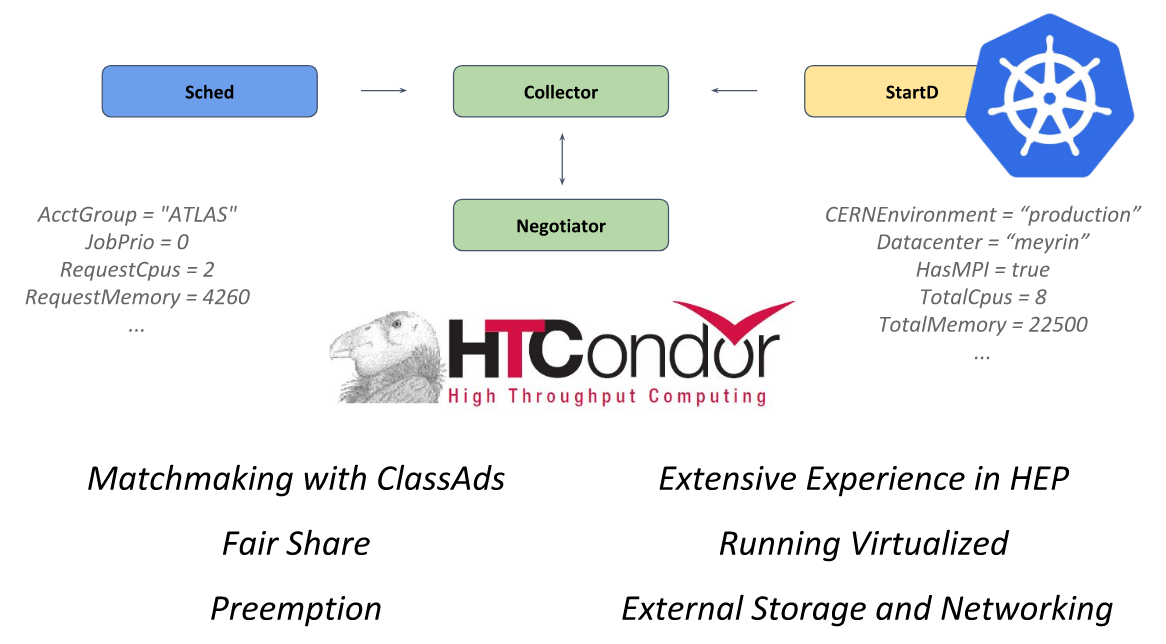 HTCondor from CERN presentation at KubeCon Europe 2018
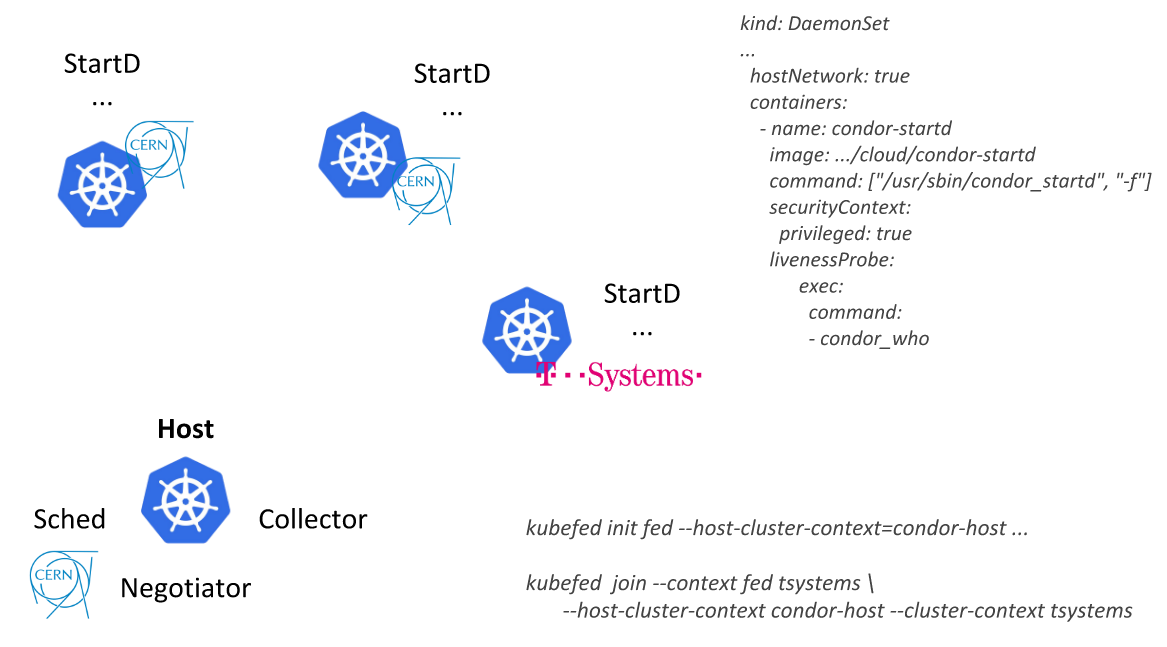
HTCondor from CERN presentation at KubeCon Europe 2018Having gone this way, CERN engineers were able to describe a single resource (
DaemonSet with a container where StartD from HTCondor is launched) and deploy it on the nodes of all Kubernetes clusters united by federation: first within its data center, and then connecting external providers (public cloud from T-Systems and other companies):
Another application example is an analytical platform based on
REANA ,
RECAST and
Yadage . In contrast to CERN Batch Service, which is the “well-established” software in the organization, this is a new development, which immediately took into account the specifics of the application with Kubernetes. Workflows in this system are implemented in such a way that each stage is converted to a
Job for Kubernetes.
If initially all these tasks were launched on a single cluster, then over time, requests grew and “today it is our best use case federation in Kubernetes”. Watch a short video with his demonstration in
this excerpt from Ricardo Rocha.
PS
Additional information on the current scope of IT application at CERN can be obtained on
the organization's website .
Other articles from the cycle